Arm Announces Neoverse V1, N2 Platforms & CPUs, CMN-700 Mesh: More Performance, More Cores, More Flexibility
by Andrei Frumusanu on April 27, 2021 9:00 AM EST- Posted in
- CPUs
- Arm
- Servers
- Infrastructure
- Neoverse N1
- Neoverse V1
- Neoverse N2
- CMN-700
Eventual Design Performance Projections
Alongside the ISO-process node IPC, power and area projections, Arm also made projection of possible eventual implementations of the V1 and N2. These would naturally no longer be ISO-process, but the company’s expectations of what actual possible products might end up as in future designs.

The most important slide and disclosure in this regard is the fact that a Neoverse N2 design on TSMC’s 5nm is expected to achieve the same power as well as the same area as a TSMC 7nm Neoverse N1 design today.
In general, that’s a relatively large presumption, but could possibly pan out if the vendors are able to achieve a good implementation. We don’t have too many details as to the 7nm node generation of Amazon’s or Ampere’s current N1 chips, but I would assume that they’re baseline N7 – at least similar to that of what AMD uses in their EPYC 7002 and 7003 chips.
Still, a -40% power reduction from N7 to N5 is a very high goal and assumption to make. The only N5 chips we’ve had in-house to date, the Kirin 9000, and Apple A14, showcased only a rough 10% efficiency advantage over their N7P predecessors. N7P being roughly 15% better than N7, that’s still only somewhat 26% better efficiency.
Arm expects that the current generation N1 implementations to day to not have fully achieved their potential as it was the vendor’s first attempt with the IP. Arm expects that the following generations with more experience, better implementations with for example more metal layers, to be able to squeeze out more performance and power efficiency on the N5 node.
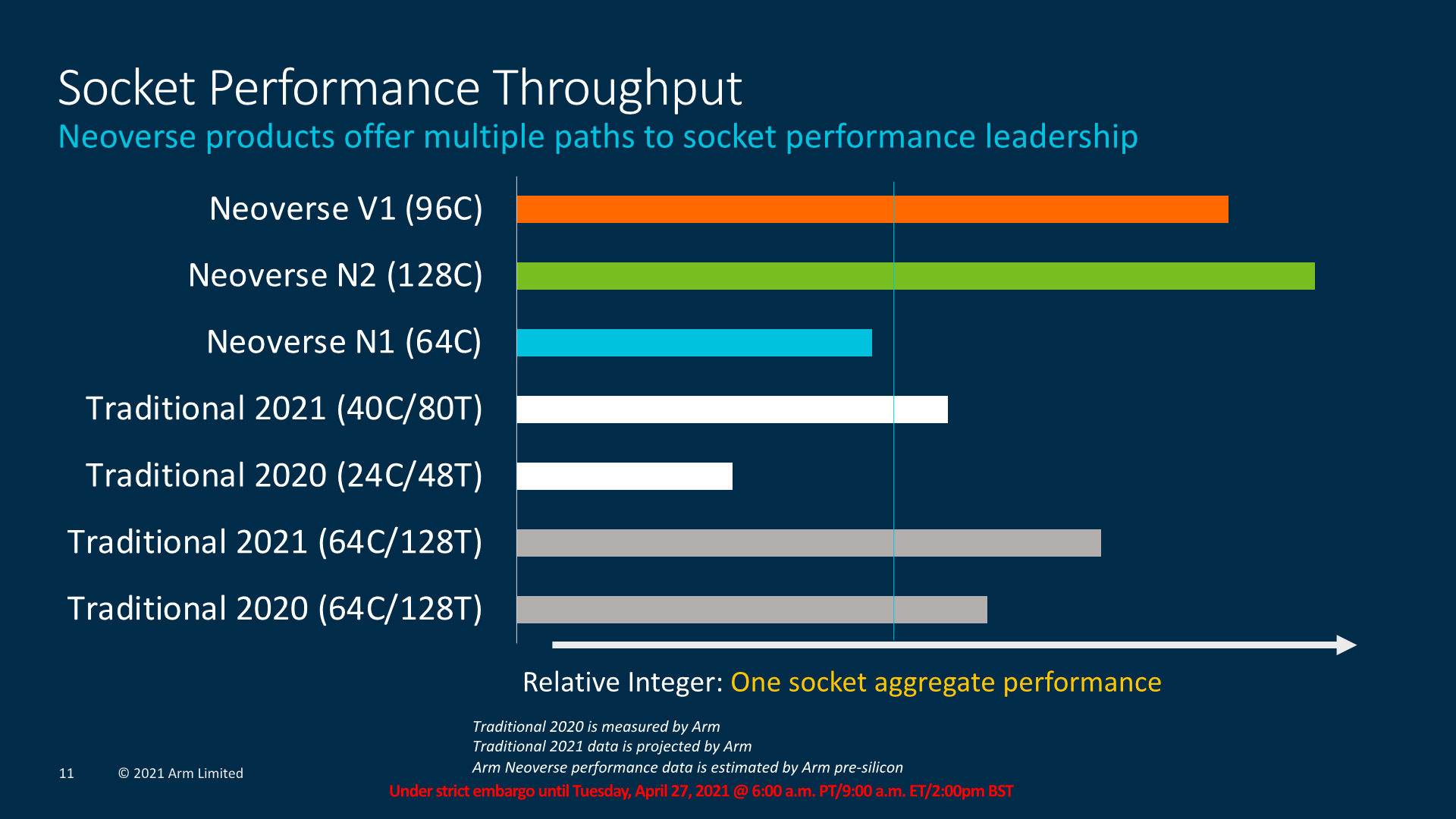
In terms of socket performance, Arm is expecting some very large generational gains versus a 64C N1 product today – it’s to be noted that these are Arm pre-silicon figures and not the Graviton2.
The “Traditional 2020” chips are the 24C Xeon 8268 and the 64C EPYC 7742. I would ignore the “Traditional 2021” parts here – Arm was aiming and estimating the performance of Intel’s newest 40C Ice-Lake and 64C Milan, however the presentation and figures here were integrated before AMD and Intel actually launched those systems – we have actual benchmark numbers in a custom graph below.


One metric Arm was focusing on was per-thread performance, where the “traditional” cores from AMD and Intel are falling short of the performance of Arm’s Neoverse cores.
Arm here is being somewhat sneaky in their presentation as they are trying to only focus on per-thread performance in cloud environments, where typically things operate on a vCPU basis, and essentially SMT-enabled designs from AMD and Intel naturally fall behind quite a lot in per-thread performance.
I can’t really blame Arm for depicting the performance figures like this – the cloud vendors today don’t really differentiate between real cores and SMT cores in vCPU environments, even having pricing that’s arguably unfair to SMT-enabled designs, which is why we’ve deemed Amazon’s Graviton2 m6g instances to vastly outperform AMD and Intel instances in terms of perf/W and perf/thread.

I wasn’t happy with Arm’s slides not including 1 thread per core performance figures for the SMT systems, so I included my own chart based on actual measured performance figures on the various platforms. The V1 and N2 figures use Arm’s performance scaling versus the Neoverse N1 datapoint, and I’ve baselined that to the Graviton2 scores we’ve measured earlier last year. Arm uses the same compiler flags as we do and also GCC 10.2, so the scores should also be compatible – with the only discrepancy being that Arm used 2MB page sizes.
The Neoverse V1 system uses 96 cores at 2.7GHz with 1MB L2 per core, on a 128MB 2GHz mesh, with 8 DDR5-4800 memory controllers. The N2 datapoint uses 128 3GHz cores at 1MB per L2, 96MB 2GHz mesh, with 10 DDR5-4800 memory controllers.
Arm’s per-thread performance lead doesn’t look that great here when looking at the 1T/C figures of AMD and Intel, but admittedly when in a vCPU scenario, Arm’s design would vastly outperform the SMT chips.
Generally speaking, the performance figures look good when it comes to per-socket performance, but generally that’s to be expected given the new 5nm process node and the more advanced memory controller technology in the projected figures.
AMD's next-generation Genoa should feature more massive performance jumps through the adoption of N5, DDR5, and transition away from their 14nm IO die. IPC and core count increases should also close the gap that’s depicted today. Intel’s next generation Sapphire Rapids should also improve the situation – albeit how that ends up depends on how much they’ll be able to squeeze out of 10nm SuperFin node in relation to what we’ve seen a few weeks ago on Ice Lake-SP.
Usually, I’m more open to Arm’s performance projections, however this time around the V1 and N2’s performance projections are extremely optimistic, especially since they’re completely dependent on the vendors achieving good implementations on N5 and actually reaching the projected 40% perf/W process node and implementation power efficiency gains. Based on what I’ve seen in the mobile space, I remain quite sceptical, and will be adopting a wait & see approach this time around.








95 Comments
View All Comments
nandnandnand - Tuesday, April 27, 2021 - link
Looking at Cortex-X-next. It seems like Arm can put out a new Cortex-X for every new Cortex-A78 successor, since the Cortex-X is very similar but bigger.mode_13h - Tuesday, April 27, 2021 - link
Form an earlier article:> The Cortex-X1 was designed within the frame of a new program at Arm,
> which the company calls the “Cortex-X Custom Program”.
> The program is an evolution of what the company had previously
> already done with the “Built on Arm Cortex Technology” program
> released a few years ago. As a reminder, that license allowed
> customers to collaborate early in the design phase of a new
> microarchitecture, and request customizations to the configurations,
> such as a larger re-order buffer (ROB), differently tuned prefetchers,
> or interface customizations for better integrations into the SoC designs.
> Qualcomm was the predominant benefactor of this license,
Alistair - Tuesday, April 27, 2021 - link
I just want to be able to use ARM in standard DIY with an Asus motherboard and a socket, just like AMD and Intel.mode_13h - Tuesday, April 27, 2021 - link
I wonder if Nvidia will put out a Jetson-style board in something like a mini-ITX form factor.Alistair - Wednesday, April 28, 2021 - link
i sure hope so, and something not massively overpriced like right nowmode_13h - Thursday, April 29, 2021 - link
Yeah, because Nvidia is known for their bargain pricing!; )
Although, if they wanted to create a whole new product segment, it's conceivable they might keep prices rather affordable for a couple generations.
nandnandnand - Wednesday, April 28, 2021 - link
I want it. You want it. Some people seem to want it. Maybe demand is forming? Get on it, China.16-core Cortex-X2 please.
mode_13h - Wednesday, April 28, 2021 - link
They already did, sort of. See: https://e.huawei.com/us/products/servers/kunpeng/k...Whoops! Had to get this out of Google cache, because the page 404'd:
Board Model D920S10
Processors 1 Kunpeng 920 processor, 4/8 cores, 2.6 GHz
Internal Storage 6 SATA 3.0 hard drive interfaces, 2 M.2 SSD slots
Memory 4 DDR4-2666 UDIMM slots, up to 64 GB
PCIe Expansion 1 PCIe 3.0 x16, 1 PCIe 3.0 x4, and 1 PCIe 3.0 x1 slots
LOM Network Ports 2 LOM NIC, supporting GE network ports or optical ports
USB 4 USB 3.0 and 4 USB 2.0
mode_13h - Tuesday, April 27, 2021 - link
Do any of the current x86 cores pair up SSE operations for >= 4x throughput per cycle?AVX2 has been around for long enough that a lot of the code which could benefit from it has already been written to do so, yet *most* people are still compiling to baseline x86-64 (or just above that), since Intel is still making low-power cores without any AVX. So, I'm sure there's still *some* code that could benefit from >= 4x SSEn execution.
AntonErtl - Wednesday, April 28, 2021 - link
Zen has 4 128-bit FP units (2 FMA and 2 FADD). Not sure if that's what you are interested in.