AMD Rome Second Generation EPYC Review: 2x 64-core Benchmarked
by Johan De Gelas on August 7, 2019 7:00 PM ESTMemory Subsystem: TinyMemBench
We doublechecked our LMBench numbers with Andrei's custom memory latency test.
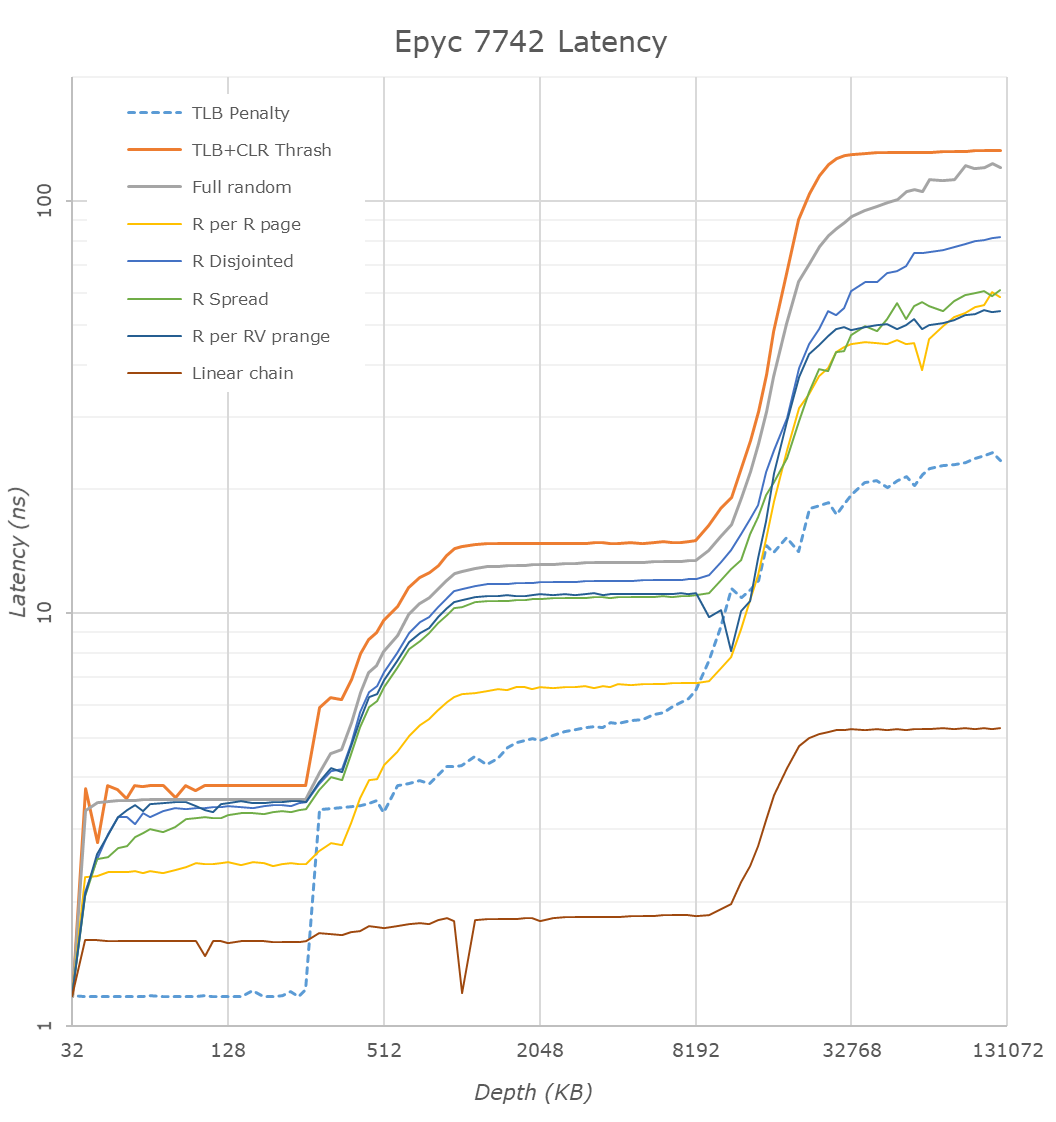
The latency tool also measures bandwidth and it became clear than once we move beyond 16 MB, DRAM is accessed. When Andrei compared with our Ryzen 9 3900x numbers, he noted:
The prefetchers on the Rome platform don't look nearly as aggressive as on the Ryzen unit on the L2 and L3
It would appear that parts of the prefetchers are adjusted for Rome compared to Ryzen 3000. In effect, the prefetchers are less aggressive than on the consumer parts, and we believe that AMD has made this choice by the fact that quite a few applications (Java and HPC) suffer a bit if the prefetchers take up too much bandwidth. By making the prefetchers less aggressive in Rome, it could aid performance in those tests.
While we could not retest all our servers with Andrei's memory latency test by the deadline (see the "Murphy's Law" section on page 5), we turned to our open source TinyMemBench benchmark results. The source was compiled for x86 with GCC and the optimization level was set to "-O3". The measurement is described well by the manual of TinyMemBench:
Average time is measured for random memory accesses in the buffers of different sizes. The larger the buffer, the more significant the relative contributions of TLB, L1/L2 cache misses, and DRAM accesses become. All the numbers represent extra time, which needs to be added to L1 cache latency (4 cycles).
We tested with dual random read, as we wanted to see how the memory system coped with multiple read requests.
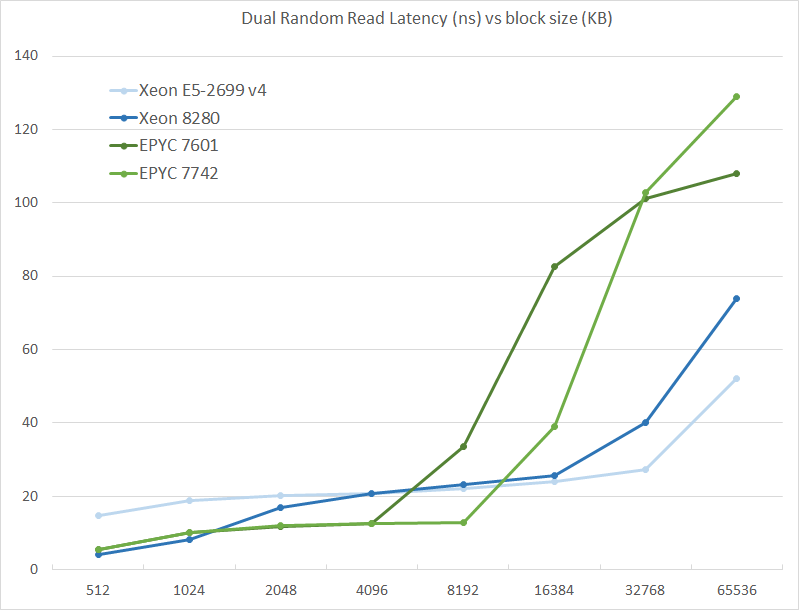
The graph shows how the larger L3 cache of the EPYC 7742 resulting in a much lower latency between 4 and 16 MB, compared to the EPYC 7601. The L3 cache inside the CCX is also very fast (2-8 MB) compared to Intel's Mesh (8280) and Ring topologies (E5).
However, once we access more than 16 MB, Intel has a clear advantage due to the slower but much larger shared L3 cache. When we tested the new EPYC CPUs in a more advanced NUMA setting (with NPS = 4 setting, meaning 4 nodes per socket), latency at 64 MB lowered from 129 to 119. We quote AMD's engineering:
In NPS4, the NUMA domains are reported to software in such a way as it chiplets always access the near (2 channels) DRAM. In NPS1 the 8ch are hardware-interleaved and there is more latency to get to further ones. It varies by pairs of DRAM channels, with the furthest one being ~20-25ns (depending on the various speeds) further away than the nearest. Generally, the latencies are +~6-8ns, +~8-10ns, +~20-25ns in pairs of channels vs the physically nearest ones."
So that also explains why AMD states that select workloads achieve better performance with NPS = 4.








180 Comments
View All Comments
Kevin G - Wednesday, August 7, 2019 - link
Clock speeds. AMD is being very aggressive on clocks here but the Ryzen 3000 series were still higher. I would expect new Threadripper chips to clock closer to their Ryzen 3000 cousins.AMD *might* differentiate Threadripper by cache amounts. While the CPU cores work, they may end up binning Threadripper based upon the amount of cache that wouldn't pass memory tests.
Last thing would be price. The low end Epyc chips are not that expensive but suffer from low cores/low clocks. Threadripper can offer more for those prices.
quorm - Wednesday, August 7, 2019 - link
Here's hoping we see a 16 core threadripper with a 4ghz base clock.azfacea - Wednesday, August 7, 2019 - link
half memory channels. half pcie lanes. also i think with epyc AMD spends more on support and system development. i can see 48c 64c threadripper coming 30-40% lower and not affecting epyctwtech - Wednesday, August 7, 2019 - link
If they gimp the memory access again, it mostly defeats the purpose of TR as a workstation chip. You'd want an Epyc anyway.quorm - Wednesday, August 7, 2019 - link
Well, on the plus side, the i/o die should solve the asymmetric memory access problem.ikjadoon - Wednesday, August 7, 2019 - link
Stunning.aryonoco - Wednesday, August 7, 2019 - link
Between 50% to 100% higher performance while costing between 40% to 50% less. Stunning!I remember the sad days of Opteron in 2012 and 2013. If you'd told me that by the end of the decade AMD would be in this position, I'd have wanted to know what you're on.
Everyone at AMD deserves a massive cheer, from the technical and engineering team all the way to Lisa Su, who is redefining what "execution" means.
Also thanks for the testing Johan, I can imagine testing this server at home with Europe's recent heatwave would have not been fun. Good to see you writing frequently for AT again, and looking forward to more of your real world benchmarks.
twtech - Wednesday, August 7, 2019 - link
It's as much about Intel having dropped the ball over the past few years as it is about AMD's execution.According to Intel's old roadmaps, they ought to be transitioning past 10nm on to 7nm by now, and AMD's recent releases in that environment would have seemed far less impressive.
deltaFx2 - Wednesday, August 7, 2019 - link
Yeah, except I don't remember anyone saying Intel was going great guns because AMD dropped the ball in the bulldozer era. AMD had great bulldozer roadmaps too, it didn't matter much. If bulldozer had met its design targets maybe Nehalem would not be as impressive... See, nobody ever says that. It's almost like if AMD is doing well, it's not because they did a good job but intel screwed up.Roadmaps are cheap. Anyone can cobble together a powerpoint slide.
Lord of the Bored - Thursday, August 8, 2019 - link
Well, it is a little of both on both sides.Intel's been doing really well in part because AMD bet hard on Bulldozer and it didn't pay out.
Similarly, when AMD's made really good processors but Intel was on their game, it didn't much matter. The Athlon and the P2/3 traded blows in the Megahertz wars, but in the end AMD couldn't actually break Intel because Intel made crooked business deals*backspace* because AMD was great, but not actually BETTER.
The Athlon 64 was legendary because AMD was at the top of their game and Intel was riding THEIR Bulldozer into the ground at the same time. If the Pentium Mobile hadn't existed, thus delaying a Netburst replacement, things would be very different right now.