AMD Zen 2 Microarchitecture Analysis: Ryzen 3000 and EPYC Rome
by Dr. Ian Cutress on June 10, 2019 7:22 PM EST- Posted in
- CPUs
- AMD
- Ryzen
- EPYC
- Infinity Fabric
- PCIe 4.0
- Zen 2
- Rome
- Ryzen 3000
- Ryzen 3rd Gen
Decode
For the decode stage, the main uptick here is the micro-op cache. By doubling in size from 2K entry to 4K entry, it will hold more decoded operations than before, which means it should experience a lot of reuse. In order to facilitate that use, AMD has increased the dispatch rate from the micro-op cache into the buffers up to 8 fused instructions. Assuming that AMD can bypass its decoders often, this should be a very efficient block of silicon.
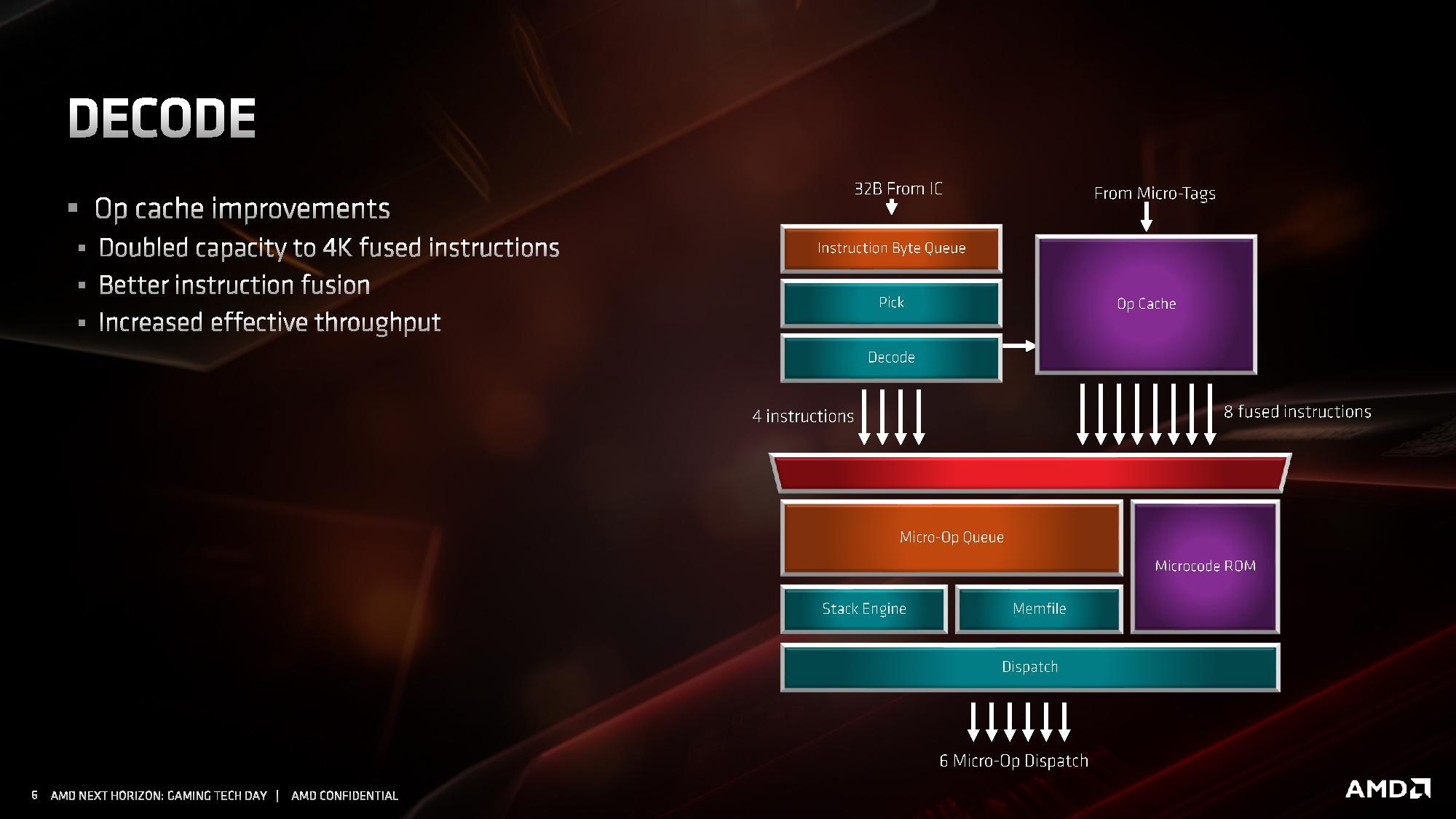
What makes the 4K entry more impressive is when we compare it to the competition. In Intel’s Skylake family, the micro-op cache in those cores are only 1.5K entry. Intel increased the size by 50% for Ice Lake to 2.25K, but that core is coming to mobile platforms later this year and perhaps to servers next year. By comparison AMD’s Zen 2 core will cover the gamut from consumer to enterprise. Also at this time we can compare it to Arm’s A77 CPU micro-op cache, which is 1.5K entry, however that cache is Arm’s first micro-op cache design for a core.
The decoders in Zen 2 stay the same, we still have access to four complex decoders (compared to Intel’s 1 complex + 4 simple decoders), and decoded instructions are cached into the micro-op cache as well as dispatched into the micro-op queue.
AMD has also stated that it has improved its micro-op fusion algorithm, although did not go into detail as to how this affects performance. Current micro-op fusion conversion is already pretty good, so it would be interesting to see what AMD have done here. Compared to Zen and Zen+, based on the support for AVX2, it does mean that the decoder doesn’t need to crack an AVX2 instruction into two micro-ops: AVX2 is now a single micro-op through the pipeline.
Going beyond the decoders, the micro-op queue and dispatch can feed six micro-ops per cycle into the schedulers. This is slightly imbalanced however, as AMD has independent integer and floating point schedulers: the integer scheduler can accept six micro-ops per cycle, whereas the floating point scheduler can only accept four. The dispatch can simultaneously send micro-ops to both at the same time however.








216 Comments
View All Comments
JohnLook - Monday, June 10, 2019 - link
@Ian Cutress Are you sure the Io dies are on TSMC's 14 & 12 nm processes ?all info so far was that they were on GloFo's 14 nm ...
Ian Cutress - Monday, June 10, 2019 - link
Sorry, glofo 14 and 12. Matisse IO die is Glofo 12nm. We triple confirmed.JohnLook - Monday, June 10, 2019 - link
Thanks :-)scineram - Tuesday, June 11, 2019 - link
It still says Epyc is TSMC.John_M - Tuesday, June 11, 2019 - link
It would be nice if the article was updated as not everyone reads the comments section and AnandTech articles do often get cited in Wikipedia articles.Smell This - Wednesday, June 12, 2019 - link
I feel safe in saying that Wiki-Dom will be right on it . . .;-)
So __ those little white lines are the Infinity Scalable Data Fabric (SDF) and the Infinity Scalable Control Fabric (SCF), connecting "Core" chiplets to the I/O core.
"The SDF might have dozens of connecting points hooking together things such as PCIe PHYs, memory controllers, USB hub, and the various computing and execution units."
"The SDF is a superset of what was previously HyperTransport. The SCF is a complementary plane that handles the transmission ..."
https://en.wikichip.org/wiki/amd/infinity_fabric
Of course, I counted them (rolling eyes at myself), and determined there were 32 connecting a single core chiplet to the I/O core. I'm smelling a rational relationship between those 32, and other such stuff. Are the number of IF links a proprietary secret to AMD?
Yah know? It would be a nice 'get' if a tech writer interviewed someone in that former Sea Micro bunch, and spilled a few beans . . .
Smell This - Wednesday, June 12, 2019 - link
Might be 36 ... LOL
Smell This - Wednesday, June 12, 2019 - link
Could be 42- or 46 IF links on the right(I'll stop obsessing)
sweetca - Thursday, June 13, 2019 - link
I don't understand anything you said 🙂Smell This - Sunday, June 16, 2019 - link
I was (am) trolling Ian/AT for a **Deep(er) Dive** on the Infinity Fabric -- its past, and its future. The EPYC Rome processors have 8 "Core" chiplets connecting to the I/O core. Right? Those 'little white lines' (32- to 46?) from each chiplet, presumably, scale to ... infinity?AMD purchased SeaMicro 7 years ago as the "Freedom Fabric" platform was developed. Initially the SM15000 'stitched' together 512 compute cores, 160 gigabits of I/O networking and 5+ petabytes of storage to form a 'very-high-density server.'
And then . . . they went dark.
https://www.anandtech.com/show/9170/amd-exits-dens...
(see the last comment on that link)