New #1 Supercomputer: Fugaku in Japan, with A64FX, take Arm to the Top with 415 PetaFLOPs
by Dr. Ian Cutress on June 22, 2020 11:00 AM EST
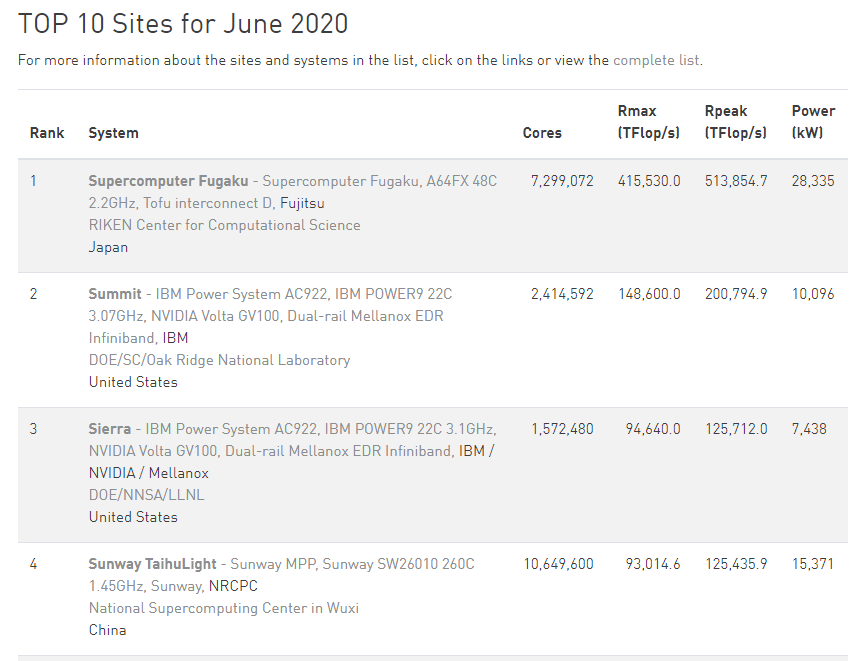
High performance computing is now at a point in its existence where to be the number one, you need very powerful, very efficient hardware, lots of it, and lots of capability to deploy it. Deploying a single rack of servers to total a couple of thousand cores isn’t going to cut it. The former #1 supercomputer, Summit, is built from 22-core IBM Power9 CPUs paired with NVIDIA GV100 accelerators, totaling 2.4 million cores and consuming 10 MegaWatts of power. The new Fugaku supercomputer, built at Riken in partnership with Fujitsu, takes the top spot on the June 2020 #1 list, with 7.3 million cores and consuming 28 MegaWatts of power.

The new Fugaku supercomputer is bigger than Summit in practically every way. It has 3.05x cores, it has 2.8x the score in the official LINPACK tests, and consumes 2.8x the power. It also marks the first time that an Arm based system sits at number one on the top 500 list.
Due to the onset of the Coronavirus pandemic, Riken accelerated the deployment of Fugaku in recent months. On May 13th, Riken announced that more than 400 racks, each featuring multiple 48-core A64FX cards per server, were deployed. This was a process that had started back in December, but they were so keen on getting the supercomputer up and running to assist with the R&D as soon as possible – the server racks didn’t have their official front panels when they started working. There are still additional resources to add, with full operation scheduled to begin in Riken’s Fiscal 2021, suggesting that Fugaku’s compute values on the top 100 list are set to rise even higher.
Alongside being #1 in the TOP500, Fugaku enters the Green500 List at #9, just behind Summit, and below the Fugaku Prototype installation which sits at #4.

At the heart of Fugaku is the A64FX, a custom Arm v8-A CPU-based chip optimised for compute. The total configuration uses 158,976 of these 48+4-core cards, running at 2.2 GHz peak performance (48 cores for compute, 4 for assistance). This allows for some substantial Rpeak numbers, such as 537 PetaFLOPs of FP64, the usual TOP500 metric. But A64FX also supports quantized models with lower precision, which is where we get into some fun numbers for Fugaku:
- FP64: 0.54 ExaFLOPs
- FP32: 1.07 ExaOPs
- FP16: 2.15 ExaOPs
- INT8: 4.30 ExaOPs
Due to the design of the A64FX, it also allows for a total memory bandwith of 163 PetaBytes per second.

To date, the A64FX compute card is the only implementation of Arm’s v8.2-A Scalable Vector Extensions (SVE). The goal of SVE is to allow Arm’s customers to build hardware with vector units ranging from 128-bit to 2048-bit, such that any software that is built to run on SVE will automatically scale regardless of the SVE execution unit size. A64FX uses two 512-bit wide pipes per core, with 48 compute cores per chip, and also adds in four 8 GiB HBM2 links per chip in order to feed the units for 1 TiB/s of total bandwidth into the chip.

As listed above, the unit supports INT8 through FP64, and the chip has an on-board custom Tofu interconnect, supporting up to 560 Gbps of interconnect to other A64FX modules. The chip is built on TSMC’s N7 process, and comes in at 8.79 billion transistors. 90% execution efficiency is claimed for DGEMM type workloads, and additional mechanisms such as combined gather and unaligned SIMD loading are used to help keep throughput high. There is also additional tuning that can be done at the power level for optimization, and extensive internal RAS (over 128k error checkers in silicon) to ensure accuracy.

Details on the A64FX chip were disclosed at Hot Chips in 2018, and we saw wafers and chips at Supercomputing in 2019. This chip is expected to be the first in a series of chips from Fujitsu along a similar HPC theme.

Work done on Fugaku to date includes simulations about Japan’s COVID-19 track and tracing app. According to Professor Satoshi Matsuoka, predictions calculated by Fugaku suggested a 60% distribution on the app development in order to be successful. Droplet simulations have also been performed on virus activity. Deployment of A64FX is set to go beyond Riken, with Sandia Labs to also have an A64FX system based in the US.
Source: TOP500
Related Reading
- A Success on Arm for HPC: We Found a Fujitsu A64FX Wafer
- Hot Chips 2018: Fujitsu's A64FX Arm Core Live Blog








46 Comments
View All Comments
surt - Monday, June 22, 2020 - link
And 2.5x performance on only 2.8x power!nft76 - Monday, June 22, 2020 - link
Calculating TFLOPS/W with just Linpack performance gives a rather one-sided view. In HPCG Fugaku is more than twice as efficient as Summit (assuming similar power consumption as in HPL; they don't seem to give power usage in HPCG).mode_13h - Monday, June 22, 2020 - link
Still, you're comparing with old tech. The real test will be to see how it compares with Nvidia's A100, which seems to be much more adept at dealing with things like sparsity.nft76 - Monday, June 22, 2020 - link
Nvidia's own A100 installation is included in the list and it's not much better than computers using V100 in HPCG (in fact, ratio of HPCG to peak performance seems to be a bit worse).That said, Fugaku's HPCG-to-peak ratio is high also compared to other CPU-only systems, so maybe it's more that the custom interconnect is really good for the problem.
anonomouse - Monday, June 22, 2020 - link
As another comparison point, Fugaku is also tops (by quite a lot) the list for Graph500, for which Oak Ridge Summit only even submitted a CPU-Only run. I don't see any GPU runs at all, with the closest match being some KNL-based systems and the chinese Sunway machine, which has their own custom KNL-equivalents. Supposedly the new A100 GPUs are supposed to be a lot better at Graphs, but it's pretty telling on architecture flexibility that there are no GPU submission to date for this.And based on the number of nodes and cores used for Fugaku in the submission, it only used a bit over half of the full supercomputer.
mode_13h - Monday, June 22, 2020 - link
> they were so keen on getting the supercomputer up and running to assist with the R&D as soon as possible – the server racks didn’t have their official front panels when they started working.Oooo, scandalous! How dare they!
quadibloc - Monday, June 22, 2020 - link
That's about 3.77 Teraflops of FP64 per chip, which is indeed pretty good.Ushio01 - Monday, June 22, 2020 - link
So if Fujitsu is working with ARM CPU's for supercomputers does that mean they have abandoned development of SPARC?eastcoast_pete - Monday, June 22, 2020 - link
From what I remember, yes, that's pretty much the story. Fujitsu developed this chip to have a follow-up to SPARC; it probably didn't help that Oracle finally killed SPARC off after strangulating it for years.Andrew_Waite - Monday, June 22, 2020 - link
ARM based, so a BBC Micro with a few bells and whistles then :-)