AMD Rome Second Generation EPYC Review: 2x 64-core Benchmarked
by Johan De Gelas on August 7, 2019 7:00 PM ESTMemory Subsystem: TinyMemBench
We doublechecked our LMBench numbers with Andrei's custom memory latency test.
The latency tool also measures bandwidth and it became clear than once we move beyond 16 MB, DRAM is accessed. When Andrei compared with our Ryzen 9 3900x numbers, he noted:
The prefetchers on the Rome platform don't look nearly as aggressive as on the Ryzen unit on the L2 and L3
It would appear that parts of the prefetchers are adjusted for Rome compared to Ryzen 3000. In effect, the prefetchers are less aggressive than on the consumer parts, and we believe that AMD has made this choice by the fact that quite a few applications (Java and HPC) suffer a bit if the prefetchers take up too much bandwidth. By making the prefetchers less aggressive in Rome, it could aid performance in those tests.
While we could not retest all our servers with Andrei's memory latency test by the deadline (see the "Murphy's Law" section on page 5), we turned to our open source TinyMemBench benchmark results. The source was compiled for x86 with GCC and the optimization level was set to "-O3". The measurement is described well by the manual of TinyMemBench:
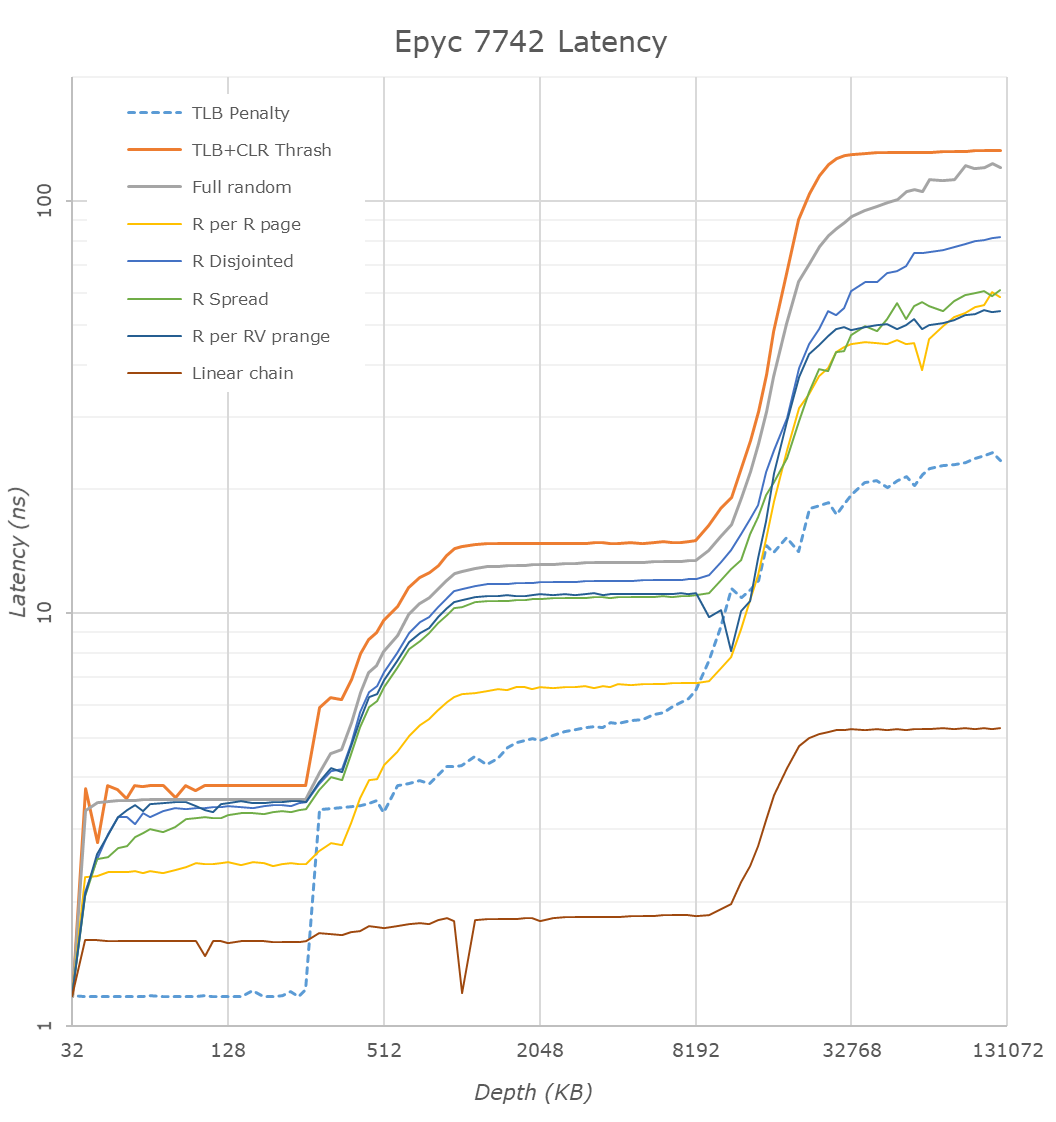
Average time is measured for random memory accesses in the buffers of different sizes. The larger the buffer, the more significant the relative contributions of TLB, L1/L2 cache misses, and DRAM accesses become. All the numbers represent extra time, which needs to be added to L1 cache latency (4 cycles).
We tested with dual random read, as we wanted to see how the memory system coped with multiple read requests.
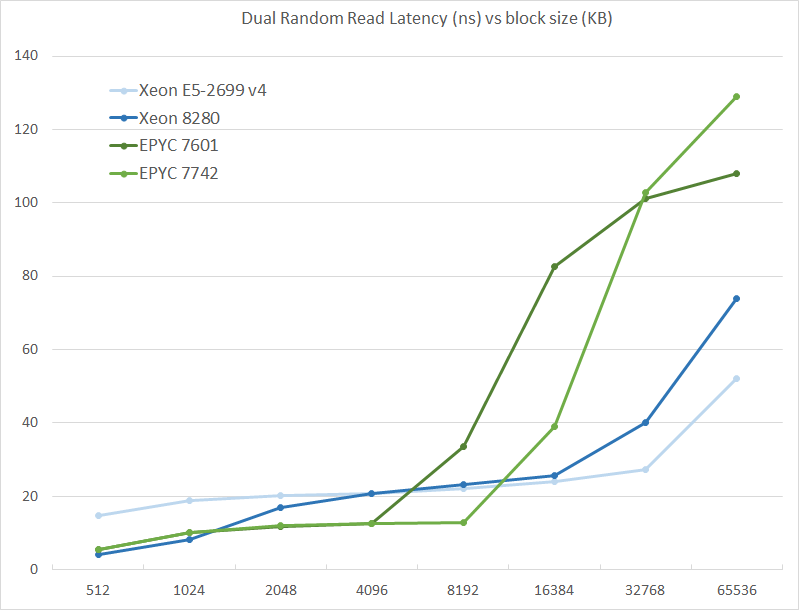
The graph shows how the larger L3 cache of the EPYC 7742 resulting in a much lower latency between 4 and 16 MB, compared to the EPYC 7601. The L3 cache inside the CCX is also very fast (2-8 MB) compared to Intel's Mesh (8280) and Ring topologies (E5).
However, once we access more than 16 MB, Intel has a clear advantage due to the slower but much larger shared L3 cache. When we tested the new EPYC CPUs in a more advanced NUMA setting (with NPS = 4 setting, meaning 4 nodes per socket), latency at 64 MB lowered from 129 to 119. We quote AMD's engineering:
In NPS4, the NUMA domains are reported to software in such a way as it chiplets always access the near (2 channels) DRAM. In NPS1 the 8ch are hardware-interleaved and there is more latency to get to further ones. It varies by pairs of DRAM channels, with the furthest one being ~20-25ns (depending on the various speeds) further away than the nearest. Generally, the latencies are +~6-8ns, +~8-10ns, +~20-25ns in pairs of channels vs the physically nearest ones."
So that also explains why AMD states that select workloads achieve better performance with NPS = 4.








180 Comments
View All Comments
nathanddrews - Wednesday, August 7, 2019 - link
Binned for OC? We'll find out soon enough!DigitalFreak - Thursday, August 8, 2019 - link
At this point it looks like all TR will get your is "official" ECC support and more PCIe lanes. Maybe cheaper motherboards than EPYC.willis936 - Thursday, August 8, 2019 - link
Half the memory lanes (this is a big one), half the pcie lanes, max of 1 socket per mobo. Those are important features for datacenter customers and their absence from threadripper makes threadripper less desirable than epyc in the datacenter.rocky12345 - Thursday, August 8, 2019 - link
Yes but Threadripper is made for high end desktops for video editing etc etc and some gaming. I do not see the big data center guys going after TR all that much. Yes you may see some of the TR go there but that is not what TR is made for that is why we have EPYC & XEON CPU's.I do have to agree though where some said where does TR fit in price wise since we are going to have a 16/32 main stream desktop CPU shortly from AMD. I do also think this time around the 32/64 3990 TR will be 10x better than the older 2990 TR just from the memory controller not being in each CPU complex and in the 2990x because of bandwidth and latency from the memory performance really suffered when all cores were being used. On the 3990x (or whatever it will be called) this should not be an issue. If AMD is smart they will not release a 64/128 3000 series TR since it would have to be priced to far out of reach for even the most techy guy with money and the only ones that would have them would be review sites and YT reviewers and that would be only because them got them sent for free for reviews. 32/64 and the better memory performance as a whole for the new chips would be more than enough to make the 32/64 TR 3990x an instant success. Just my opinion of coarse and AMD will probably do something stupid and release a higher core count TR series CPU that next to no one will be able to afford just to be able to say hey we got the best high end CPU on the planet but to bad no one is gonna buy them because the price is to high but we have the best so who cares.
rocky12345 - Thursday, August 8, 2019 - link
Oops dammit forgot to make paragraph's did not mean to have it all bunched up like that.Mark Rose - Friday, August 9, 2019 - link
Why wouldn't they release a 64 core Threadripper? Assuming they double the price of the 32 core, it would be $3400. That's affordable to a lot of people working in tech, and should be affordable to just about any business that has employees waiting on their 32 core Threadripper. AMD would sell a ton.That being said, I wouldn't personally buy one as I don't have a need. I'd be more likely buy a 16 core 3000 series Threadripper myself.
Manch - Friday, August 9, 2019 - link
Higher Clockssor - Wednesday, August 7, 2019 - link
It will be a feature/packaging thing. The motherboards would be TR4 and feature enthusiast features, overclocked memory, etc, not highly reliable server oriented boards. The processors themselves might be fairly comparable to their EPYC counterparts, as some Xeons were occasionally comparable to their desktop ones.close - Thursday, August 8, 2019 - link
TR was supposed to be a stopgap measure until the consume Ryzen range stretched high enough and the server EPYC range stretched low enough. I guess there is a place for further differentiation especially in terms of the platform (motherboard) used, where you have server like CPU on a more consumer like MB to create basically a workstation. Maybe OC will also fit in here.Death666Angel - Friday, August 9, 2019 - link
"TR was supposed to be a stopgap measure" where can I see AMD stating that? Considering Intel has fared pretty well with the consumer/HEDT/server differentiation, I don't think AMD needs to axe TR. I don't see them giving us EPYC with OC functions and 8 memory channles seems overkill for 16 or 32 desktop cores. I also haven't seen a statement to the effect you claim, so I highly doubt it at the moment.