Intel's 10nm Cannon Lake and Core i3-8121U Deep Dive Review
by Ian Cutress on January 25, 2019 10:30 AM ESTStock CPU Performance: Rendering Tests
Rendering is often a key target for processor workloads, lending itself to a professional environment. It comes in different formats as well, from 3D rendering through rasterization, such as games, or by ray tracing, and invokes the ability of the software to manage meshes, textures, collisions, aliasing, physics (in animations), and discarding unnecessary work. Most renderers offer CPU code paths, while a few use GPUs and select environments use FPGAs or dedicated ASICs. For big studios however, CPUs are still the hardware of choice.
All of our benchmark results can also be found in our benchmark engine, Bench.
Corona 1.3: Performance Render
An advanced performance based renderer for software such as 3ds Max and Cinema 4D, the Corona benchmark renders a generated scene as a standard under its 1.3 software version. Normally the GUI implementation of the benchmark shows the scene being built, and allows the user to upload the result as a ‘time to complete’.
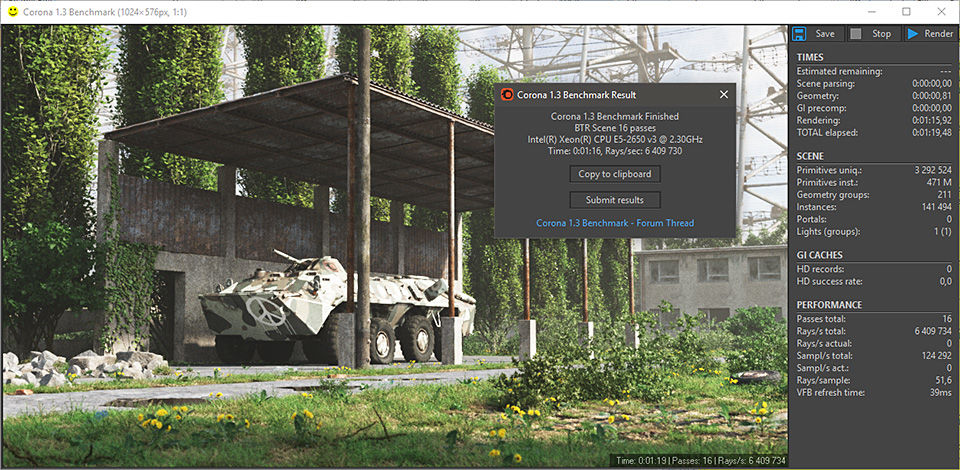
We got in contact with the developer who gave us a command line version of the benchmark that does a direct output of results. Rather than reporting time, we report the average number of rays per second across six runs, as the performance scaling of a result per unit time is typically visually easier to understand.
The Corona benchmark website can be found at https://corona-renderer.com/benchmark
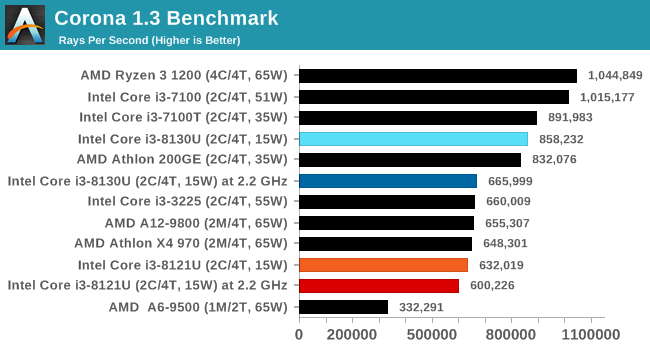
Corona is an AVX2 benchmark, and it would appear that the Cannon Lake CPU can't take full advantage of the functionality. There's still a 10% difference at fixed frequency.
Blender 2.79b: 3D Creation Suite
A high profile rendering tool, Blender is open-source allowing for massive amounts of configurability, and is used by a number of high-profile animation studios worldwide. The organization recently released a Blender benchmark package, a couple of weeks after we had narrowed our Blender test for our new suite, however their test can take over an hour. For our results, we run one of the sub-tests in that suite through the command line - a standard ‘bmw27’ scene in CPU only mode, and measure the time to complete the render.
Blender can be downloaded at https://www.blender.org/download/
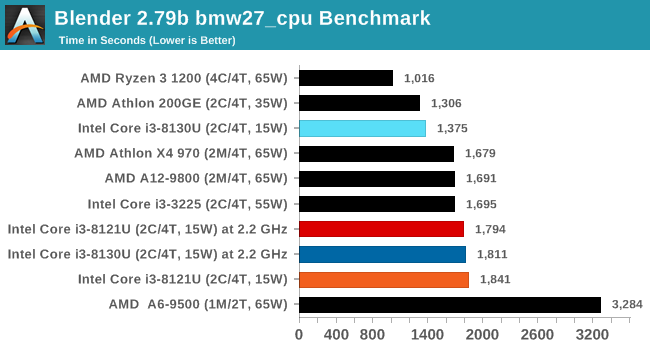
Blender also uses an AVX2 code path, and we see that the CNL processor scored worse at stock settings than at fixed frequency settings. Again, this is likely due to a power or thermal issue.
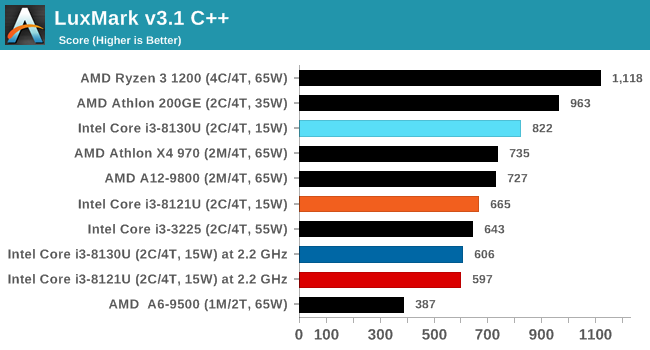
LuxMark v3.1: LuxRender via Different Code Paths
As stated at the top, there are many different ways to process rendering data: CPU, GPU, Accelerator, and others. On top of that, there are many frameworks and APIs in which to program, depending on how the software will be used. LuxMark, a benchmark developed using the LuxRender engine, offers several different scenes and APIs.
Taken from the Linux Version of LuxMark
In our test, we run the simple ‘Ball’ scene on both the C++ and OpenCL code paths, but in CPU mode. This scene starts with a rough render and slowly improves the quality over two minutes, giving a final result in what is essentially an average ‘kilorays per second’.
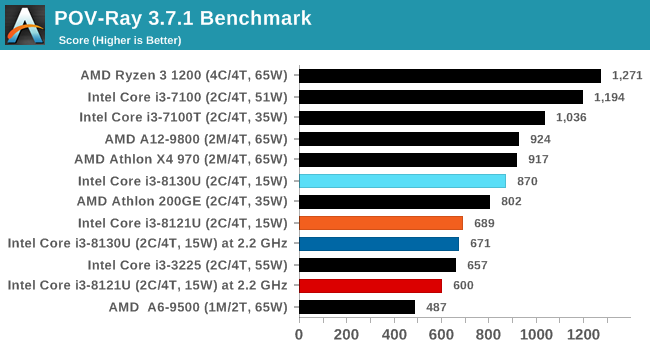
POV-Ray 3.7.1: Ray Tracing
The Persistence of Vision ray tracing engine is another well-known benchmarking tool, which was in a state of relative hibernation until AMD released its Zen processors, to which suddenly both Intel and AMD were submitting code to the main branch of the open source project. For our test, we use the built-in benchmark for all-cores, called from the command line.
POV-Ray can be downloaded from http://www.povray.org/








129 Comments
View All Comments
qcmadness - Saturday, January 26, 2019 - link
I am more curious on the manufacturing node. Zen (14 / 12nm from GF) has 12 metal layers. Cannon Lake has 13 metal layers, with 3 quad-patterning and 2 dual patterning. How would these impact the yield and manufacturing time of production? I think the 3 quad-patterning process will hurt Intel in the long run.KOneJ - Sunday, January 27, 2019 - link
More short-run I would say actually. EUV is coming to simplify and homogenize matters. This is a patch job. Unfortunately, PL analysis and comparison is not an apples-to-apples issue as there are so many facets to implementation in various design stages. A broader perspective that encompasses the overall aspects and characteristics is more relevant IMHO. It's like comparing a high-pressure FI SOHC motor with a totally unrelated low-pressure FI electrically-spooling DOHC motor of similar displacement. While arguing minutiae about design choices is interesting to satisfy academic curiosity, it's ultimately the reliability, power-curve and efficiency that people care about. Processors are much the same. As a side note, I think it's the attention to all these facets and stages that has given Jim Keller such consistent success. Intel's shaping up for a promising long-term. The only question there is where RISC designs and AMD will be when the time comes. HSA is coming, but it will be difficult due to the inherent programming challenges. Am curious to see where things are in ten or fifteen years.eastcoast_pete - Sunday, January 27, 2019 - link
Good point and question! With the GPU functions apparently simply not compatible with Intel's 10 nm process, does anyone here know if any GPUs out there that use quad-patterning at all?anonomouse - Sunday, January 27, 2019 - link
@Ian or @Andrei Is dealII missing from the spec2006fp results table for some reason? Is this just a typo/oversight, or is there some reason it's being omitted?KOneJ - Sunday, January 27, 2019 - link
Great write up, but isn't this backwards on the third page?"a 2-input NAND logic cell is much smaller than a complex scan flip-flop logic cell"
"90.78 MTr/mm^2 for NAND2 gates and 115.74 MTr/mm^2 for Scan Flip Flops"
NAND cell is smaller than flip-flop cell, but there is more flip-flop than NAND in a square millimeter?
Or am I missing something?
Rudde - Sunday, January 27, 2019 - link
A NAND logic cell consists of 2 transistors, while a Scan flip flop logic cell can consist of different count of transistors depending on where it is used. If I remeber correctly, Intel uses 8, 10 and 12 transistor designs.That gives 45.39 million NAND cells per mm² (basically SRAM) and ~12 million flip-flop cells.
The NAND cell is smaller because it consists of fewer transistors.
KOneJ - Sunday, January 27, 2019 - link
It would be great if you guys could get a CNL sample in the hands of Agner Fog. He might be able to answer some of the micro-architecture questions through his tests.dragosmp - Sunday, January 27, 2019 - link
Awesome review, great in depth content and well explained. Considering the amount of work this entailed, it's clear why these reviews don't happen every day. Thanksdragosmp - Sunday, January 27, 2019 - link
I'll just add...many folks are saying AMD should kick arse. They should, but Intel has been in this situation before - they had messed up the 90nm process; probably not quite as bad as the chips to be unusable, but it opened the door to AMD and its Athlon 64. What did AMD do? Messed it up in turn with slow development and poor design choices. Hopefully they'll capitalize this time so that we get an actual dupoloy, rather than the monopoly on performance we had since Intel's 65nm chips.eva02langley - Sunday, January 27, 2019 - link
Euh... You mean this...?https://www.youtube.com/watch?v=osSMJRyxG0k
Anti-competitive tactics? They bought the OEM support to prevent competition.
And, all lately, this came up...
https://www.tomshardware.com/news/msi-ceo-intervie...
"Relationship with Intel: Chiang told us that, given Intel's strong support during the shortage, it would be awkward to tell Intel if he chose to come out with an AMD-powered product. "It's very hard for us to tell them 'hey, we don't want to use 100 percent Intel,' because they give us very good support," he said. He did not, however, make any claims that Intel had pressured him or the company."
Yeah right, Intel is winning because they have better tech... /sarcasm