Intel’s Tiger Lake 11th Gen Core i7-1185G7 Review and Deep Dive: Baskin’ for the Exotic
by Dr. Ian Cutress & Andrei Frumusanu on September 17, 2020 9:35 AM EST- Posted in
- CPUs
- Intel
- 10nm
- Tiger Lake
- Xe-LP
- Willow Cove
- SuperFin
- 11th Gen
- i7-1185G7
- Tiger King
Comparing Power Consumption: TGL to TGL
On the first page of this review, I covered that our Tiger Lake Reference Design offered three different power modes so that Intel’s customers could get an idea of performance they could expect to see if they built for the different sustained TDP options. The three modes offered to us were:
- 15 W TDP (Base 1.8 GHz), no Adaptix
- 28 W TDP (Base 3.0 GHz), no Adaptix
- 28 W TDP (Base 3.0 GHz), Adaptix Enabled
Intel’s Adaptix is a suite of technologies that includes Dynamic Tuning 2.0, which implements DVFS feedback loops on top of supposedly AI-trained algorithms to help the system deliver power to the parts of the processor that need it most, such as CPU, GPU, interconnect, or accelerators. In reality, what we mostly see is that it reduces frequency in line with memory access stalls, keeping utilization high but reducing power, prolonging turbo modes.
Compute Workload
When we put these three modes onto a workload with a mix of heavy AVX-512 compute and memory accesses, the following is observed.
Note that due to time constraints this is the only test we ran with Adaptix enabled.
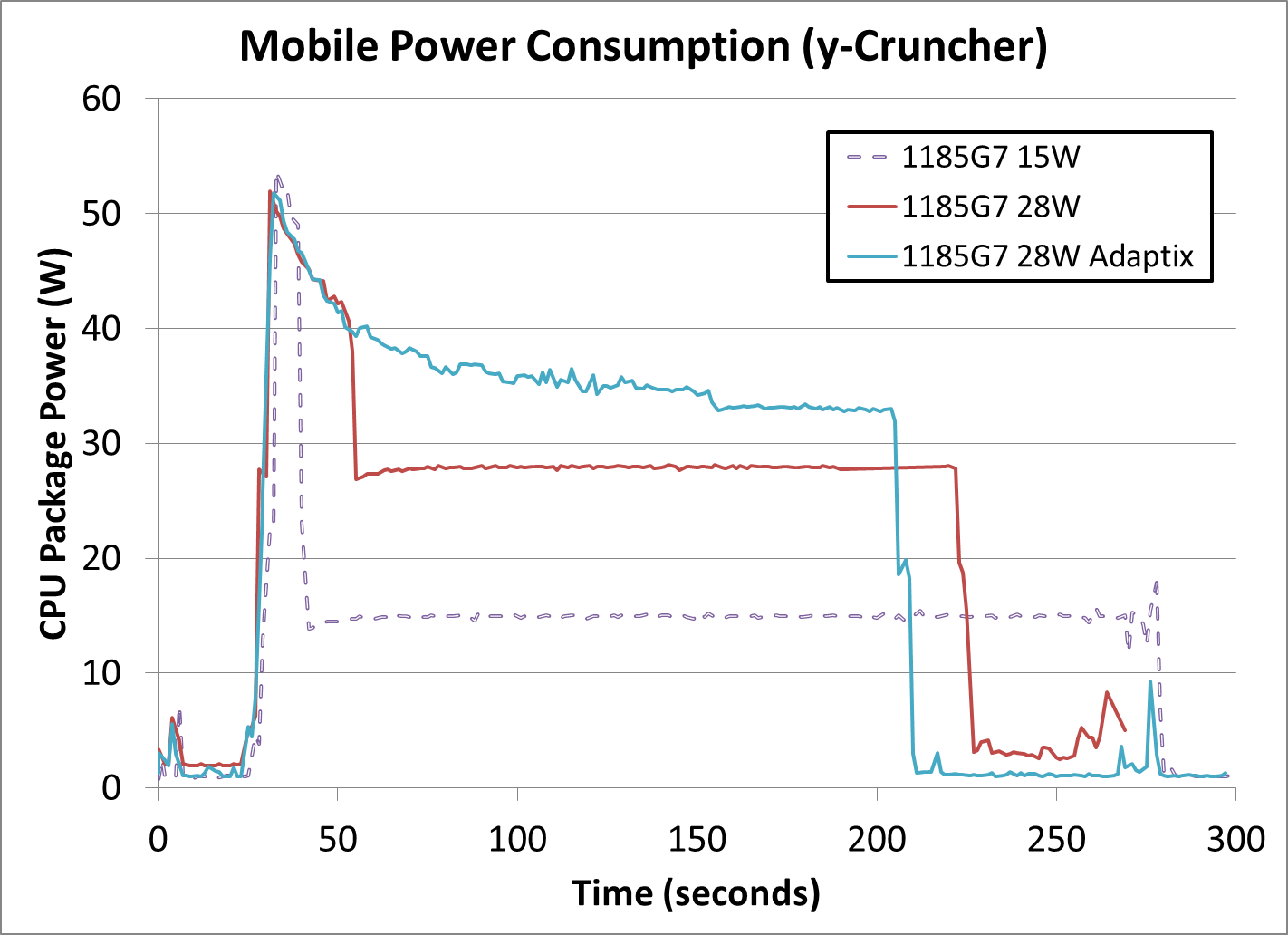
This is a fixed workload to calculate 2.5 billion digits of Pi, which takes around 170-250 seconds, and uses both AVX-512 and 11.2 GB of DRAM to execute. We can already draw conclusions.
In all three power modes, the turbo mode power limit (PL2) is approximately the same at around 52 watts. As the system continues with turbo mode, the power consumed is decreased until the power budget is used up, and the 28 W mode has just over double the power budget of the 15 W mode.
Adaptix clearly works best like this, and although it initially follows the same downward trend as the regular 28 W mode, it levels out without hitting much of a ‘base’ frequency at all. Around about the 150 second mark (120 seconds into the test), there is a big enough drop followed by a flat-line which would probably indicate a thermally-derived sustained power mode, which occurs at 33 watts.
The overall time to complete this test was:
- Core i7-1185G7 at 15 W: 243 seconds
- Core i7-1185G7 at 28 W: 191 seconds
- Core i7-1185G7 at 28 W Adaptix: 174 seconds
In this case moving from 15 W to 28 W gives a 27% speed-up, while Adaptix is a total 40% speed-up.
However, this extra speed does come at the cost of total power consumed. With most processors, the peak efficiency point is when the system is at idle, and while these processors do have a good range of high efficiency, when the peak frequencies are requested then we are in a worst case scenario. Because this benchmark measures power over time, we can integrate to get total benchmark power consumed:
- Core i7-1185G7 at 15 W: 4082 joules
- Core i7-1185G7 at 28 W: 6158 joules
- Core i7-1185G7 at 28 W Adaptix: 6718 joules
This means that for the extra 27% performance, an extra 51% power is used. For Adaptix, that 40% extra performance means 65% more power. This is the trade off with the faster processors, and this is why battery management in mobile systems is so important - if a task is lower priority and can be run in the background, then that is the best way to do it to conserve battery power. This means things like email retrieval, or server synchronization, or thumbnail generation. However, because users demand the start menu to pop up IMMEDIATELY, then user-experience events are always put to the max and then the system goes quickly to idle.
Professional ISV Workload
In our second test, we put our power monitoring tools on Agisoft’s Photoscan. This test is somewhat of a compute test, split into four algorithms, however some sections are more scalable than others. Normally in this test we would see some sections rely on single threaded performance, while other sections use AVX2.
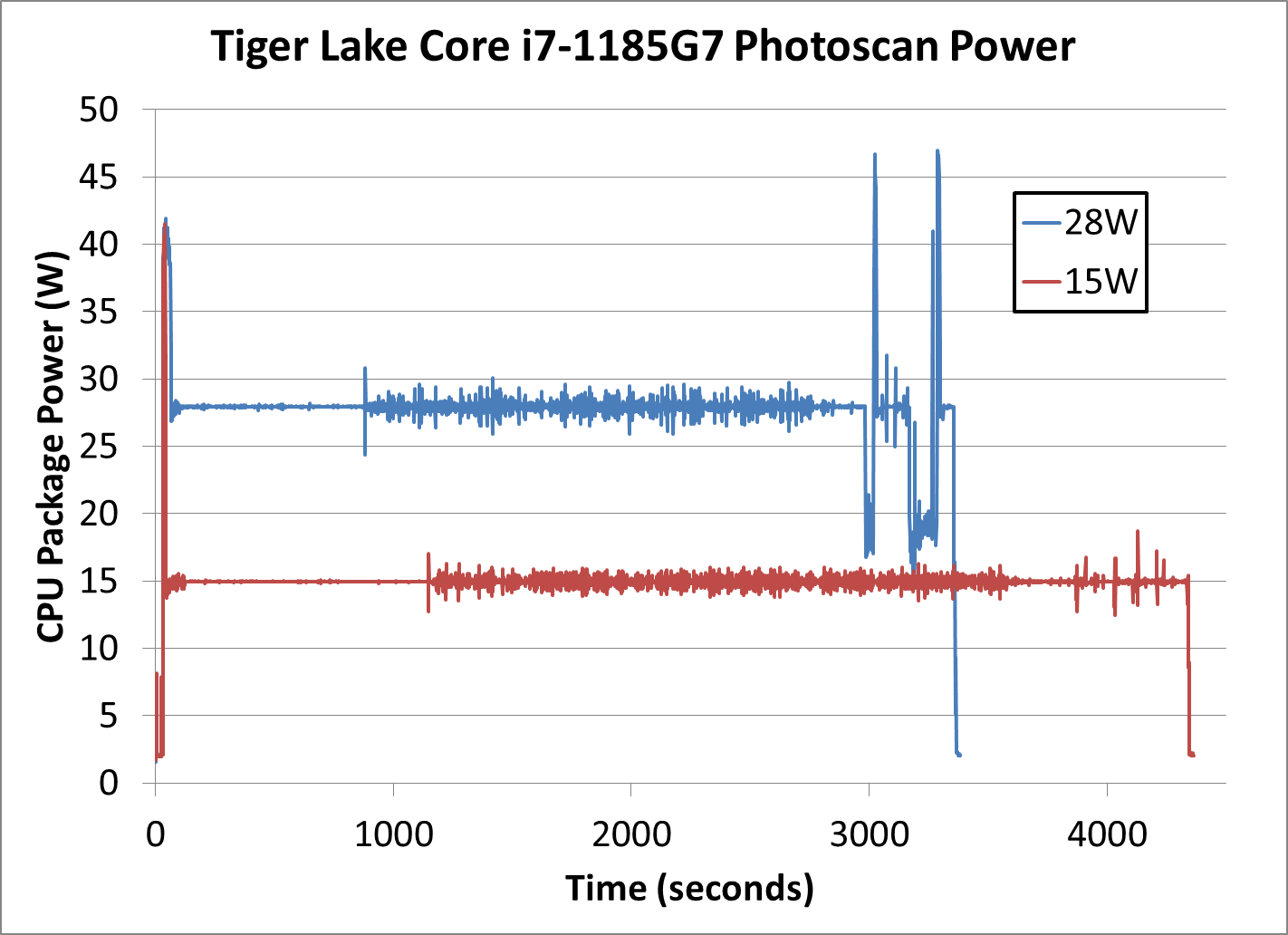
This is a longer test, and so the immediate turbo is less of a leading factor across the whole benchmark. For the first section the system seems content to sit at the respective TDPs, but the second section shows a more variable up and down as power budget is momentarily gained and then used up immediately.
Doing the same maths as before,
- At 15 W, the benchmark took 4311 seconds and consumed 64854 joules
- At 28 W, the benchmark took 3330 seconds and consumed 92508 joules
For a benchmark that takes about an hour, a +30% performance uplift is quite considerable, however it comes at the expense of +43% power. This is a better ratio than the first compute workload, but still showcases that 28 W is further away from Tiger Lake’s ideal efficiency point.
Note that the power-over-time graph we get for Agisoft on a mobile processor looks very different to that of a desktop processor, as a mobile processor core can go above the TDP budget with fewer threads.
This leads to the dichotomy of mobile use cases with respect to the marketing that goes on for these products - as part of the Tiger Lake launch, Intel was promoting its use for streaming, professional workflows such as Adobe, video editing and content creation, and AI acceleration. All of these are high-performance workloads, compared to web browsing or basic office work. Partly because Tiger Lake is built on the latest process technology, as well as offering Intel’s best performing CPU and GPU cores, the product is going to be pitched in the premium device market for the professionals and prosumers that can take advantage.








253 Comments
View All Comments
blppt - Saturday, September 26, 2020 - link
Sure, the box sitting right next to my desk doesn't exist. Nor the 10 or so AMD cards I've bought over the past 20 years.1 5970
2 7970s (for CFX)
1 Sapphire 290x (BF4 edition, ridiculously loud under load)
2 XFX 290 (much better cooler than the BF4 290x) mistakenly bought when I thought it would accept a flash to 290x, got the wrong builds, for CFX)
2 290x 8gb sapphire custom edition (for CFX, much, much quieter than the 290x)
1 Vega 64 watercooled (actually turned out to be useful for a Hackintosh build)
1 5700xt stock edition
Yeah, i just made this stuff up off the top of my head. I guarantee I've had more experience with AMD videocards than the average gamer. Remember the separate CFX CAP profiles? I sure do.
So please, tell me again how I'm only a Nvidia owner.
Santoval - Sunday, September 20, 2020 - link
If the top-end Big Navi is going to be 30-40% faster than the 2080 Ti then the 3080 (and later on the 3080 Ti, which will fit between the 3080 and the 3090) will be *way* beyond it in performance, in a continuation of the status quo of the last several graphics card generations. In fact it will be even worse this generation, since Big Navi needs to be 52% faster than the 2080 Ti to even match the 3070 in FP32 performance.Sure, it might have double the memory of the 3070, but how much will that matter if it's going to be 15 - 20% slower than a supposed "lower grade" Nvidia card? In other words "30-40% faster than the 2080 Ti" is not enough to compete with Ampere.
By the way, we have no idea how well Big Navi and the rest of the RDNA2 cards will perform in ray-tracing, but I am not sure how that matters to most people. *If* the top-end Big Navi has 16 GB of RAM, it costs just as much as the 3070 and is slightly (up to 5-10%) slower than it in FP32 performance but handily outperforms it in ray-tracing performance then it might be an attractive buy. But I doubt any margins will be left for AMD if they sell a 16 GB card for $500.
If it is 15-20% slower and costs $100 more noone but those who absolutely want 16 GB of graphics RAM will buy it; and if the top-end card only has 12 GB of RAM there goes the large memory incentive as well..
Spunjji - Sunday, September 20, 2020 - link
@Santoval, why are you speaking as if the 3080's performance characteristics are not already known? We have the benchmarks in now.More importantly, why are you making the assumption that AMD need to beat Nvidia's theoretical FP32 performance when it was always obvious (and now extremely clear) that it has very little bearing on the product's actual performance in games?
The rest of your speculation is knocked out of what by that. The likelihood of an 80CU RDNA 2 card underperforming the 3070 is nil. The likelihood of it underperforming the 3080 (which performs like twice a 5700, non-XT) is also low.
Byte - Monday, September 21, 2020 - link
Nvidia probably has a good idea how it performs with access to PS5/Xbox, they know they had to be aggressive this round with clock speeds and pricing. As we can see 3080 is almost maxed, o/c headroom like that of AMD chips, and price is reasonable decent, in line with 1080 launch prices before minepocalypse.TimSyd - Saturday, September 19, 2020 - link
Ahh don't ya just love the fresh smell of TROLLevernessince - Sunday, September 20, 2020 - link
The 5700XT is RDNA1 and it's 1/3rd the size of the 2080 Ti. 1/3rd the size and only 30% less performance. Now imagine a GPU twice the size of the 5700XT, thus having twice the performance. Now add in the node shrink and new architecture.I wouldn't be surprised if the 6700XT beat the 2080 Ti, let alone AMD's bigger Navi 2 GPUs.
Cooe - Friday, December 25, 2020 - link
Hahahaha. "Only matching a 2080 Ti". How's it feel to be an idiot?tipoo - Friday, September 18, 2020 - link
I'd again ask you why a laptop SoC would have an answer for a big GPU. That's not what this product is.dotjaz - Friday, September 18, 2020 - link
"This Intel Tiger" doesn't need an answer for Big Navi, no laptop chip needs one at all. Big Navi is 300W+, no way it's going in a laptop.RDNA2+ will trickle down to mobile APU eventually, but we don't know if Van Gogh can beat TGL yet, I'm betting not because it's likely a 7-15W part with weaker Quadcore Zen2.
Proper RDNA2+ APU won't be out until 2022/Zen4. By then Intel will have the next gen Xe.
Santoval - Sunday, September 20, 2020 - link
Intel's next gen Xe (in Alder Lake) is going to be a minor upgrade to the original Xe. Not a redesign, just an optimization to target higher clocks. The optimization will largely (or only) happen at the node level, since it will be fabbed with second gen SuperFin (formerly 10nm+++), which is supposed to be (assuming no further 7nm delays) Intel's last 10nm node variant.How well will that work, and thus how well 2nd gen Xe will perform, will depend on how high Intel's 2nd gen SuperFin will clock. At best 150 - 200 MHz higher clocks can probably be expected.