AMD Zen 2 Microarchitecture Analysis: Ryzen 3000 and EPYC Rome
by Dr. Ian Cutress on June 10, 2019 7:22 PM EST- Posted in
- CPUs
- AMD
- Ryzen
- EPYC
- Infinity Fabric
- PCIe 4.0
- Zen 2
- Rome
- Ryzen 3000
- Ryzen 3rd Gen
Fetch/Prefetch
Starting with the front end of the processor, the prefetchers.
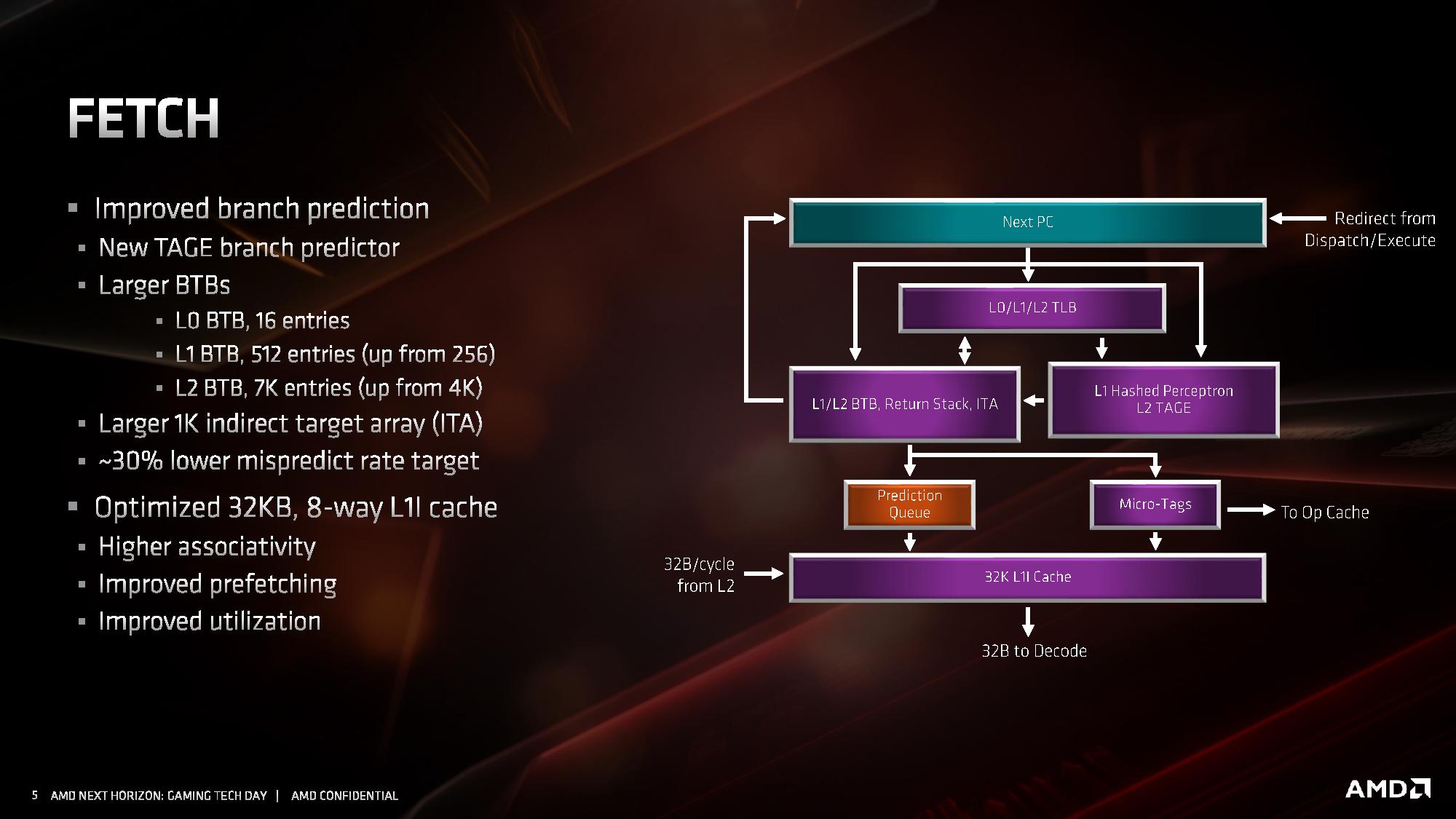
AMD’s primary advertised improvement here is the use of a TAGE predictor, although it is only used for non-L1 fetches. This might not sound too impressive: AMD is still using a hashed perceptron prefetch engine for L1 fetches, which is going to be as many fetches as possible, but the TAGE L2 branch predictor uses additional tagging to enable longer branch histories for better prediction pathways. This becomes more important for the L2 prefetches and beyond, with the hashed perceptron preferred for short prefetches in the L1 based on power.
In the front end we also get larger BTBs, to help keep track of instruction branches and cache requests. The L1 BTB has doubled in size from 256 entry to 512 entry, and the L2 is almost doubled to 7K from 4K. The L0 BTB stays at 16 entries, but the Indirect target array goes up to 1K entries. Overall, these changes according to AMD affords a 30% lower mispredict rate, saving power.
One other major change is the L1 instruction cache. We noted that it is smaller for Zen 2: only 32 KB rather than 64 KB, however the associativity has doubled, from 4-way to 8-way. Given the way a cache works, these two effects ultimately don’t cancel each other out, however the 32 KB L1-I cache should be more power efficient, and experience higher utilization. The L1-I cache hasn’t just decreased in isolation – one of the benefits of reducing the size of the I-cache is that it has allowed AMD to double the size of the micro-op cache. These two structures are next to each other inside the core, and so even at 7nm we have an instance of space limitations causing a trade-off between structures within a core. AMD stated that this configuration, the smaller L1 with the larger micro-op cache, ended up being better in more of the scenarios it tested.








216 Comments
View All Comments
nonoverclock - Wednesday, June 12, 2019 - link
It's related to platform power management.wurizen - Wednesday, June 12, 2019 - link
"Raw Memory Latency" graph shows 69ns for for 3200 and 3600 Mhz RAM. This "69ns" is irrelevant, right? Isn't the "high latency" associated with Ryzen and IF due to "Cross-CCX-Memory-Latency? This is suppose to be ~110ns at 3200 Mhz RAM as tested by PCPER/etc.... This in my experiences causes "micro-stuttering" in games like BO3/BF4/etc.... And, a "Ryzen-micro-stutter/pause" is different than a micro-stutter/pause associated with Intel. With Intel the micro-stutter/pause happens in BFV, for example, but they happen once or twice per match. With Ryzen, not only is the quality/feeling of the "micro-stutter/pause" different (seems worst), but it is constant throughout the match. One gets a feeling that it is not server-side, GPU side, nor WIndows 10 side. But, CPU-side issue... Infinity Fabric side. So, now Inifinity Fabric 2 is out. Is it 2.0 as in better? No more high latency? Is that 69ns Cross-CCX-memory latency? Why is AMD and Tech sites like Anand so... like... not talking about this?igavus - Wednesday, June 12, 2019 - link
You are misattributing things here. Your stutter is most def. not caused by memory access latency variations. For it to be visible on even an 144Hz monitor with the game running at the native rate, the differences would have to be obscenely high. That's just unrealistic.Not that it helps to determine what is causing your issues, but that's not it.
wurizen - Wednesday, June 12, 2019 - link
What?wurizen - Wednesday, June 12, 2019 - link
Maybe, you guys don't know what Cross-CCX-Memory-Latyency is... my main goal of commenting was what that SLIDE showing "Raw Memory Latency" refers to? Is it Inter-core-memory or Intra-core-memory (intra-core is the same as cross-ccx-memory)...inter-core memory is data being shuffled within the cores in a CCX module. Ryzen and Ryzen + had two CCX modules with 4 cores each, totaling 8 cores for the 2700x, as an example. If, the memory/data is traveling in the same CCX, the latency is fine and is even faster than Intel. This was true with Ryzen and Ryzen +.
The issue is when data and memory is being shuffled between the CCX modules, and when traversing the so called "Infinity Fabric." Intel uses a Ring Bus and doesn't have an equivalent measurement and data. Intel does have MESH with the x299 which is similar-ish to AMD's CCX and IF. But, Intel Mesh latency is lower (I think. But havent dug around since I dont care about it since I cant afford it)....
So... that is what Cross-CCX-memory-latency is... and that SLIDE shown on this article... WTF does that refer to? 69ns is similar to Intel Ring Bus memory latency, which have shown to be fast enough and is the standard in regards to latency that won't cause issues...
So... as PCPER tested, Ryzen Infinity Fanri 1.0 has a cross-ccx-latnecy to be around 110ns... and I stand my ground (its not bios/reinstallwindows/or windows scheduler/or user-error/or imperceptible/or a misunderstanding / or a mis-atribution (I think)) that it was the reason why I suffered "micro-pauses/stutters in some games. I had two systems at the time (3700k and R7-1700x) and so I was able to diagnose/observe/interpret what was happening....
Also.. I would like to add that the "Ryzen Micro-stutter-Pause" FEELS/LOOKS/BEHAVES different... weird, right?
deltaFx2 - Thursday, June 13, 2019 - link
You might "stand your ground" but that doesn't make it true. First of all, it's pretty clear you don't understand what you're talking about. Intel's Mesh is NOTHING like AMD's CCX. Intel Mesh is an alternative interconnect to ring bus; mesh scales better to many cores relative to ring. In theory mesh should be faster but for whatever reason intel's memory latency on skylake X parts are quite bad relative to skylake client (i.e. no bueno for gaming). I recall 70ns-ish for Skylake X vs 60ns for the Skylake client.Cross CCX memory latency should not matter unless you have shared memory across threads that span CCXs. Games don't need that many threads: 8 is overkill in many cases and each CCX can comfortably handle 8. Unless you pinned threads to cores and ran an experiment that conclusively showed that the issue was inter-ccx latency (I doubt it), your standing ground doesn't mean much. One could just as well argue that the microstutter was due to driver issues or other software/bios issues. Zen has been around for quite some time and if this was a widespread problem, we'd know.
wurizen - Friday, June 14, 2019 - link
Well, I did mention "similar-ish" of Mesh to Infinity Fabric. It's meshy. And, i guess, you get "comraderie" points for calling me out as "pretty clear you don't understand what you're talking about." That hurts, man! :("In theory... Mesh should be faster..." nice way to switch subjects, bruh. yeh, i can throw some at ya, bruh! what?
Cross-CCX-High-Memory-Latency DOES MATTER!
You know why? Because a game shuffles data randomly. It doesn't know that traversing said Data from Core 0 (residing in CCX 1) to Core 3 (in CCX 2) via Infinity Fabric means that there is a latency penalty.
Bruh
deltaFx2 - Friday, June 14, 2019 - link
Actually, no, you're wrong about the mesh. Intel has a logically unified L3 cache; i.e. any core can access any slice of the L3, or even one core can use the entire L3 for itself. AMD has a logically distributed L3 cache which means only the cores from the CCX can access its cache. You simply cannot have core 3 (CCX 0) fetch a line into CCX1's cache. The tradeoff is that the distributed L3 is much faster than the logically unified one but the logically unified one obviously offers better hit rates and does not suffer from sharing issues."Cross-CCX-High-Memory-Latency DOES MATTER!" Yes it does, no question about that. It matters when you have lock contention or shared memory that spans CCXs. In order to span CCXs, you should be using more than 8 threads (4 cores to a CCX, 2 threads per core). I don't think games are _that_ multithreaded. This article mentions a Windows 10 patch to ensure that threads get assigned to the same CCX before going to the adjacent one. It can be a problem for compute-intensive applications (y'know, real work), but games? I doubt it, and you should be able to fix it easily by pinning threads to cores in the same CCX.
deltaFx2 - Friday, June 14, 2019 - link
"shared memory that spans CCXs." -> shared DIRTY memory. i.e. core 8 writes data, core 0 wants to read. All other kinds of sharing are a non-issue. Each CCX gets a local copy of the data.wurizen - Friday, June 14, 2019 - link
Why do you keep on blabbing on about this? Are you trying to fix some sort of muscle?