AMD Rome Second Generation EPYC Review: 2x 64-core Benchmarked
by Johan De Gelas on August 7, 2019 7:00 PM ESTMemory Subsystem: Bandwidth
As we have reported before, measuring the full bandwidth potential with John McCalpin's Stream bandwidth benchmark has become a matter of extreme tuning, requiring a very deep understanding of the platform.
If we used our previous binaries, both the first and second generation EPYC could not get past 200-210 GB/s. It gave the impression of running into a "bandwidth wall", despite the fact that we now had 8-channel DDR4-3200. So we used the results that Intel and AMD best binaries produce using AVX-512 (Intel) and AVX-2 (AMD).
The results are expressed in gigabytes per second.
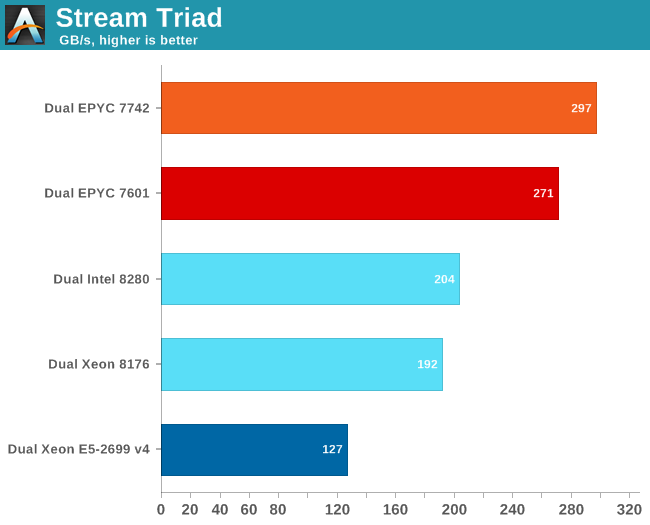
AMD can reach even higher numbers with the setting "number of nodes per socket" (NPS) set to 4. With 4 nodes per socket, AMD reports up to 353 GB/s. NPS4 will cause the CCX to only access the memory controllers with the lowest latency at the central IO Hub chip.
Those numbers only matter to a small niche of carefully AVX(-256/512) optimized HPC applications. AMD claims a 45% advantage compared to the best (28-core) Intel SKUs. We have every reason to believe them but it is only relevant to a niche.
For the rest of the enterprise world (probably 95+%), memory latency has much larger impact than peak bandwidth.








180 Comments
View All Comments
krumme - Thursday, August 8, 2019 - link
Because he is feeded by another hand.Enjoy the objectivity by Johan as its is very rare these days. It's not easy for AT to post this stuff. So kudos to them.
hoohoo - Thursday, August 8, 2019 - link
Nice review, but tbh I think you should run the AMD system as such, not limit it's RAM to what the Intel system maxes out at. I would not buy a system and configure it to limits of the competition: I would configure it to it's actual linits.yankeeDDL - Thursday, August 8, 2019 - link
Wow. "Blasted" is the only word that comes to mind. Good job AMD.eastcoast_pete - Thursday, August 8, 2019 - link
Thanks Johan and Ian! Impressive results, glad to see that AMD is once again making Intel sweat, all of which can only be good for us.Question: A bit out of left field, but why does AMD put the 7 nm dies in these close pairs, as opposed to leaving a little more space between them? Wouldn't thermals be better if each chip gets a little more "reserved" lid space? Just curious. Thanks!
sharath.naik - Thursday, August 8, 2019 - link
Now since we finally are entering the era where a single server(Yes backup is addition) is enough for most of smaller organizations. There is one thing that is needed, OS limits/zones which can limit the cpus and memory built in, instead of using VMs. This will save a lot on resources wasted on booting up an entire OS for individual applications. Linux has the ability for targeting specific cpus but not sure windows has it. But there is a need for standardized way to limit resources by process and by user.mdriftmeyer - Thursday, August 8, 2019 - link
Agreed.quorm - Thursday, August 8, 2019 - link
Is it possible you haven't heard of docker?abufrejoval - Sunday, August 11, 2019 - link
or OpenVZ/Virtuozzo or quite simply cgroups. Can even nest them, including with VMs.DillholeMcRib - Thursday, August 8, 2019 - link
destruction … Intel sat on their proverbial hands too long. It's over.crotach - Friday, August 9, 2019 - link
Bye Intel!!