The NVIDIA Titan V Deep Learning Deep Dive: It's All About The Tensor Cores
by Nate Oh on July 3, 2018 10:15 AM ESTRevisiting Volta: How to Accelerate Deep Learning
While we’ve gone over Volta’s distinguishing characteristics several times now, the marquee addition of tensor cores somewhat overshadows all the other changes that supplement or outright support tensor core usage. For one, as we've already seen, it's tightly tied into the improved SIMT model with Volta's independent thread scheduling and collective groups.
Mixed Precision: Making FP16 Work for Deep Learning
Ultimately, Volta’s deep learning prowess is built on utilizing half precision (IEEE-754 FP16) rather than single precision (FP32) for deep learning training. First supported by cuDNN 3 and implemented in Tegra X1’s Maxwell cores, native half precision compute was fully introduced with Pascal as “Pseudo FP16”, where FP32 ALUs could instead process pairs of FP16 instructions for theoretically double FP16 throughput per clock. We've actually seen this in how tensor cores deal with matrix fragments in the register, as the two FP16 input matrices are gathered in 8 elements of FP16x2, or 16 FP16 elements.
In terms of FP32 versus FP16, because the single precision format ‘describes’ more data than half precision, operations are more computationally intensive and more memory storage/bandwidth is needed to house and transfer the data, in turn consuming more power. So the successful usage of lower precision in compute has been a poor man’s holy grail of sorts, targeting applications where higher precision is unnecessary.
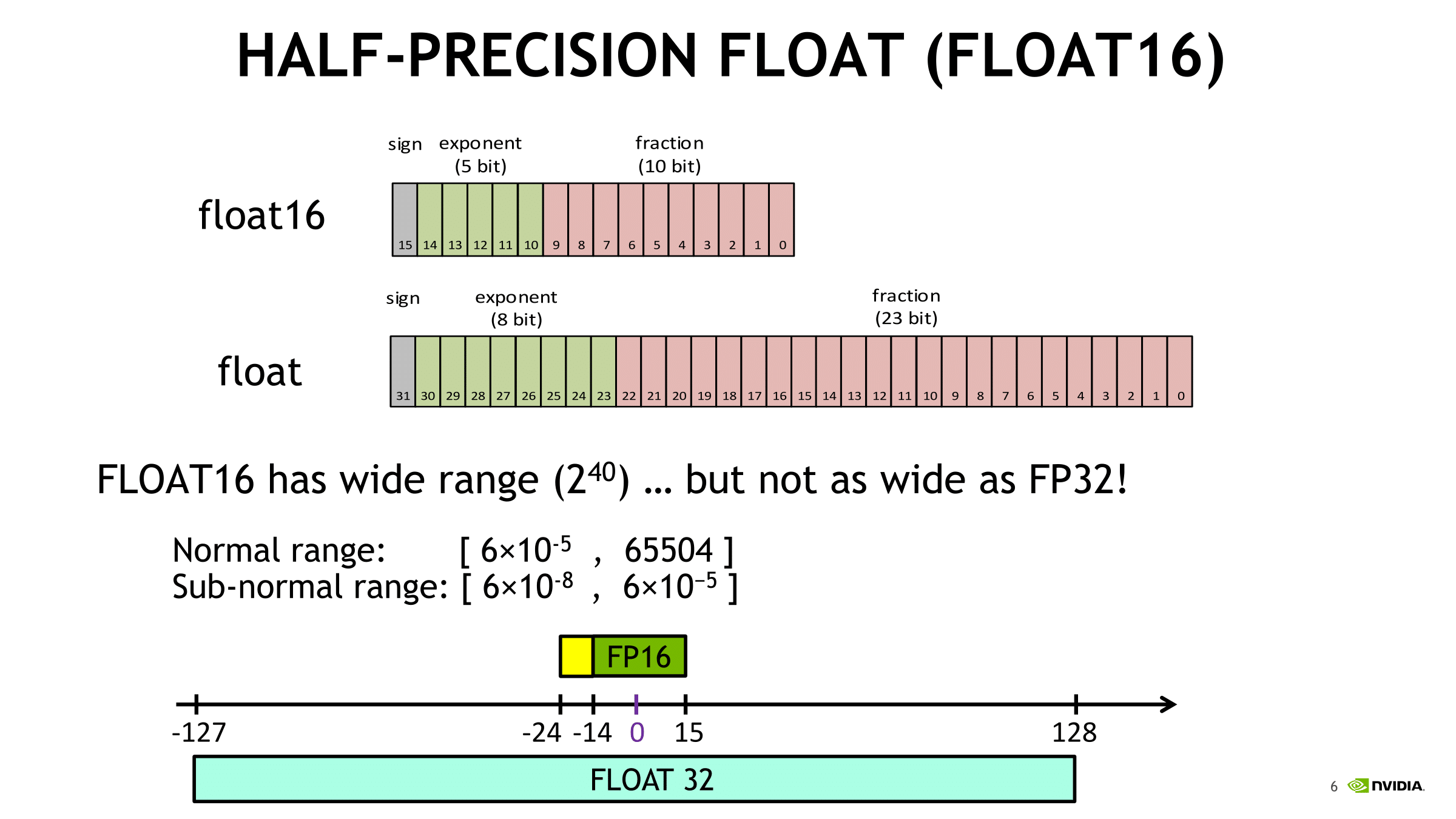
Aside from API/compiler/framework support, the perennial drawback for deep learning is the (unsurprising) loss of precision in using FP16 data types, where the training process would not be accurate enough and so the model cannot converge. Enter mixed precision.

To be fair, NVIDIA has wheeled out the 'mixed precision' term before in very similar context, in discussing Pascal's fast FP16 (for GP100) and DP4A/DP2A integer dot product operations (for GP102, GP104, and GP106 GPUs). Back then, the focus was on inference, and very much like Titan V's 'deep learning TFLOPS,' Titan X (Pascal) launched with a "44 TOPS (new deep learning inferencing instruction)." The new instructions performed integer dot products on 4-element 8-bit vectors or 2-element 8-bit/16-bit vectors, resulting in a 32-bit integer product that could be accumulated with other 32-bit integers.
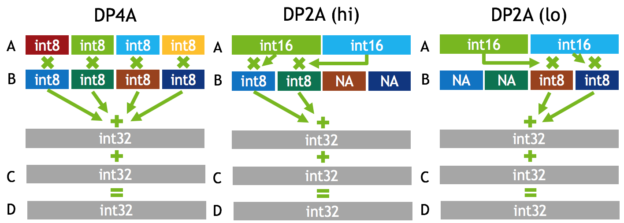
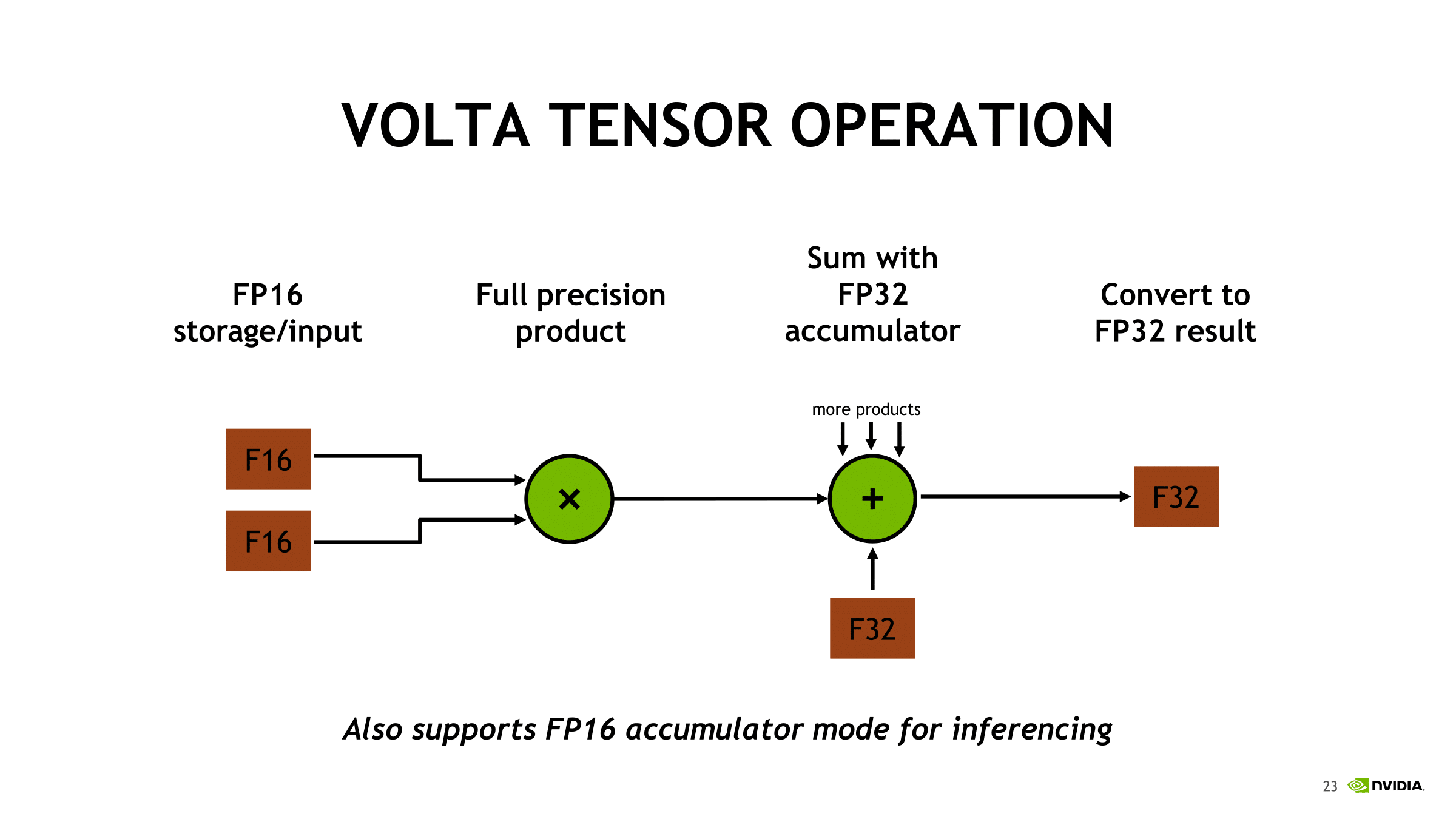
So for mixed precision in Volta, there are several more wrinkles. First is that important precision-sensitive data like master weights are stored as FP32. The second is tensor cores, where mixed precision training describes how two half precision input matrices are multiplied to get a single precision product, which is then accumulated into a single precision sum. NVIDIA has stated that the result is converted back to half precision before being written into memory, though how this happens is not exactly clear. For inferencing purposes though, the tensor core will instead accumulate the result into a half precision sum. Ultimately, when using half precision format, less data is needed in the registers and memory, which helps compensate for the data in very large matrices.
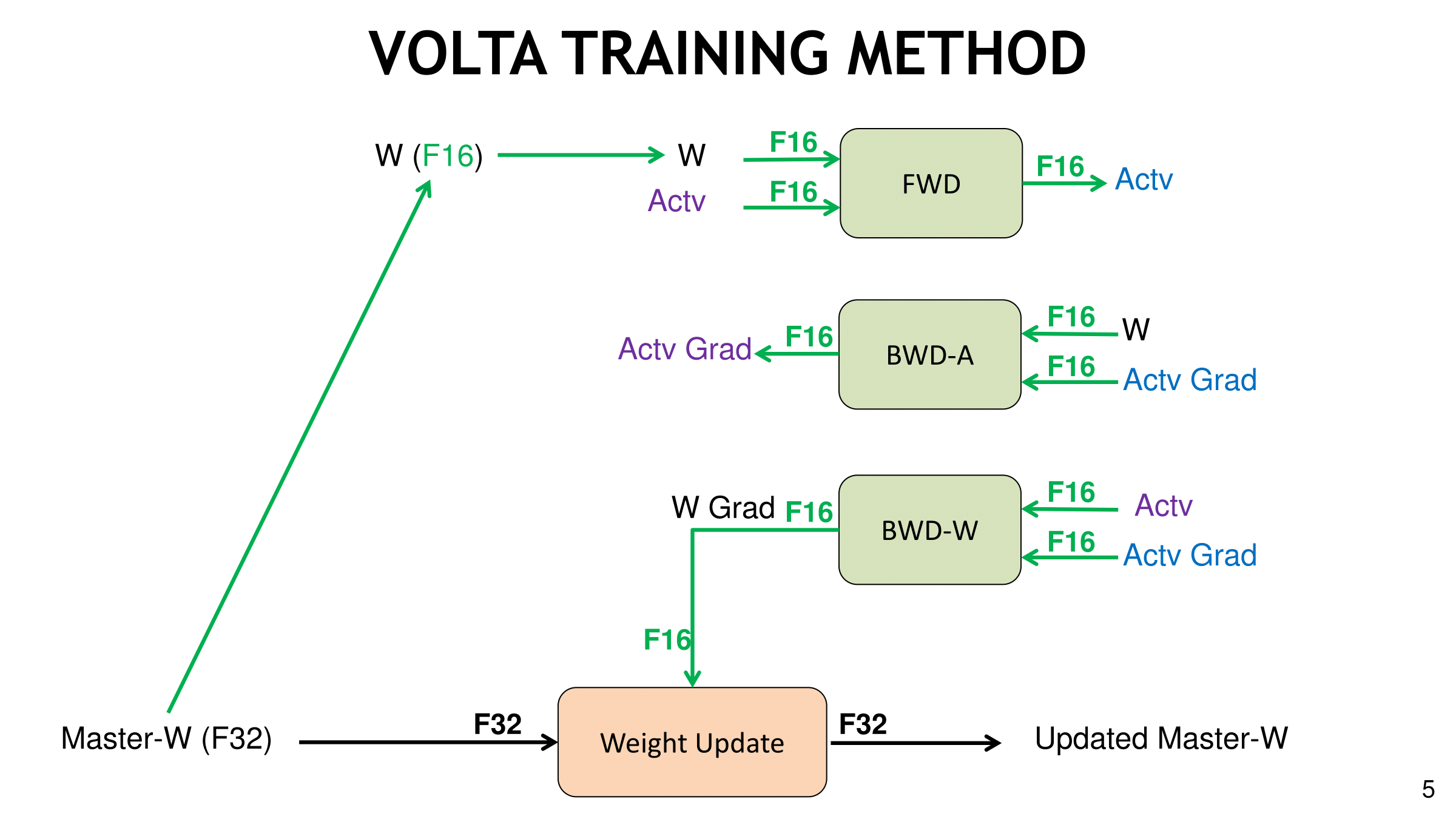
For a given training iteration, Volta mixed precision means the master weights are copied in single and half precision, and while that takes up more memory, NVIDIA believes the accuracy gains are worth it. The half precision weights are used in the ensuing computations, and when the master weights are ready to be updated with the resulting computation, the FP32 copy is used. At that last stage of an iteration, the computed weight updates are converted from FP16 to FP32 in order to update the FP32 master copy of weights, again for accuracy reasons.
Recalling that FP16 does not cover the same data space as FP32, a normalization method can resolve issues where an FP32 value is outside the representable range of FP16 and thus would be converted to a zero. For example, values of many activation gradients would fall outside of the range of FP16, but because these values are clustered together, multiplying the loss with a scaling factor moves most of the values in the range of FP16. The gradients are re-scaled to the original range before weight updates are done, maintaining the original precision.
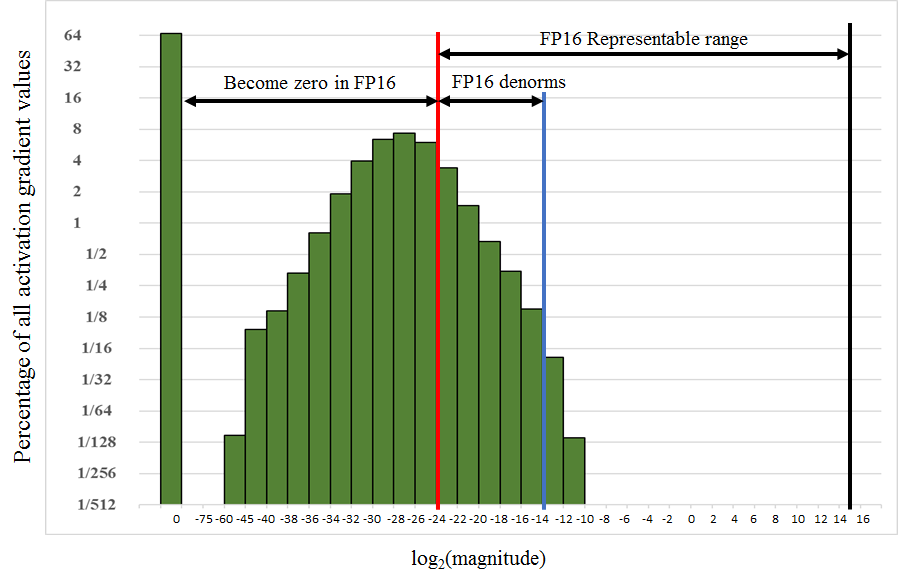
Not all math, neural networks, and layers work well with FP16 storage or math, so depending on the framework or type of neural net, FP16 will either be disabled by default or not recommended. In general, mixed precision with FP16 and tensor cores are best suited with convolution and RNN-heavy image processing and the like. For the most part, cuDNN handles a lot, and developers may only need a few pointers from NVIDIA's Mixed Precision guide. Meanwhile, cuBLAS and CUTLASS also include tensor core support. Altogether, especially with with the maturation of cuDNN it is hard to imagine tensor cores being succesful without it. Intrepid developers can continue trying to wrangle tensor cores directly in CUDA C++, PTX, and the like, though as we have seen tensor cores are, as far as generally programmable GPU blocks go, rather inflexible.
Volta and Pascal: Memory Improvements, SM Changes, and More
With mixed precision tensor cores, it would seem like the memory bandwidth issue was mitigated. As it turns out, not very much, despite the fact that Volta has received memory subsystem enhancements nearly across the board.
For one, Volta now has a 12 KiB L0 instruction cache, and while Pascal and others have had instruction buffers before, Volta's more efficient L0 is private to the sub-core SM partitions. And by that, it is private to the warp scheduler. This compensates for the larger instruction size of Volta's new ISA, and more likely than not, contributes to the framework supporting tensor core thoroughput, which uses the presumably beefy HMMA on a warp-based level. Instruction latency is also reduced from Pascal, notably with core FMAs down to 4 cycles from 6, which we previously confirmed.
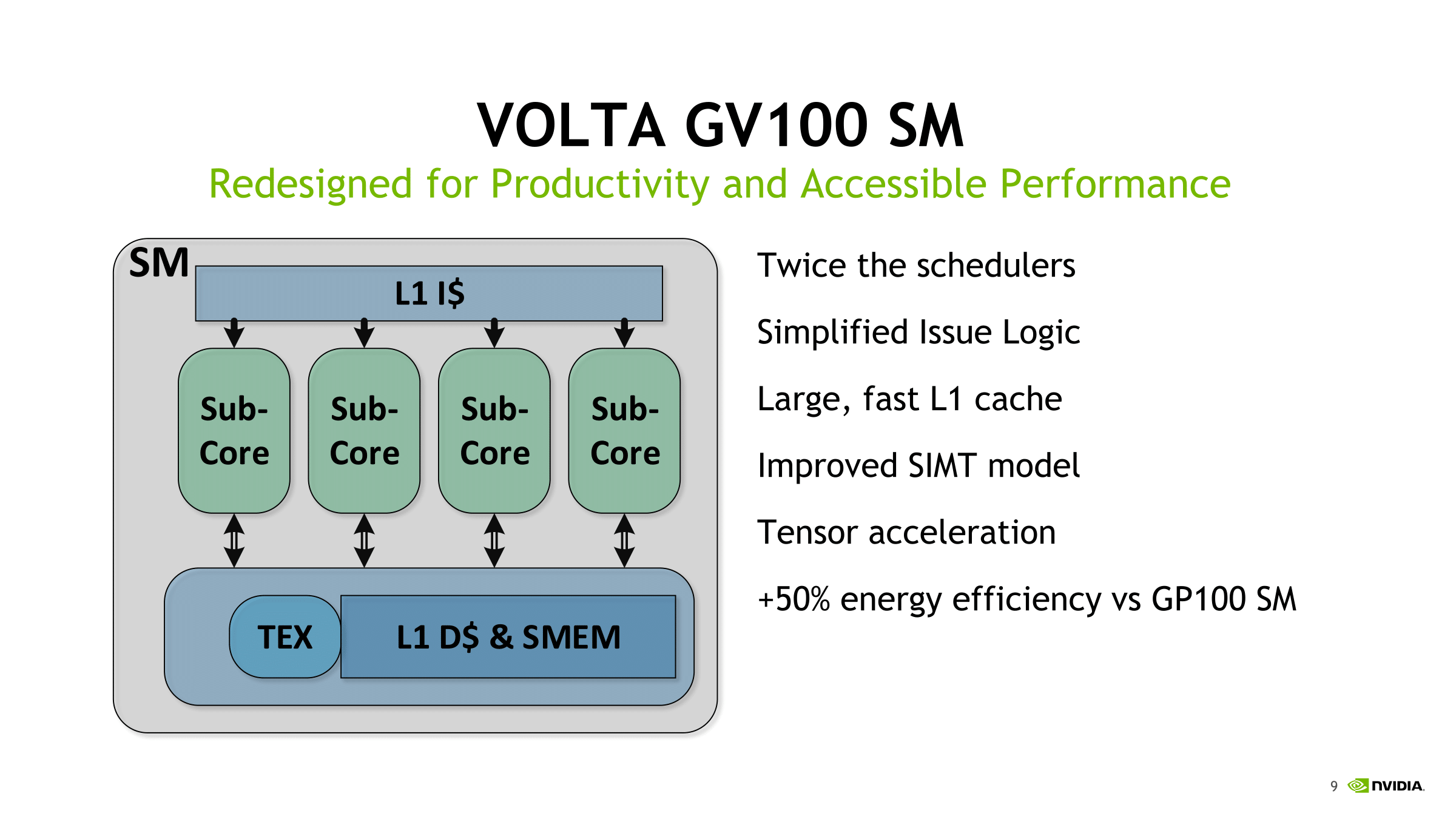
With the ratio of schedulers per SM increased, the loss of the second dispatch port seems to be a tradeoff in favor of independent sub-core with separate data paths and math dispatch unit; with simultaneous FP32/INT32 execution capability, it also opens the door to other lower precision/mixed precision models. Overall, the sub-core enhancements that we detailed earlier look to optimize the tensor core array.
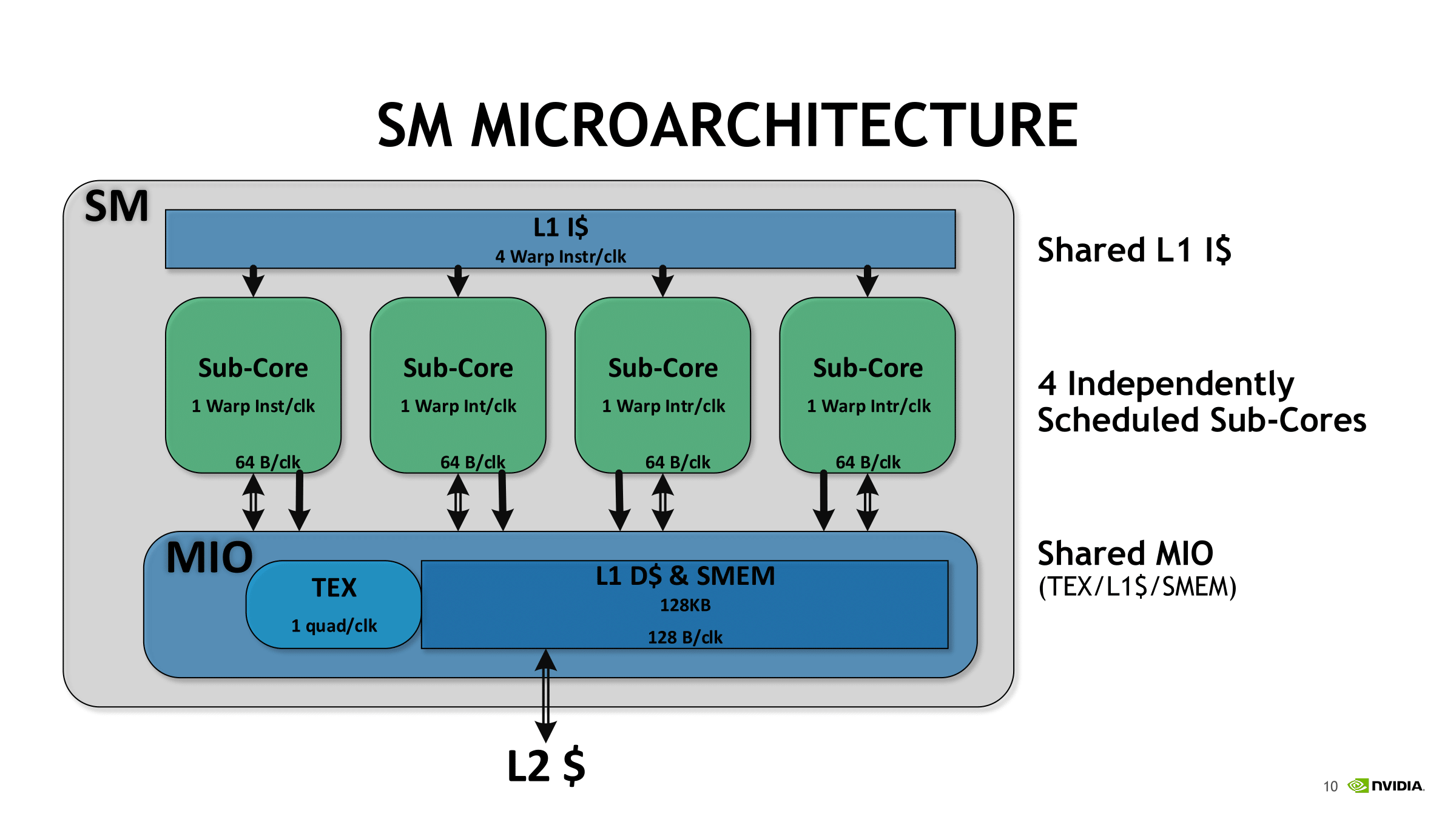
Another big change was merging the L1 cache and shared memory. While in the same block, the shared memory is configurable up to 96 KiB per SM. The HBM2 controller was also updated, and NVIDIA and others have noted 10 - 15% increase in efficiency.
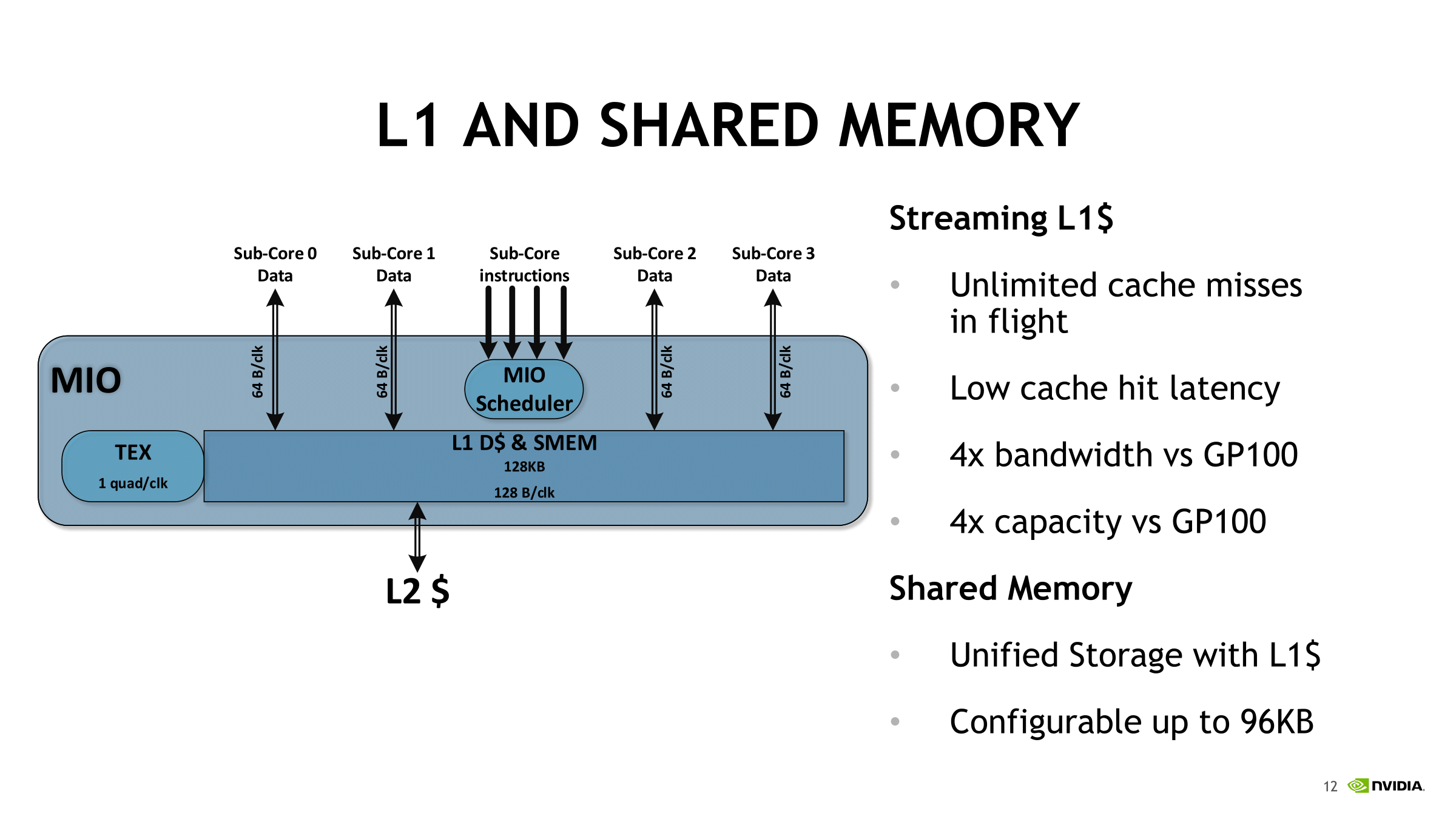
Summing up the SM, Volta looks to be building around a new style of independent partition that supports tensor cores, and one leaning far more on the compute side than on gaming.








65 Comments
View All Comments
Ryan Smith - Tuesday, July 3, 2018 - link
To clarify: SXM3 is the name of the socket used for the mezzanine form factor cards for servers. All Titan Vs are PCie.Drumsticks - Tuesday, July 3, 2018 - link
Nice review. Will anandtech be putting forth an effort to cover the ML hardware space in the future? AMD and Intel both seem to have plans here.The V100 and Titan V should have well over 100TF according to Nvidia in training and inference, if I remember correctly, but nothing I saw here got close in actuality. Were these benches not designed to hit those numbers, or are those numbers just too optimistic in most scenarios to occur?
Ryan Smith - Tuesday, July 3, 2018 - link
"The V100 and Titan V should have well over 100TF according to Nvidia in training and inference"The Titan V only has 75% of the memory bandwidth of the V100. So it's really hard to hit 100TF. Even in our Titan V preview where we ran a pure CUDA-based GEMM benchmark, we only hit 97 TFLOPS. Meanwhile real-world use cases are going to be lower still, as you can only achieve those kinds of high numbers in pure tensor core compute workloads.
https://www.anandtech.com/show/12170/nvidia-titan-...
Nate Oh - Tuesday, July 3, 2018 - link
To add on to Ryan's comment, 100+ TF is best-case (i.e. synthetic) performance based on peak FMA ops on individual matrix elements, which only comes about when everything perfectly qualifies for tensor core acceleration, no memory bottleneck by reusing tons of register data, etc.remedo - Tuesday, July 3, 2018 - link
Nate, I hope you could have included more TensorFlow/Keras specific benchmarks, given that the majority of deep learning researchers/developers are now using TensorFlow. Just compare the GitHub stats of TensorFlow vs. other frameworks. Therefore, I feel that this article missed some critical benchmarks in that regard. Still, this is a fascinating article, and thank you for your work. I understand that Anandtech is still new to deep learning benchmarks compared to your decades of experience in CPU/Gaming benchmark. If possible, please do a future update!Nate Oh - Tuesday, July 3, 2018 - link
Several TensorFlow benchmarks did not make the cut for today :) We were very much interested in using it, because amongst other things it offers global environmental variables to govern tensor core math, and integrates somewhat directly with TensorRT. However, we've been having issues finding and using one that does all the things we need it to do (and also offers different results than just pure throughput), and I've gone so far as trying to rebuild various models/implementations directly in Python (obviously to no avail, as I am ultimately not an ML developer).According to people smarter than me (i.e. Chintala, and I'm sure many others), if it's only utilizing standard cuDNN operations then frameworks should perform about the same; if there are significant differences, a la the inaugural version of Deep Learning Frameworks Comparison, it is because it is poorly optimized for TensorFlow or whatever given framework. From a purely GPU performance perspective, usage of different frameworks often comes down to framework-specific optimization, and not all reference implementations or benchmark suite tests do what we need it to do out-of-the-box (not to mention third-party implementations). Analyzing the level of TF optimization is developer-level work, and that's beyond the scope of the article. But once benchmark suites hit their stride, that will resolve that issue for us.
For Keras, I wasn't able to find anything that was reasonably usable by a non-developer, though I could've easily missed something (I'm aware of how it relates to TF, Theano, MXNet, etc). I'm sure that if we replaced PyTorch with Tensorflow implementations, we would get questions on 'Where's PyTorch?' :)
Not to say your point isn't valid, it is :) We're going to keep on looking into it, rest assured.
SirPerro - Thursday, July 5, 2018 - link
Keras has some nice examples in its github repo to be run with the tensorflow backend but for the sake of benchmarking it does not offer anything that it's not covered by the pure tensorflow examples, I guessBurntMyBacon - Tuesday, July 3, 2018 - link
I believe the GTX Titan with memory clock 6Gbps and memory bus width of 384 bits should have a memory bandwidth of 288GB/sec rather than the list 228GB/sec. Putting that aside, this is a nice review.Nate Oh - Tuesday, July 3, 2018 - link
Thanks, fixedJon Tseng - Tuesday, July 3, 2018 - link
Don't be silly. All we care about is whether it can run Crysis at 8K.