AMD Zen 2 Microarchitecture Analysis: Ryzen 3000 and EPYC Rome
by Dr. Ian Cutress on June 10, 2019 7:22 PM EST- Posted in
- CPUs
- AMD
- Ryzen
- EPYC
- Infinity Fabric
- PCIe 4.0
- Zen 2
- Rome
- Ryzen 3000
- Ryzen 3rd Gen
Cache and Infinity Fabric
If it hasn’t been hammered in already, the big change in the cache is the L1 instruction cache which has been reduced from 64 KB to 32 KB, but the associativity has increased from 4-way to 8-way. This change enabled AMD to increase the size of the micro-op cache from 2K entry to 4K entry, and AMD felt that this gave a better performance balance with how modern workloads are evolving.
The L1-D cache is still 32KB 8-way, while the L2 cache is still 512KB 8-way. The L3 cache, which is a non-inclusive cache (compared to the L2 inclusive cache), has now doubled in size to 16 MB per core complex, up from 8 MB. AMD manages its L3 by sharing a 16MB block per CCX, rather than enabling access to any L3 from any core.
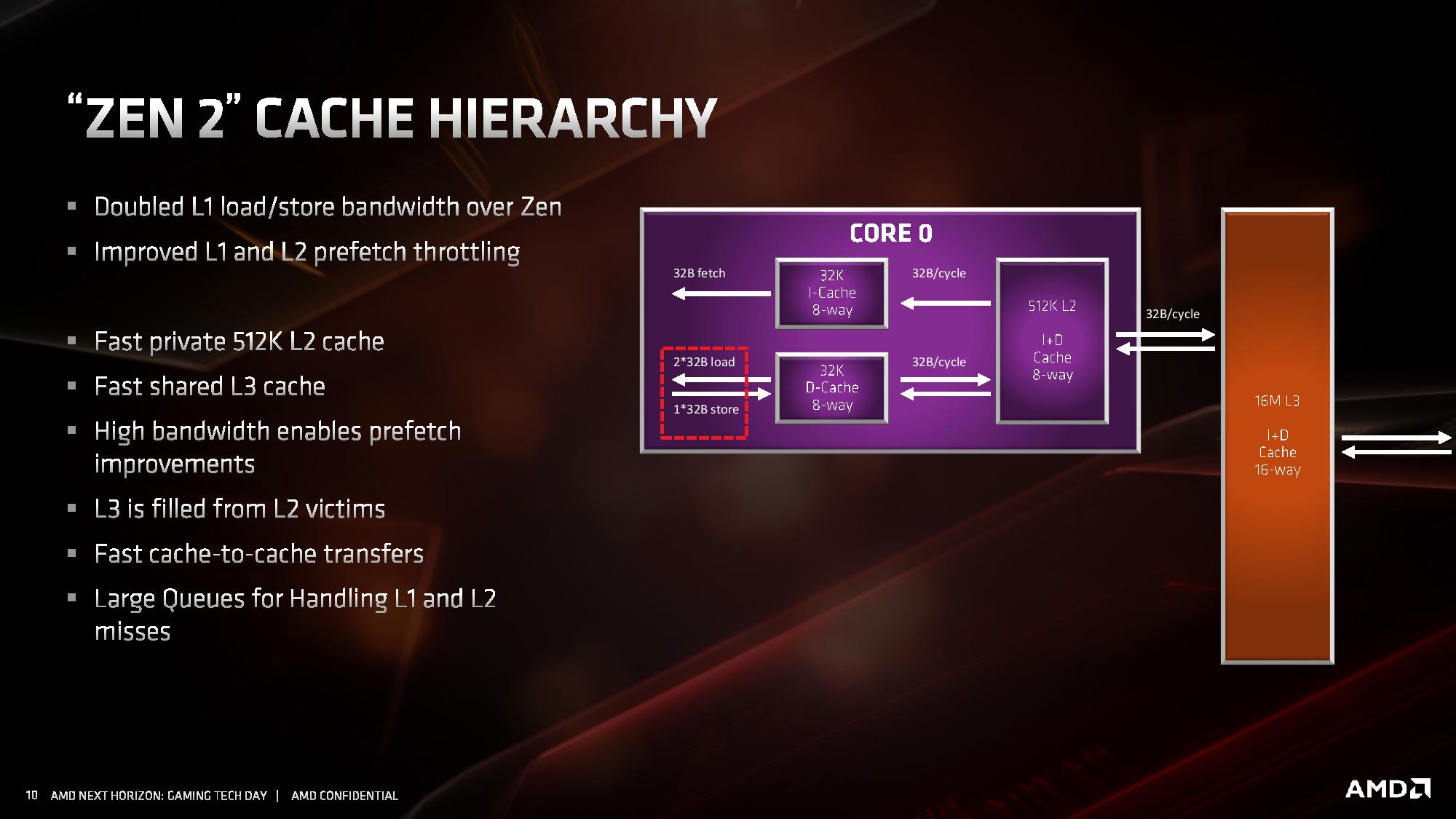
Because of the increase in size of the L3, latency has increased slightly. L1 is still 4-cycle, L2 is still 12-cycle, but L3 has increased from ~35 cycle to ~40 cycle (this is a characteristic of larger caches, they end up being slightly slower latency; it’s an interesting trade off to measure). AMD has stated that it has increased the size of the queues handling L1 and L2 misses, although hasn’t elaborated as to how big they now are.
Infinity Fabric
With the move to Zen 2, we also move to the second generation of Infinity Fabric. One of the major updates with IF2 is the support of PCIe 4.0, and thus the increase of the bus width from 256-bit to 512-bit.

Overall efficiency of IF2 has improved 27% according to AMD, leading to a lower power per bit. As we move to more IF links in EPYC, this will become very important as data is transferred from chiplet to IO die.
One of the features of IF2 is that the clock has been decoupled from the main DRAM clock. In Zen and Zen+, the IF frequency was coupled to the DRAM frequency, which led to some interesting scenarios where the memory could go a lot faster but the limitations in the IF meant that they were both limited by the lock-step nature of the clock. For Zen 2, AMD has introduced ratios to the IF2, enabling a 1:1 normal ratio or a 2:1 ratio that reduces the IF2 clock in half.
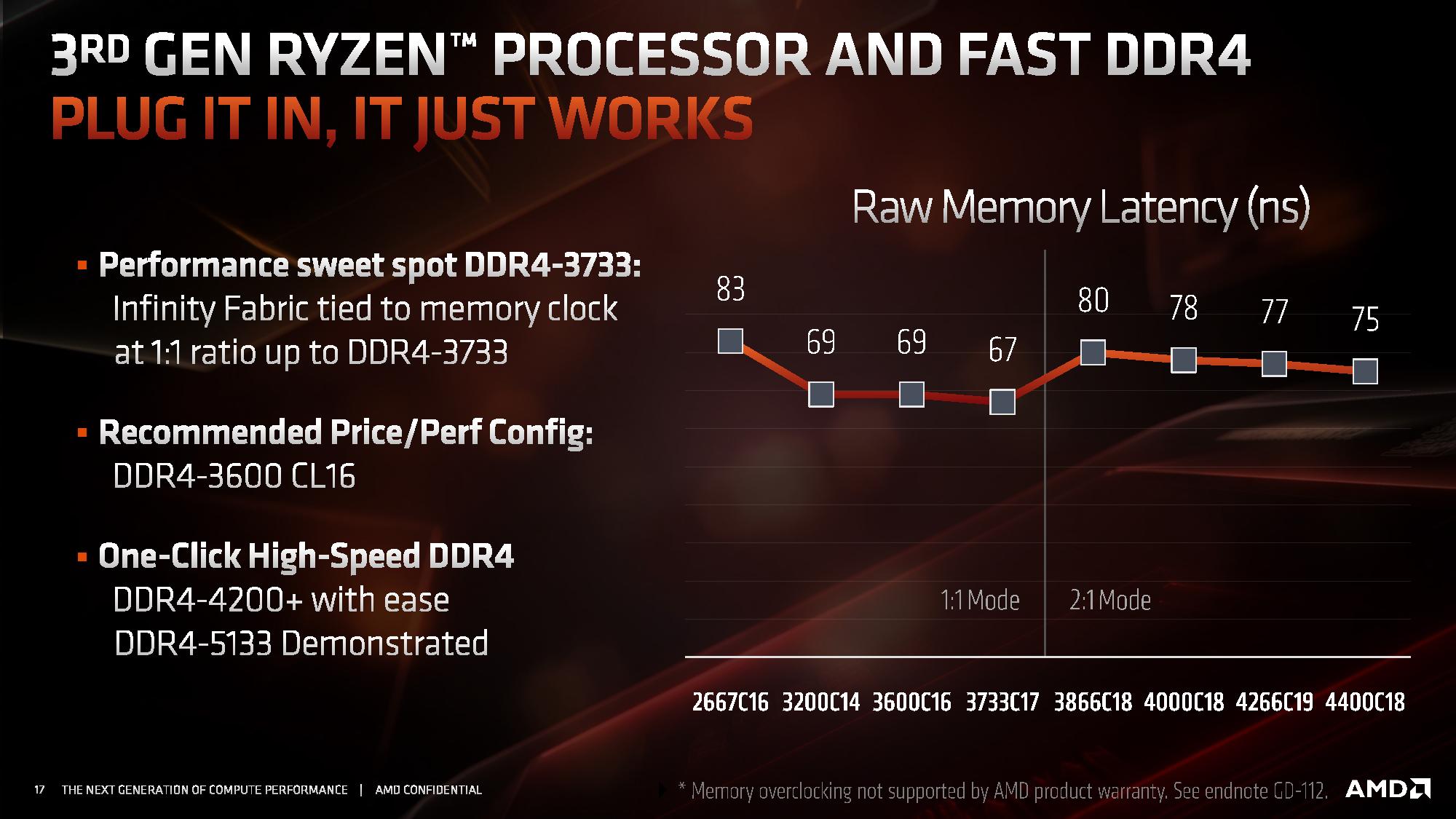
This ratio should automatically come into play around DDR4-3600 or DDR4-3800, but it does mean that IF2 clock does reduce in half, which has a knock on effect with respect to bandwidth. It should be noted that even if the DRAM frequency is high, having a slower IF frequency will likely limit the raw performance gain from that faster memory. AMD recommends keeping the ratio at a 1:1 around DDR4-3600, and instead optimizing sub-timings at that speed.








216 Comments
View All Comments
Thunder 57 - Sunday, June 16, 2019 - link
It appears they traded half the L1 instruction cache to double the uop cache. They doubled the associativity to keep the same hit rate but it will hold fewer instructions. However, the micro-op cache holds already decoded instructions and if there is a hit there it saves a few stages in the pipeline for decoding, which saves power and increases performance.phoenix_rizzen - Tuesday, June 11, 2019 - link
From the article:"Zen 2 will offer greater than a >1.25x performance gain at the same power,"
I don't think that means what you meant. :) 1.25x gain would be 225% or over 2x the performance. I think you meant either:
"Zen 2 will offer greater than a 25% performance gain at the same power,"
or maybe:
"Zen 2 will offer greater than 125% performance at the same power,"
or possibly:
"Zen 2 will offer greater than 1.25x performance at the same power,"
phoenix_rizzen - Tuesday, June 11, 2019 - link
From the article:"With Matisse staying in the AM4 socket, and Rome in the EPYC socket,"
The server socket name is SP3, not EPYC, so this should read:
"With Matisse staying in the AM4 socket, and Rome in the SP3 socket,"
phoenix_rizzen - Tuesday, June 11, 2019 - link
From the article:"This also becomes somewhat complicated for single core chiplet and dual core chiplet processors,"
core is superfluous here. The chiplets are up to 8-core. You probably mean "single chiplet and dual chiplet processors".
scineram - Wednesday, June 12, 2019 - link
No, becausethere is no single chiplet. It is the core chiplet that is either 1 or 2 in number.phoenix_rizzen - Tuesday, June 11, 2019 - link
From the article:"all of this also needs to be taken into consideration as provide the optimal path for signaling"
"as" should be "to"
thesavvymage - Wednesday, June 12, 2019 - link
A 1.25x gain is the exact same as a 25% performance gain, it doesnt meant 225% as you stateddsplover - Tuesday, June 11, 2019 - link
So in other words Anadtech no longer receives engineering samples but tells us what everyone else is saying.Still love coming here as reviews are good, but boy oh boy yuze guys sure slipped down the ladder.
Bring back Anand Shimpli.
Korguz - Wednesday, June 12, 2019 - link
the do still get engineering samples... but usually cpus...not likely.. hes working for apple now....
coburn_c - Wednesday, June 12, 2019 - link
What the heck is UEFI CPPC2?