Amazon's Arm-based Graviton2 Against AMD and Intel: Comparing Cloud Compute
by Andrei Frumusanu on March 10, 2020 8:30 AM EST- Posted in
- Servers
- CPUs
- Cloud Computing
- Amazon
- AWS
- Neoverse N1
- Graviton2
Cost Analysis - An x86 Massacre
The Graviton2 showcased that it can keep up extremely well in terms of performance and throughput, even beating the competition in a lot of the tests. However sometimes you don’t care too much about performance, and you just want to get some workload completed in the cheapest way possible, at which point value comes into play.
Amazon does allude to that, stating that the new chip is able to achieve 40% better performance per dollar than its competition. As covered in the introduction, for the 64-vCPU count 16xlarge instances the m6g (Graviton2), m5a (EPYC1), and m5n (Xeon Cascade Lake) are priced at an hourly cost of $2.464, $2.752 and $3.808 respectively.
Translating the time to completion of our various SPEC tests to hours and multiplying by the hourly cost, we end up with a cost per fixed workload metric:

An aggregate of all workloads summed up together, which should hopefully end up in a representative figure for a wide variety of real-world use-cases, we do end up seeing the Graviton2 coming in 40% cheaper than the competing platforms, an outstanding figure.
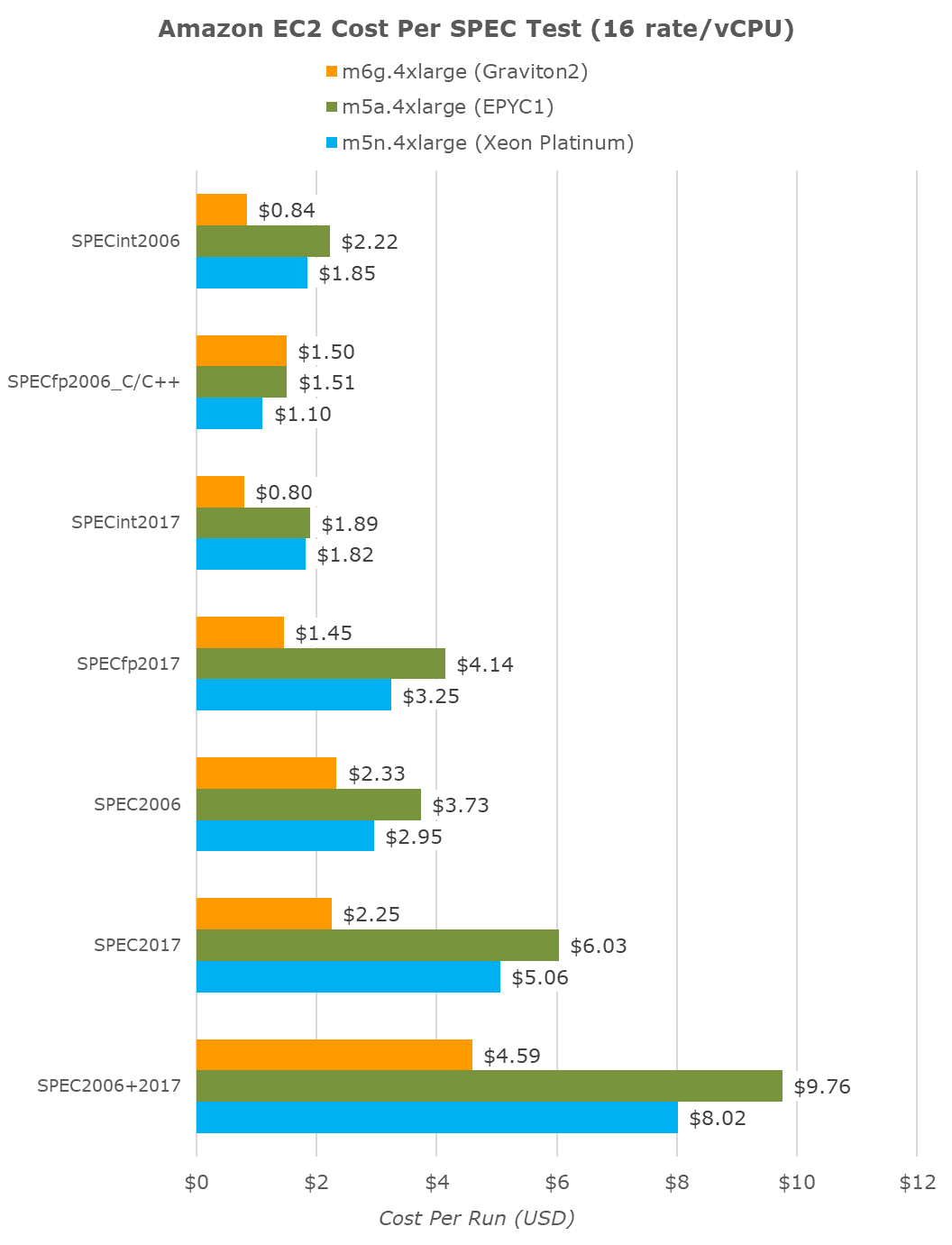
If we were to compare the same fixed workload at smaller instance counts, because of Graviton2’s better per-thread performance, we’re seeing even better results on 4xlarge (16 vCPUs) instances. Here the Amazon chip showcases 43% better value than the Xeon chip, and beats the AMD instances by being 53% cheaper.
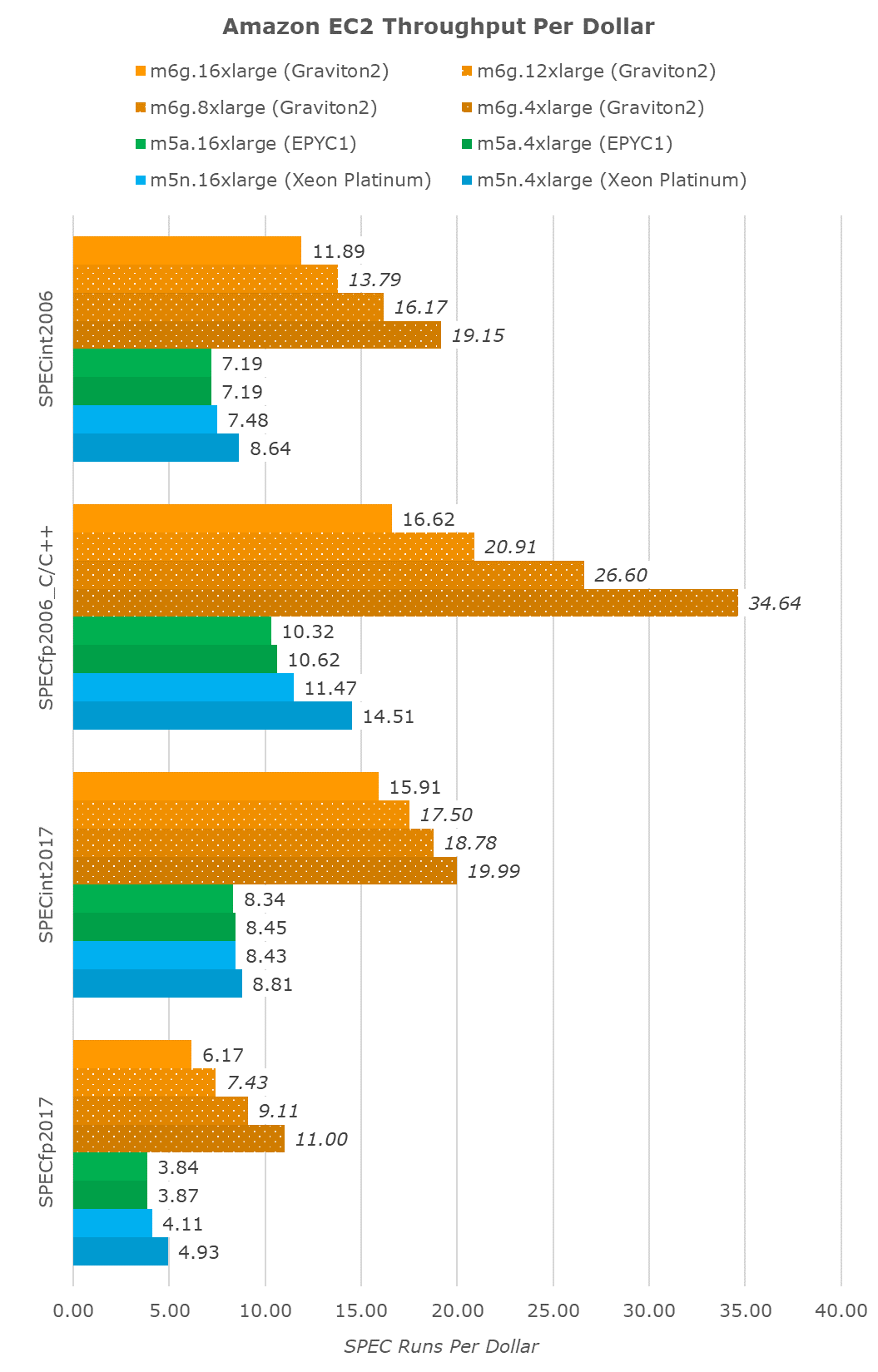
If we were to transform the results into a fixed throughput per dollar metric, we again see the Graviton2 far ahead. The unit here is SPEC runs per dollar.
The lower the vCPU instance size, the better value the Graviton2 seemingly becomes, as its performance with increased vCPUs scales sublinearly, but the cost of bigger vCPU instances scales linearly, an effect that’s almost not present at all in the AMD system, and only marginally present in the Xeon instances.
Again, the Graviton2’s scaling here might differ in production instances, but given that you can’t just chop off half the chip (or have access to only one of two sockets, in Intel’s case here) and that Amazon seemingly isn’t doing any static partitioning of the chip’s shared resources, I do think it’s more likely than not that such performance and value figures will be encountered in the real-world.
Even ignoring the lower vCPU instances, Amazon was able to deliver on its promise of 40% better performance per dollar, and it’s a massive shakeup for the AWS and EC2 ecosystem.








96 Comments
View All Comments
SarahKerrigan - Tuesday, March 10, 2020 - link
That single-thread performance is extremely impressive. The multithreaded scaling is ugly, though. Back when N1 was announced, ARM seemed to think 1MB/core was a good spot for Neoverse LLC - I wonder why both Graviton and Altra are going for considerably less.shing3232 - Tuesday, March 10, 2020 - link
it's gonna costly(die and power wise) to build a interconnect for 64C with good performance. by the time, it would lost its power/perf edge I suppose.Tabalan - Tuesday, March 10, 2020 - link
Scaling might not be optimal, but performance loses are to expected if you greatly reduce available cache. In the end, MT performance is still far ahead of competition.ballsystemlord - Thursday, March 12, 2020 - link
You have to remember that the competition is not 64 cores, but 64v cpus. The difference is 60% or more. The Arm Graviton2 is being placed into the best possible light by this comparision.ballsystemlord - Thursday, March 12, 2020 - link
I mean 60% for the cores that are actually 1 thread. As in, the performance boost by turning on SMT is 40% best case scenario.autarchprinceps - Sunday, October 25, 2020 - link
I have to disagree. You seem to forget that the arm chip is cheaper. It’s an additional win if it manages to integrate more cores and yet still achieve a comparable single threaded performance. It’s not unfair to compare two products with one seeming to have a stat advantage from the start, if it’s still cheaper or costs the same. Why should a customer care?zamroni - Thursday, March 12, 2020 - link
L caches uses sram which needs 6 transistors per bit.So, every 1MB needs all least 48 millions transistors without counting transistors for the controller
dianajmclean6 - Monday, March 23, 2020 - link
Six months ago I lost my job and after that I was fortunate enough to stumble upon a great website which literally saved me• I started working for them online and in a short time after I've started averaging 15k a month••• icash68.coMRallJ - Tuesday, March 10, 2020 - link
Comparisons made are to the whole core performance of Graviton to just thread performance of Xeon/EPYC. It's very problematic.Also TDP rating for the graviton is off by 50% based on what was reported at re:Invent.
Andrei Frumusanu - Tuesday, March 10, 2020 - link
I go over the core/SMT topic in the article, it's only a problem from a hardware comparison aspect, but it's very much the correct comparison from a cloud product offering comparison. The value proposition also does not change depending on core count, the instances are priced at similar tiers.