The NVIDIA GeForce RTX 2070 Founders Edition Review: Mid-Range Turing, High-End Price
by Nate Oh on October 16, 2018 9:00 AM ESTCompute & Synthetics
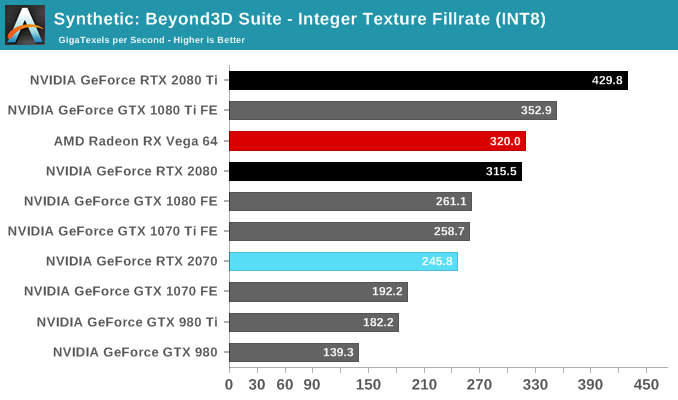
Shifting gears, we'll look at the compute and synthetic aspects of the RTX 2070. Though it has its own GPU in the form of TU106, the hardware resources at hand are similar in progression to what we've seen in TU102 and TU104.
Starting off with GEMM tests, the RTX 2070's tensor cores are pulled into action with half-precision matrix multiplication, though using binaries originally compiled for Volta. Because Turing is backwards compatible and in the same compute capability family as Volta (sm_75 compared to Volta's sm_70), the benchmark continues to work out-of-the-box, though without any Turing optimizations.
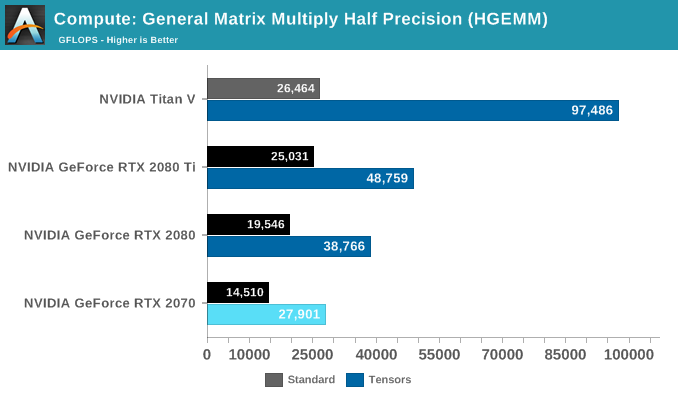
At reference specifications, peak theoretical tensor throughput is around 107.6 TFLOPS for the RTX 2080 Ti, 80.5 TFLOPS for the RTX 2080, and 59.7 TFLOPS for the RTX 2070. Unlike the 89% efficiency with the Titan V's 97.5 TFLOPS, the RTX cards are essentially at half that level, with around 47%, 48%, and 45% efficiency for the RTX 2080 Ti, 2080, and 2070 respectively. A Turing-optimized binary should bring that up, though it is possible that the GeForce RTX cards may not be designed for efficient tensor FP16 operations as opposed to the INT dot-product acceleration. After all, the GeForce RTX cards are for consumers and ostensibly intended for inferencing rather than training, which is the reasoning for the new INT support in Turing tensor cores.
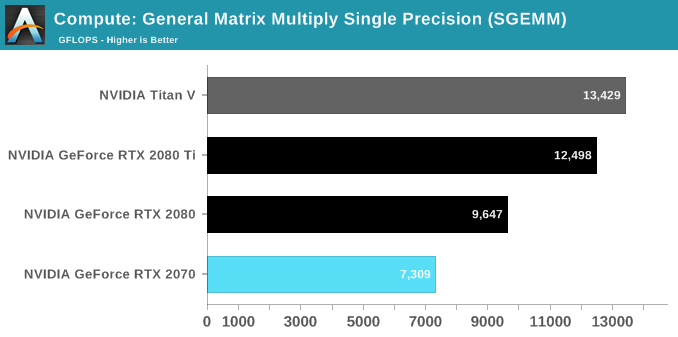
In terms of SGEMM efficiency though, the RTX 2070 is hitting a ridiculous 97% of its touted 7.5 TFLOPS, though to be fair the reference specifications here are done manually rather with a reference vBIOS. The other two GeForce RTX cards are at similar 90+% levels of efficiency, though a GEMM test like this is specifically designed for maximum utilization.
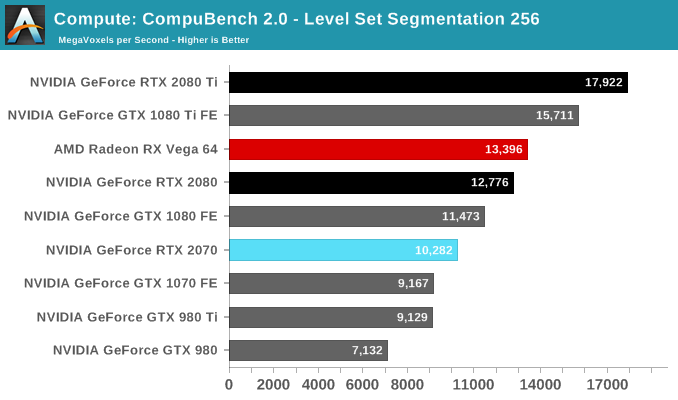

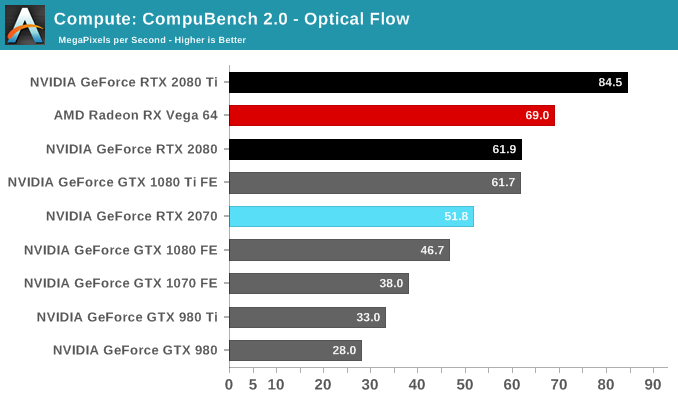
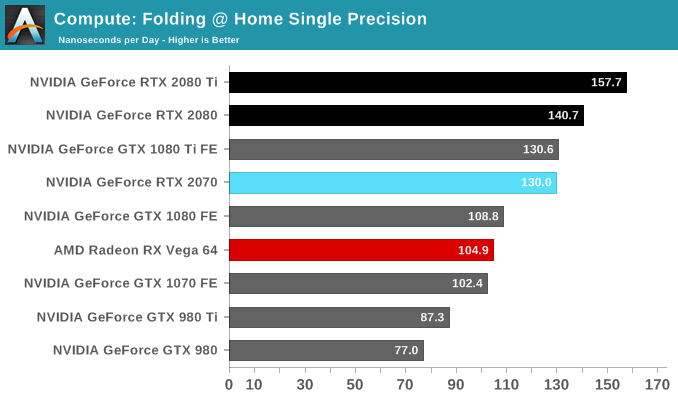
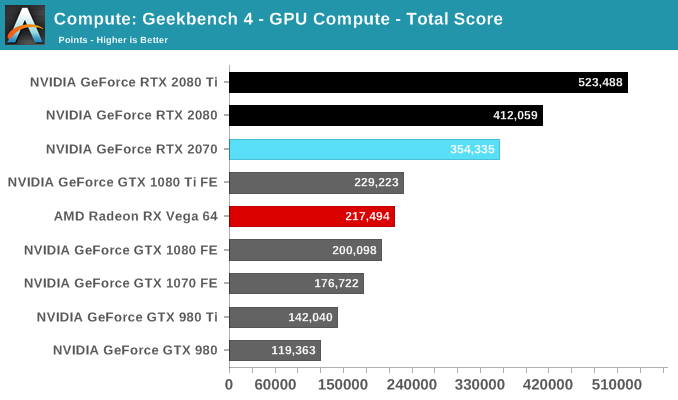
The breakdown of the GB4 subscores seems to reveal a similar uplift like we spotted with the Titan V, which had scored in excess of 509,000 points. We'll have to investigate further but Turing and Volta are clearly accelerating some of these workloads beyond what was capable in Pascal and Maxwell.
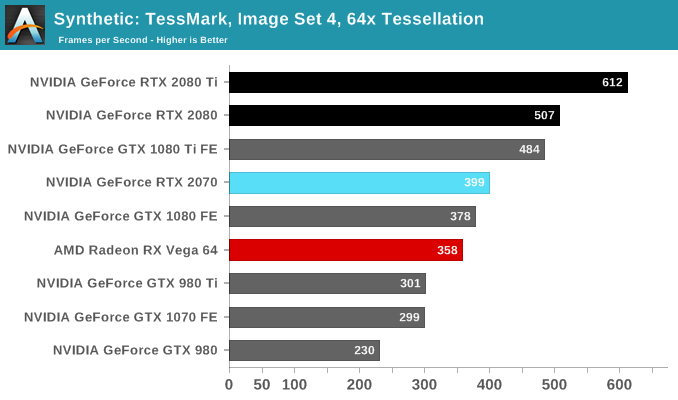
Given that TU106 has 75% of the hardware resources of TU104, the tessellation performance is in line with expectrations. For reference, we noted earlier that the Titan V scored 703 while the Titan Xp scored 604.








121 Comments
View All Comments
ThanosPAS - Saturday, November 10, 2018 - link
Does 2070 worth it vs 1070 for its Tensor cores? I would utilize the card on machine learning. In Final Words, this wasn't covered. It seems to me that 2070 is the cheapest solution in rder to get dedicated Tensor cores, which if I am not mistaken make a great portion of difference in the computational performance between these two cards. Opinions?