AMD Rome Second Generation EPYC Review: 2x 64-core Benchmarked
by Johan De Gelas on August 7, 2019 7:00 PM ESTMemory Subsystem: Bandwidth
As we have reported before, measuring the full bandwidth potential with John McCalpin's Stream bandwidth benchmark has become a matter of extreme tuning, requiring a very deep understanding of the platform.
If we used our previous binaries, both the first and second generation EPYC could not get past 200-210 GB/s. It gave the impression of running into a "bandwidth wall", despite the fact that we now had 8-channel DDR4-3200. So we used the results that Intel and AMD best binaries produce using AVX-512 (Intel) and AVX-2 (AMD).
The results are expressed in gigabytes per second.
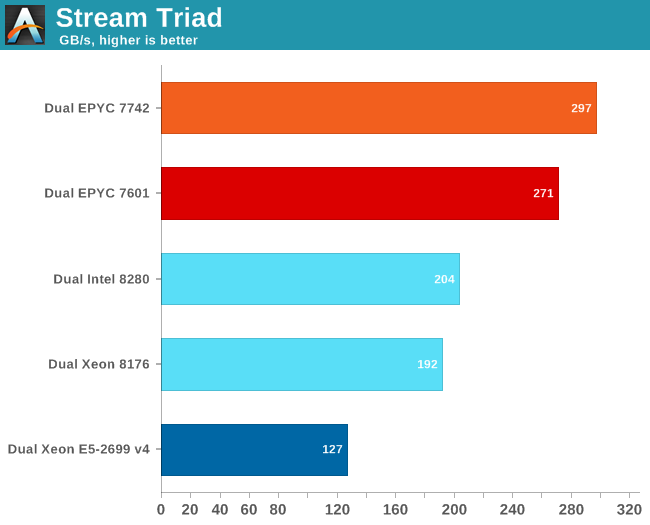
AMD can reach even higher numbers with the setting "number of nodes per socket" (NPS) set to 4. With 4 nodes per socket, AMD reports up to 353 GB/s. NPS4 will cause the CCX to only access the memory controllers with the lowest latency at the central IO Hub chip.
Those numbers only matter to a small niche of carefully AVX(-256/512) optimized HPC applications. AMD claims a 45% advantage compared to the best (28-core) Intel SKUs. We have every reason to believe them but it is only relevant to a niche.
For the rest of the enterprise world (probably 95+%), memory latency has much larger impact than peak bandwidth.








180 Comments
View All Comments
bobdvb - Thursday, August 8, 2019 - link
I think a four compute node, 2U, dual processor Epyc Rome combined with Mellanox ConnextX-6 VPI, should be quite frisky for HPC.JohanAnandtech - Sunday, August 11, 2019 - link
"One thing I wish they would have done is added quad socket support. "Really? That is extremely small niche market with very demanding customers. Why would you expect AMD to put so much effort in an essentially dead end market?
KingE - Wednesday, August 7, 2019 - link
> While standalone compression and decompression are not real world benchmarks (at least as far as servers go), servers have to perform these tasks as part of a larger role (e.g. database compression, website optimization).Containerized apps are usually delivered via large, compressed filesystem layers. For latency sensitive-applications, e.g. scale-from-zero serverless, single- and lightly-threaded decompression performance is a larger-than-expected consideration.
RSAUser - Thursday, August 8, 2019 - link
Usually the decompression overhead is minimal there.KingE - Thursday, August 8, 2019 - link
Sure, if you can amortize it over the life of a container, or can benefit from cached pulls. Otherwise, as is fairly common in an event-based 'serverless' architecture, it's a significant contributor to long-tail latency.Thud2 - Wednesday, August 7, 2019 - link
Will socket-to-socket IF link bandwidth management allow for better dual GPU performance?wabash9000 - Thursday, August 8, 2019 - link
"The city may be built on seven hills, but Rome's 8x8-core chiplet design is a truly cultural phenomenon of the semiconductor industry."The city of Rome was actually built on 8 hills, even their celebration of the 7 hills had 8 listed. Something got confused and it was actually 8 hills. Search "QI: Series O Overseas" on youtube
Ian Cutress - Thursday, August 8, 2019 - link
That episode is consequently where my onowdge about the 7 Hills / 8 Hills comes from.abufrejoval - Sunday, August 11, 2019 - link
sic transit gloria mundi... cum youtube non scolae discimus...I learned in Latin class, first of four foreign languages I learned in school (but I know that doesn't impress anyone from Belgium with three domestic ones :-)
ZolaIII - Thursday, August 8, 2019 - link
Seams that EPYC 7702P will be a absolute workstation killer deal. Hopefully AMD won't screw up with motherboard's this time around.