Amazon's Arm-based Graviton2 Against AMD and Intel: Comparing Cloud Compute
by Andrei Frumusanu on March 10, 2020 8:30 AM EST- Posted in
- Servers
- CPUs
- Cloud Computing
- Amazon
- AWS
- Neoverse N1
- Graviton2
SPEC - MT Performance (4xlarge 16 vCPU)
The 64-core results were quite interesting and put the Graviton2 in a very competitive performance position, but all this talk about performance scaling varying depending on the loaded core count of the system made me wonder how the EC2 instances would perform at lower vCPU counts.
I fired up the same tests, just this time around with only rate-16 to match the number of vCPUs. These are 4xlarge EC2 instances with corresponding 16 vCPUs, but there’s one large caveat in this comparison that we must keep in mind: The Graviton2 instances very likely have no neighbours at this point in time in the test preview, meaning the performance scaling we’re seeing here is very much a best-case scenario for the Amazon chip. EC2 global capacity floats around at 60% active usage, and I imagine Amazon distributes this horizontally across the available sockets in their datacentres. How these performance figures will look like in the real world once Graviton2 ramps up in public availability is anybody’s guess.
The AMD system likely won’t care too much about such scenarios as their NUMA nature means they’re isolated from noisy neighbours anyhow, and we’re just seeing use of a single 8-core chip with its own memory controllers, but the Intel system will have possibly some neighbours doing some activity on the same socket and shared resources. I only ran one test run here; you’d probably need a lot of data to get a representative figure across EC2 usage.
For the Intel m5n instances, using an 4xlarge instance actually means you're only on on single socket this time around, meaning that the scaling behaviour in favour of higher per-thread performance isn't to be expected as high as on the Graviton2 system, as system DRAM bandwidth and L3 is halved compared to the 16xlarge figures on the previous page.
Also, since we’re testing 16 vCPU setups here, we can have an apples-to-apples comparison between the first- and second-generation Graviton systems which should be a fun comparison.
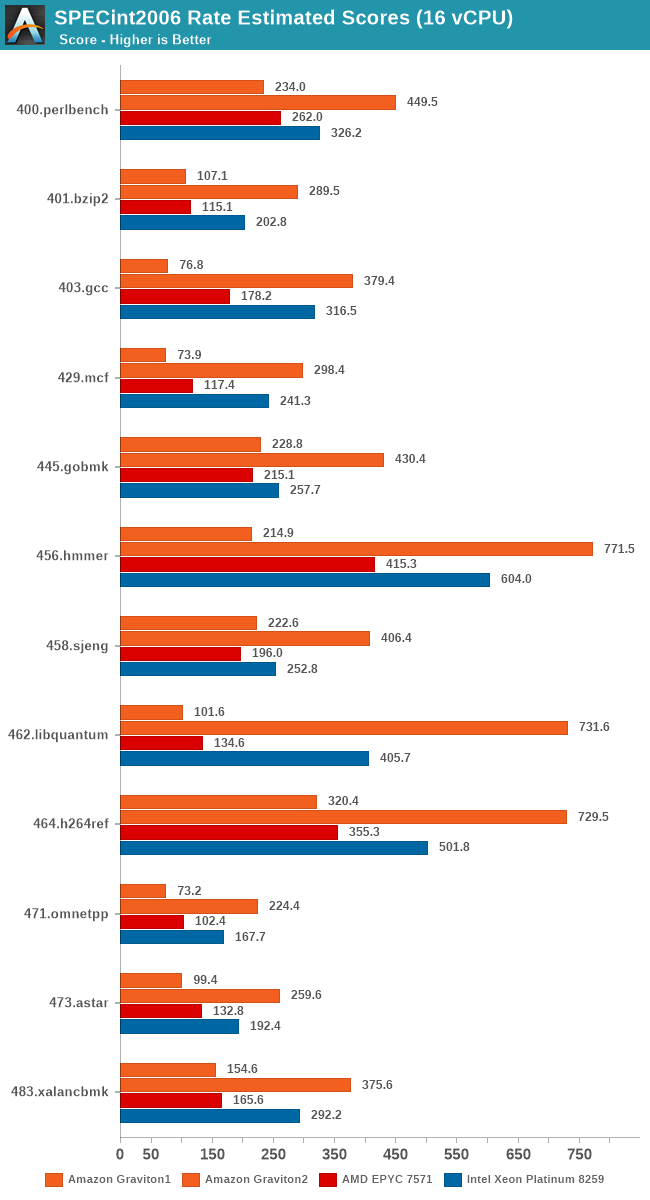
The comparison between the two generations of Graviton processors here is also astounding. Memory intensive workloads favour the newer Graviton2 by at least a factor of 2x, more often 3x, 4x, 5x and even up to 7x in libquantum.
The AMD system as expected doesn’t gain much scaling from using less cores as there’s no more shared resources available on a per-thread basis. The Intel chip fares slightly better per-thread, but doesn’t see the same higher performance scaling (Or should I say, reverse-scaling) as achieved by the Graviton2.
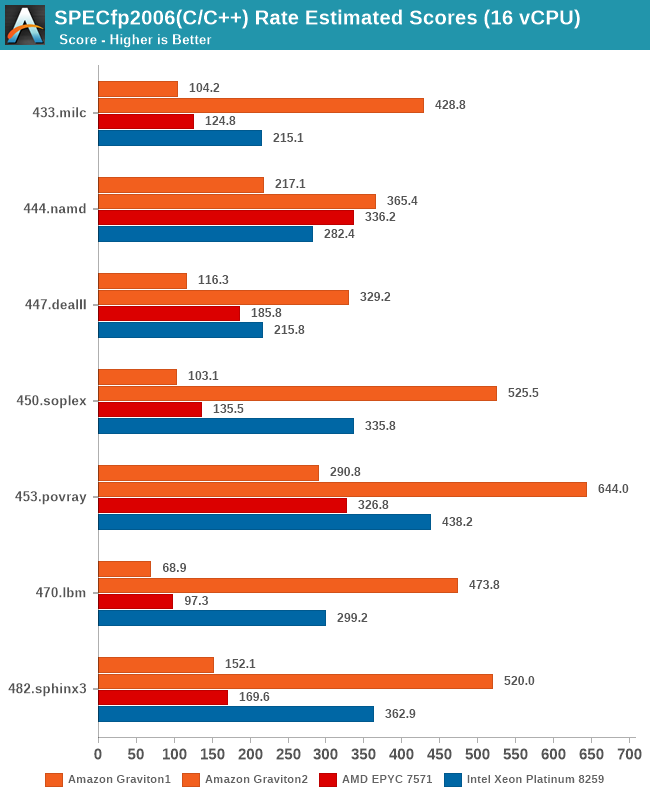
In fp2006, we see more or less the same kind of results.
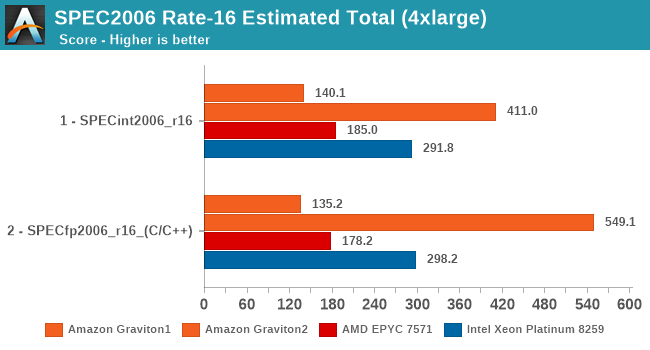
Overall, in the 16-vCPU rate results the Graviton2 surpasses the performance advantage it showcased in the 64-core results, ending up with an even bigger margin.
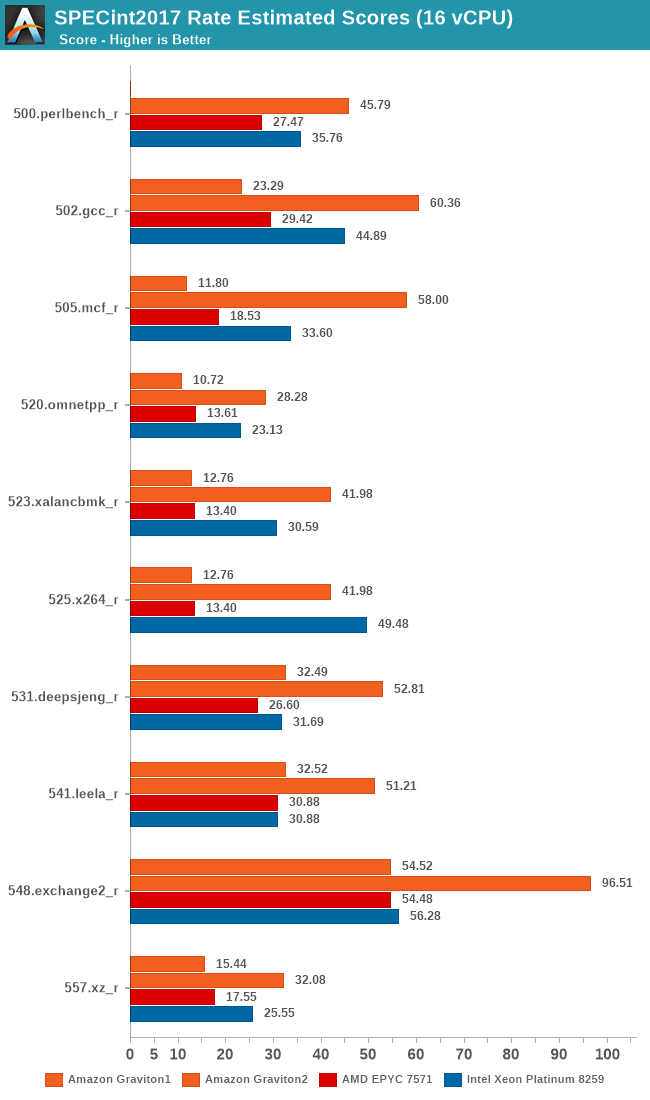
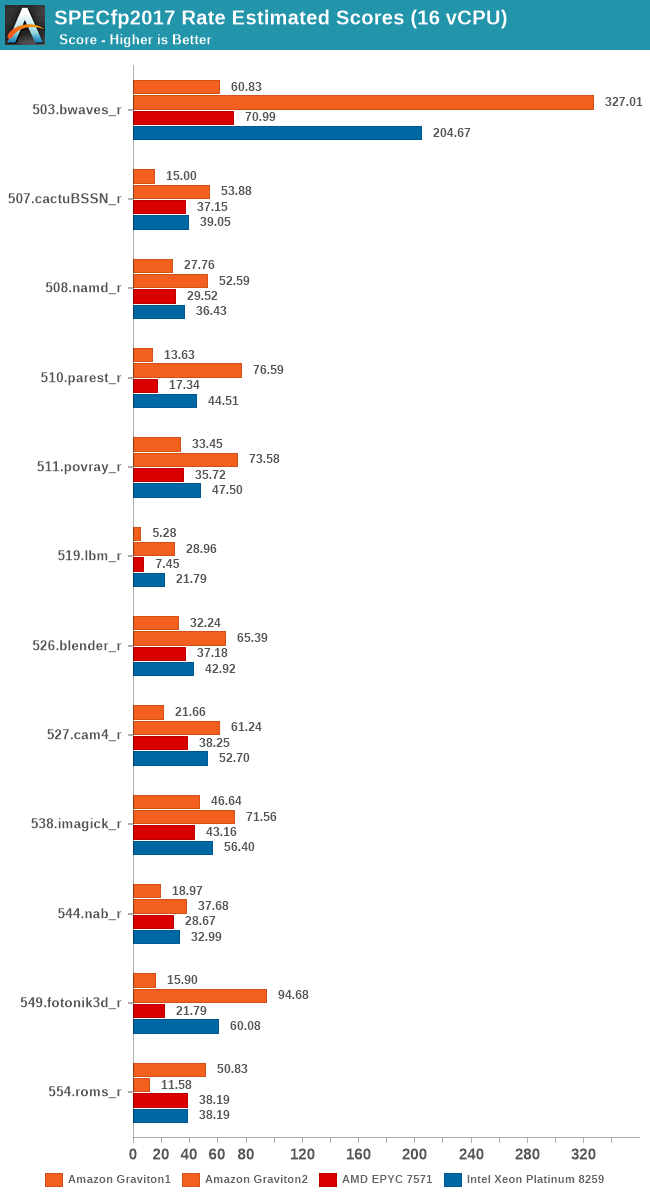
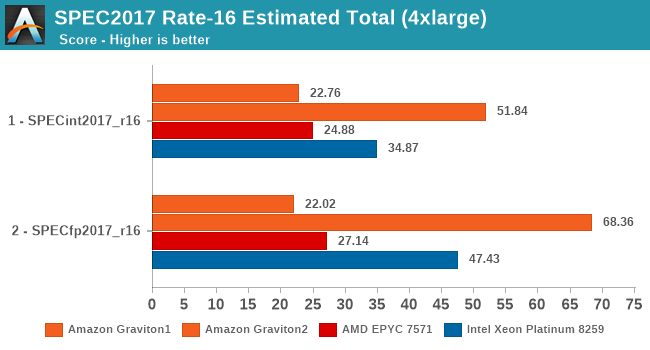
The SPEC2017 results again show the same conclusion – the Graviton2 really gains a ton of per-thread performance through the ability to use more of the chip’s L3 cache and 8 memory channels. Whilst on the 64-rate results the Graviton2 and the Xeon were neck-in-neck in fp2017, here the Graviton ends up with a 44% performance advantage.
Again, I can’t put enough emphasis on this, but these results are a best-case scenario for the 4xlarge 16vCPU results of the Graviton2. If production instances are able to achieve such figures will very largely depend on the draw of luck on whether you’re going to be alone on the physical hardware or whether you’ll have any neighbours on the chip. And even if you have neighbours, the performance figures will largely depend on what kind of workloads they will be running alongside your use-cases.
I saw a few articles out there comparing the performance between the m6g instances against the m5 generation instances (Skylake-SP hardware), but most of these tests were done only on medium (1 vCPU) to xlarge (4 vCPUs). When reading such pieces, it’s naturally important to keep in mind the vast scaling advantage the Graviton2 chip has – the smaller your instance is the more chance you’ll have noisy neighbours on the hardware, something that currently just doesn’t happen in the Graviton2’s preview phase.








96 Comments
View All Comments
Duncan Macdonald - Tuesday, March 10, 2020 - link
The Apple CPU cores are larger and more power hungry when loaded hard than the CPU cores on the N1. A 64 CPU chip with the high performance cores from the Apple A13 would consume far more power than the N1 and would be quite a bit larger than the N1. The Apple A13 chip (in the iPhone 11) is suited for intermittent load not the sustained use that server type chips such as the N1 have to deal with.arashi - Wednesday, March 11, 2020 - link
Yikesmanedsib1 - Tuesday, March 10, 2020 - link
You are using an Epyc processor that is nearly 3 years old.Surely you should use this years model (or a 64-corer threadripper if you dont have one)
vanilla_gorilla - Wednesday, March 11, 2020 - link
You should consider reading the article and then you would know exactly why they are using those CPU.Kamen Rider Blade - Tuesday, March 10, 2020 - link
The benchmarks feel incomplete. Why don't you have a 64-core Zen2 based processor in it to compare?Even the ThreadRipper 64-core would be something.
But not having AMD's latest Server grade CPU in your benchmarks really feels like you're doing a disservice to your readers, especially since we've seen your previous reviews with the Zen 2 64 core monster.
Rudde - Wednesday, March 11, 2020 - link
Read the article! Rome is mentioned over five times. In short, Amazon doesn't offer Rome instances yet and Anandtech will update this article once they do.Sahrin - Tuesday, March 10, 2020 - link
I may be remembering incorrectly, but doesn't Gen 1 Epyc have the same cache tweaks as Zen+ (ie, Epyc 7001 series is based on Zen+, not Zen)?Rudde - Wednesday, March 11, 2020 - link
They have same optimisations as first gen Zen APUs, i.e. Ryzen mobile 2xxx. Zen+ is a further developed architecture, albeit without further cache tweaks.The cache tweaks in question were meant to be included in the origina Zen, but didn't make it in time. As such one could argue that first gen Ryzen desktop is not full Zen (1), but a preview.
Sahrin - Tuesday, March 10, 2020 - link
The fact that Amazon refused to grant access to Rome-based instances tells you everything you need to know. Graviton competes with Zen and Xeon, but is absolutely smoked by Zen 2 in both absolute terms and perf/watt.It's a shame to see Amazon hide behind marketing bullshit to make its products seem relevant.
rahvin - Thursday, March 12, 2020 - link
Don't be silly. Amazon buys processors in the thousands. There is no way AMD could have supplied enough Rome CPU's to Amazon to load up an instance at each of their locations in the time Rome has been for sale.It typical takes about 6 months before Amazon gets instances online because AMD/Intel aren't going to give Amazon the entire production run for the first 3 months. They've got about 20 data centers and you'd probably need several hundered per data center to bring an instance up.
Consider the cost and scale of building that out before you criticize them for not having the latest and greatest released a month a go. Rome hasn't been available to actually purchase for very long and the Cloud providers get special models and AMD still needs to supply everyone else as well.