AMD Zen 2 Microarchitecture Analysis: Ryzen 3000 and EPYC Rome
by Dr. Ian Cutress on June 10, 2019 7:22 PM EST- Posted in
- CPUs
- AMD
- Ryzen
- EPYC
- Infinity Fabric
- PCIe 4.0
- Zen 2
- Rome
- Ryzen 3000
- Ryzen 3rd Gen
Floating Point
The key highlight improvement for floating point performance is full AVX2 support. AMD has increased the execution unit width from 128-bit to 256-bit, allowing for single-cycle AVX2 calculations, rather than cracking the calculation into two instructions and two cycles. This is enhanced by giving 256-bit loads and stores, so the FMA units can be continuously fed. AMD states that due to its energy aware scheduling, there is no predefined frequency drop when using AVX2 instructions (however frequency may be reduced dependent on temperature and voltage requirements, but that’s automatic regardless of instructions used)
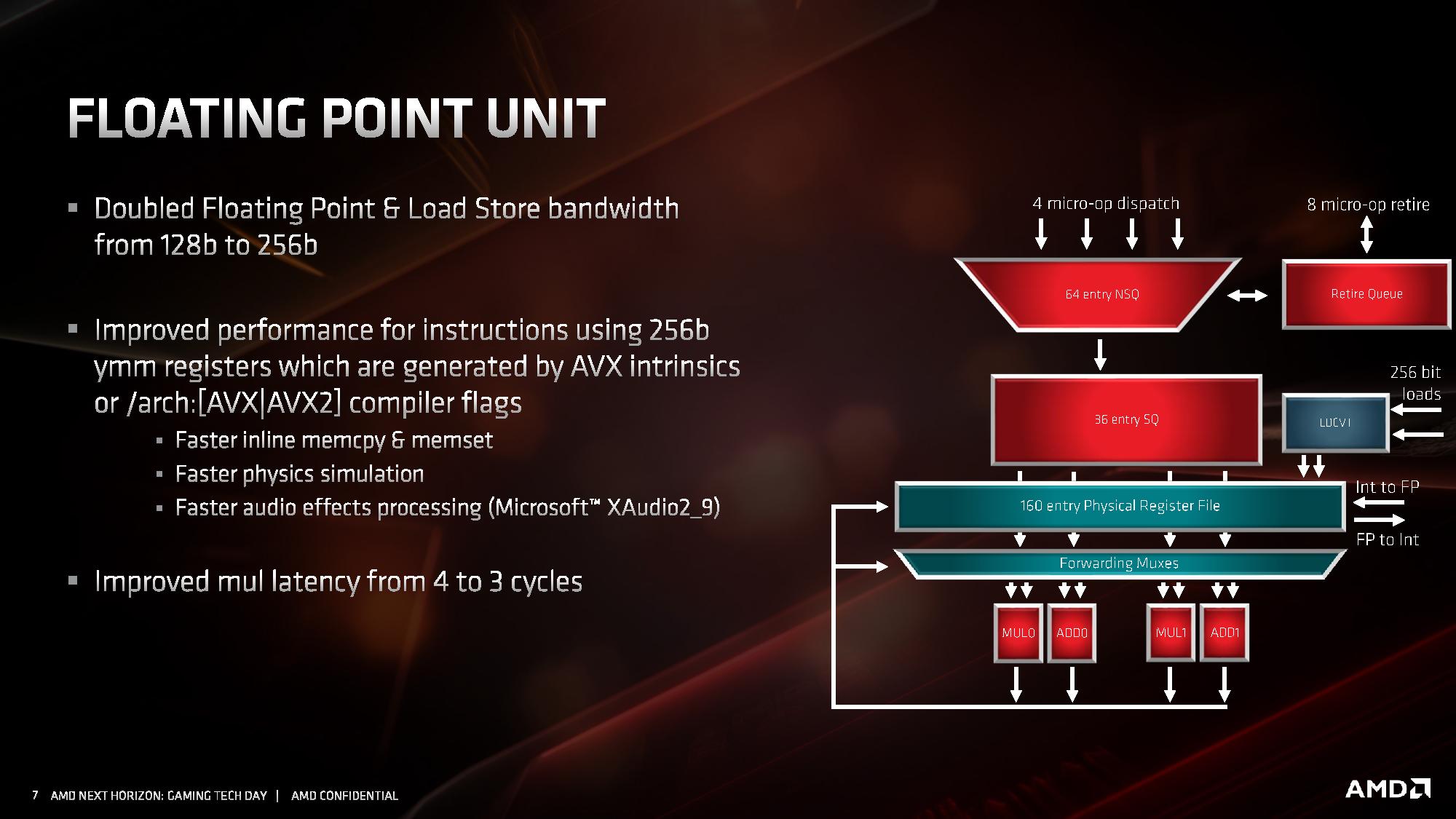
In the floating point unit, the queues accept up to four micro-ops per cycle from the dispatch unit which feed into a 160-entry physical register file. This moves into four execution units, which can be fed with 256b data in the load and store mechanism.
Other tweaks have been made to the FMA units than beyond doubling the size – AMD states that they have increased raw performance in memory allocations, for repetitive physics calculations, and certain audio processing techniques.
Another key update is decreasing the FP multiplication latency from 4 cycles to 3 cycles. That is quite a significant improvement. AMD has stated that it is keeping a lot of the detail under wraps, as it wants to present it at Hot Chips is August. We’ll be running a full instruction analysis for our reviews on July 7th.








216 Comments
View All Comments
mikato - Tuesday, June 11, 2019 - link
Hehe, yeah I saw that. That was a good one for the marketing team or whoever makes the slides.Atari2600 - Wednesday, June 12, 2019 - link
No, for each of those line items they should have said "Intel only"zalves - Tuesday, June 11, 2019 - link
I really don't understand how one can compare these AMD CPU's with Intel's HEDT, they lack PCIe Lanes and don't support quad-channel memory. And that a huge deal breaker for anyone that wants and needs some serious IO and multi tasking.TheUnhandledException - Tuesday, June 11, 2019 - link
Well that is what Threadripper is for. Can't wait to see the 3000 series Threadrippers.John_M - Tuesday, June 11, 2019 - link
So, 5th generation EPYC codename is going to be either Turin, Bolognia or Florence as Palermo has already been used for Sempron.John_M - Tuesday, June 11, 2019 - link
*that's Bologna, of course. It would be nice to be able to edit posts for typos.WaltC - Tuesday, June 11, 2019 - link
Great read!John_M - Tuesday, June 11, 2019 - link
What is the advantage in halving the L1 instruction cache? Was the change forced by the doubling of its associativity? According to the (I suspect somewhat oversimplified) Wikipedia article on CPU Cache, doubling the associativity increases the probability of a hit by about the same amount as doubling the cache size, but with more complexity. So how is this Zen2 configuration better than that in Zen and Zen+?John_M - Tuesday, June 11, 2019 - link
Ah! It's sort of explained at the bottom of page 7. I had glossed over that because the first two paragraphs were too technical for my understanding. I see that it was halved to make room for something else to be made bigger, which on balance seems to be a successful trade off.arnd - Wednesday, June 12, 2019 - link
More importantly, 32K 8-way is a sweet spot for an L1 cache. This is what AMD is using for the D$ already and what all modern Intel L1 caches (both I and D) are. With eight ways, this is the largest size you can have for a non-aliasing virtually indexed cache using the 4KB page size of the x86 architecture. Having more than eight ways has diminishing returns, so going beyond 32KB requires extra complexity for dealing with aliasing or physically indexed caches like the L2.