The NVIDIA Titan V Deep Learning Deep Dive: It's All About The Tensor Cores
by Nate Oh on July 3, 2018 10:15 AM ESTRevisiting Volta: How to Accelerate Deep Learning
While we’ve gone over Volta’s distinguishing characteristics several times now, the marquee addition of tensor cores somewhat overshadows all the other changes that supplement or outright support tensor core usage. For one, as we've already seen, it's tightly tied into the improved SIMT model with Volta's independent thread scheduling and collective groups.
Mixed Precision: Making FP16 Work for Deep Learning
Ultimately, Volta’s deep learning prowess is built on utilizing half precision (IEEE-754 FP16) rather than single precision (FP32) for deep learning training. First supported by cuDNN 3 and implemented in Tegra X1’s Maxwell cores, native half precision compute was fully introduced with Pascal as “Pseudo FP16”, where FP32 ALUs could instead process pairs of FP16 instructions for theoretically double FP16 throughput per clock. We've actually seen this in how tensor cores deal with matrix fragments in the register, as the two FP16 input matrices are gathered in 8 elements of FP16x2, or 16 FP16 elements.
In terms of FP32 versus FP16, because the single precision format ‘describes’ more data than half precision, operations are more computationally intensive and more memory storage/bandwidth is needed to house and transfer the data, in turn consuming more power. So the successful usage of lower precision in compute has been a poor man’s holy grail of sorts, targeting applications where higher precision is unnecessary.
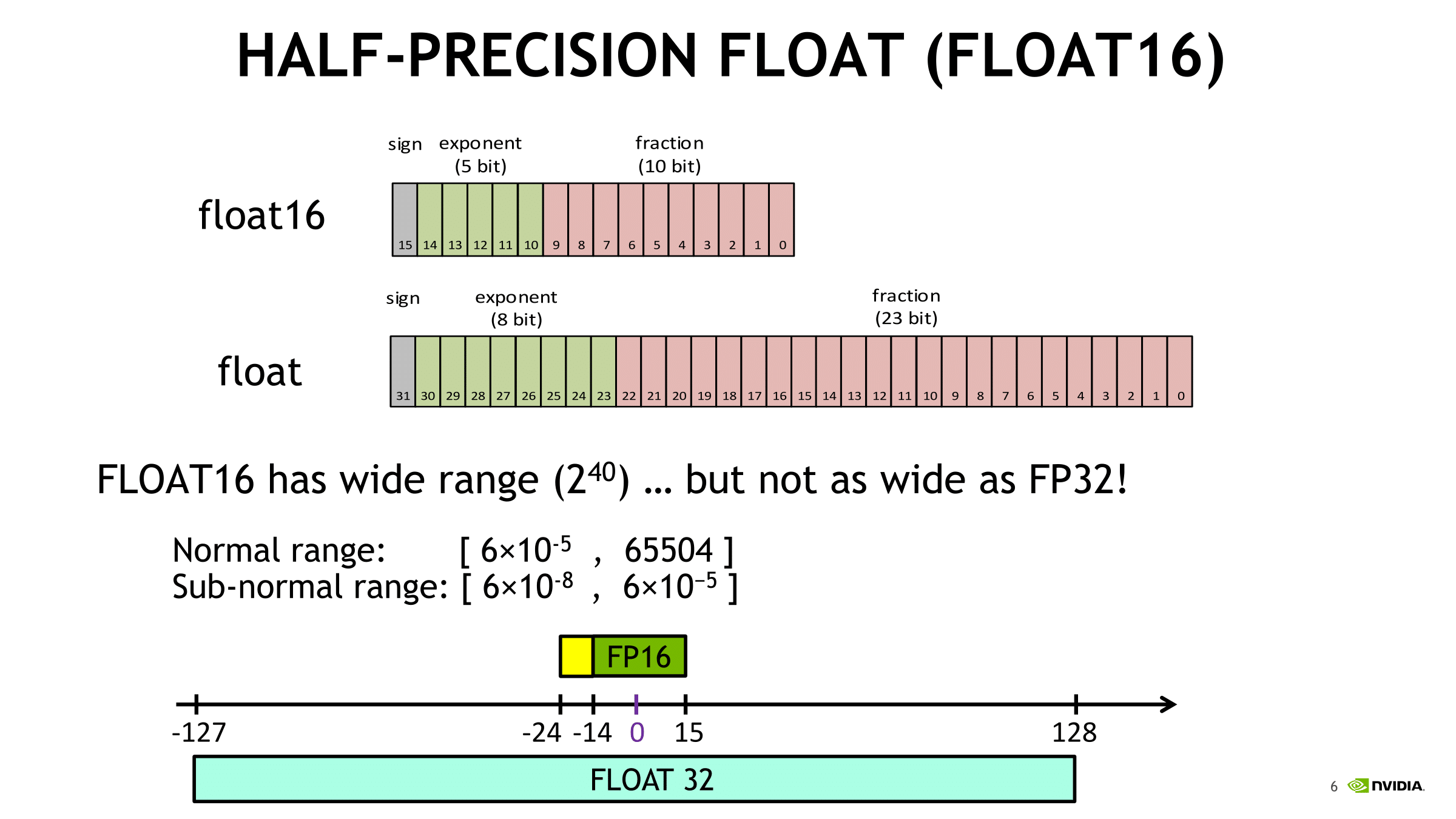
Aside from API/compiler/framework support, the perennial drawback for deep learning is the (unsurprising) loss of precision in using FP16 data types, where the training process would not be accurate enough and so the model cannot converge. Enter mixed precision.

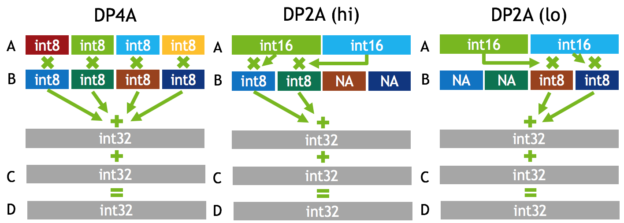
To be fair, NVIDIA has wheeled out the 'mixed precision' term before in very similar context, in discussing Pascal's fast FP16 (for GP100) and DP4A/DP2A integer dot product operations (for GP102, GP104, and GP106 GPUs). Back then, the focus was on inference, and very much like Titan V's 'deep learning TFLOPS,' Titan X (Pascal) launched with a "44 TOPS (new deep learning inferencing instruction)." The new instructions performed integer dot products on 4-element 8-bit vectors or 2-element 8-bit/16-bit vectors, resulting in a 32-bit integer product that could be accumulated with other 32-bit integers.
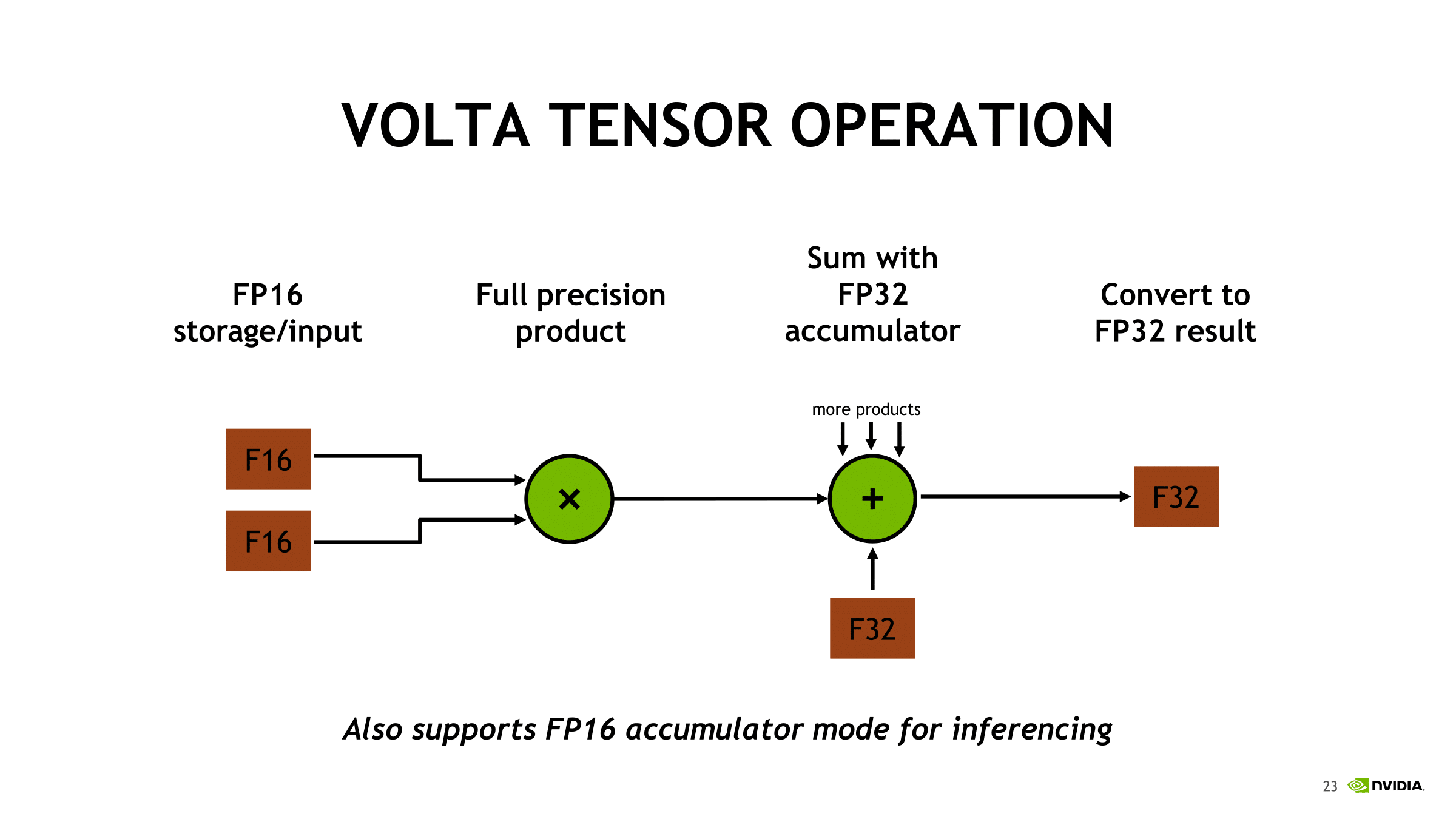
So for mixed precision in Volta, there are several more wrinkles. First is that important precision-sensitive data like master weights are stored as FP32. The second is tensor cores, where mixed precision training describes how two half precision input matrices are multiplied to get a single precision product, which is then accumulated into a single precision sum. NVIDIA has stated that the result is converted back to half precision before being written into memory, though how this happens is not exactly clear. For inferencing purposes though, the tensor core will instead accumulate the result into a half precision sum. Ultimately, when using half precision format, less data is needed in the registers and memory, which helps compensate for the data in very large matrices.
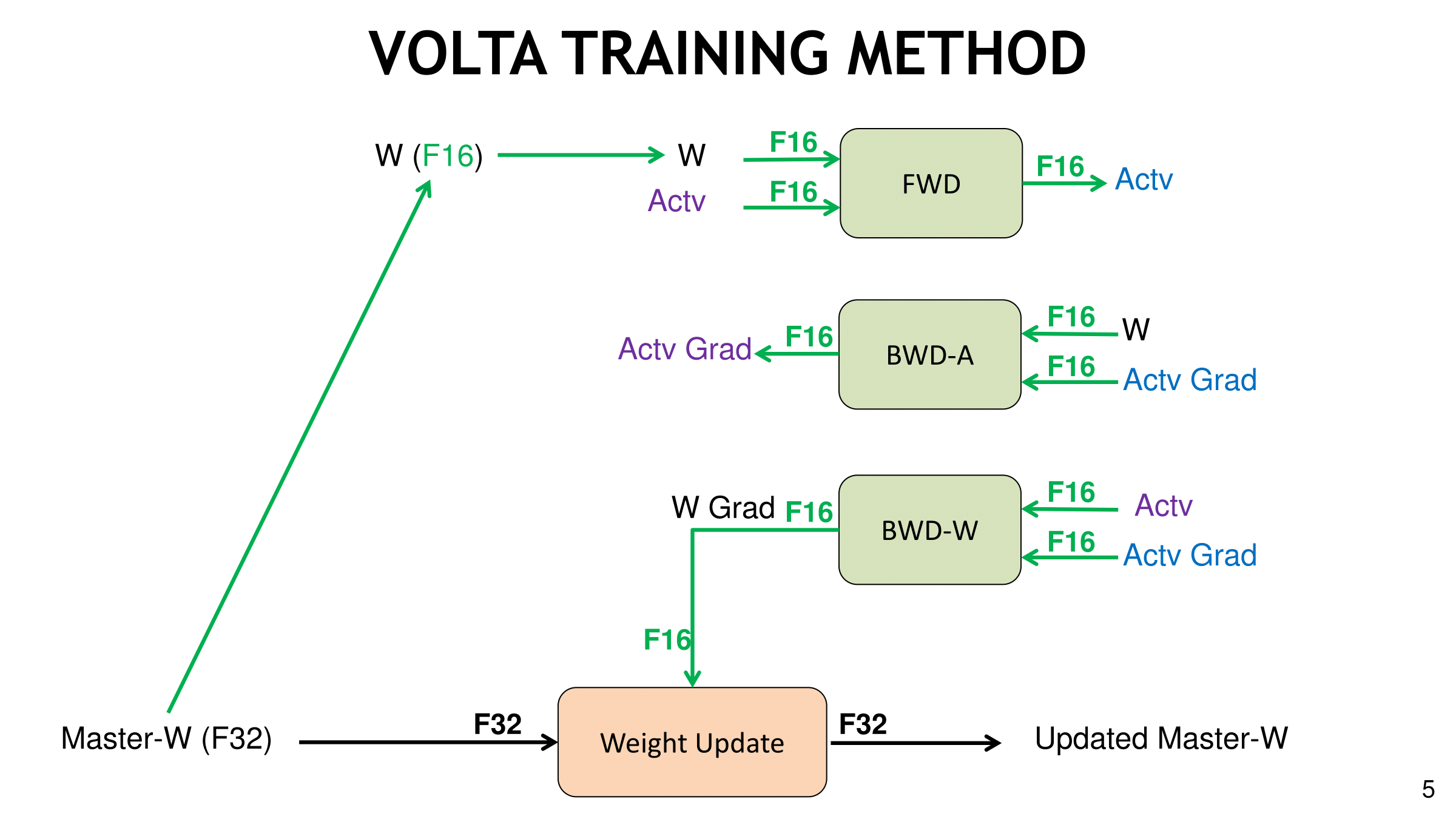
For a given training iteration, Volta mixed precision means the master weights are copied in single and half precision, and while that takes up more memory, NVIDIA believes the accuracy gains are worth it. The half precision weights are used in the ensuing computations, and when the master weights are ready to be updated with the resulting computation, the FP32 copy is used. At that last stage of an iteration, the computed weight updates are converted from FP16 to FP32 in order to update the FP32 master copy of weights, again for accuracy reasons.
Recalling that FP16 does not cover the same data space as FP32, a normalization method can resolve issues where an FP32 value is outside the representable range of FP16 and thus would be converted to a zero. For example, values of many activation gradients would fall outside of the range of FP16, but because these values are clustered together, multiplying the loss with a scaling factor moves most of the values in the range of FP16. The gradients are re-scaled to the original range before weight updates are done, maintaining the original precision.
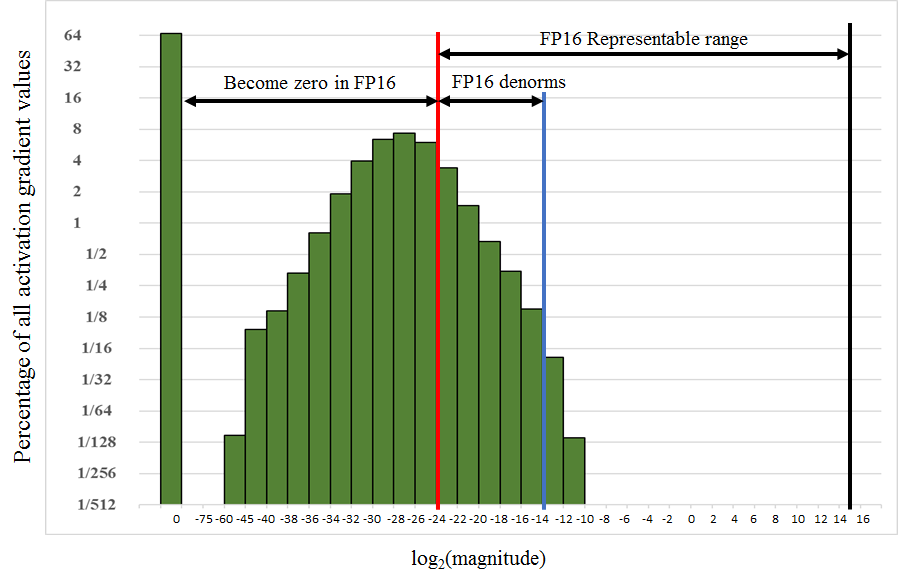
Not all math, neural networks, and layers work well with FP16 storage or math, so depending on the framework or type of neural net, FP16 will either be disabled by default or not recommended. In general, mixed precision with FP16 and tensor cores are best suited with convolution and RNN-heavy image processing and the like. For the most part, cuDNN handles a lot, and developers may only need a few pointers from NVIDIA's Mixed Precision guide. Meanwhile, cuBLAS and CUTLASS also include tensor core support. Altogether, especially with with the maturation of cuDNN it is hard to imagine tensor cores being succesful without it. Intrepid developers can continue trying to wrangle tensor cores directly in CUDA C++, PTX, and the like, though as we have seen tensor cores are, as far as generally programmable GPU blocks go, rather inflexible.
Volta and Pascal: Memory Improvements, SM Changes, and More
With mixed precision tensor cores, it would seem like the memory bandwidth issue was mitigated. As it turns out, not very much, despite the fact that Volta has received memory subsystem enhancements nearly across the board.
For one, Volta now has a 12 KiB L0 instruction cache, and while Pascal and others have had instruction buffers before, Volta's more efficient L0 is private to the sub-core SM partitions. And by that, it is private to the warp scheduler. This compensates for the larger instruction size of Volta's new ISA, and more likely than not, contributes to the framework supporting tensor core thoroughput, which uses the presumably beefy HMMA on a warp-based level. Instruction latency is also reduced from Pascal, notably with core FMAs down to 4 cycles from 6, which we previously confirmed.
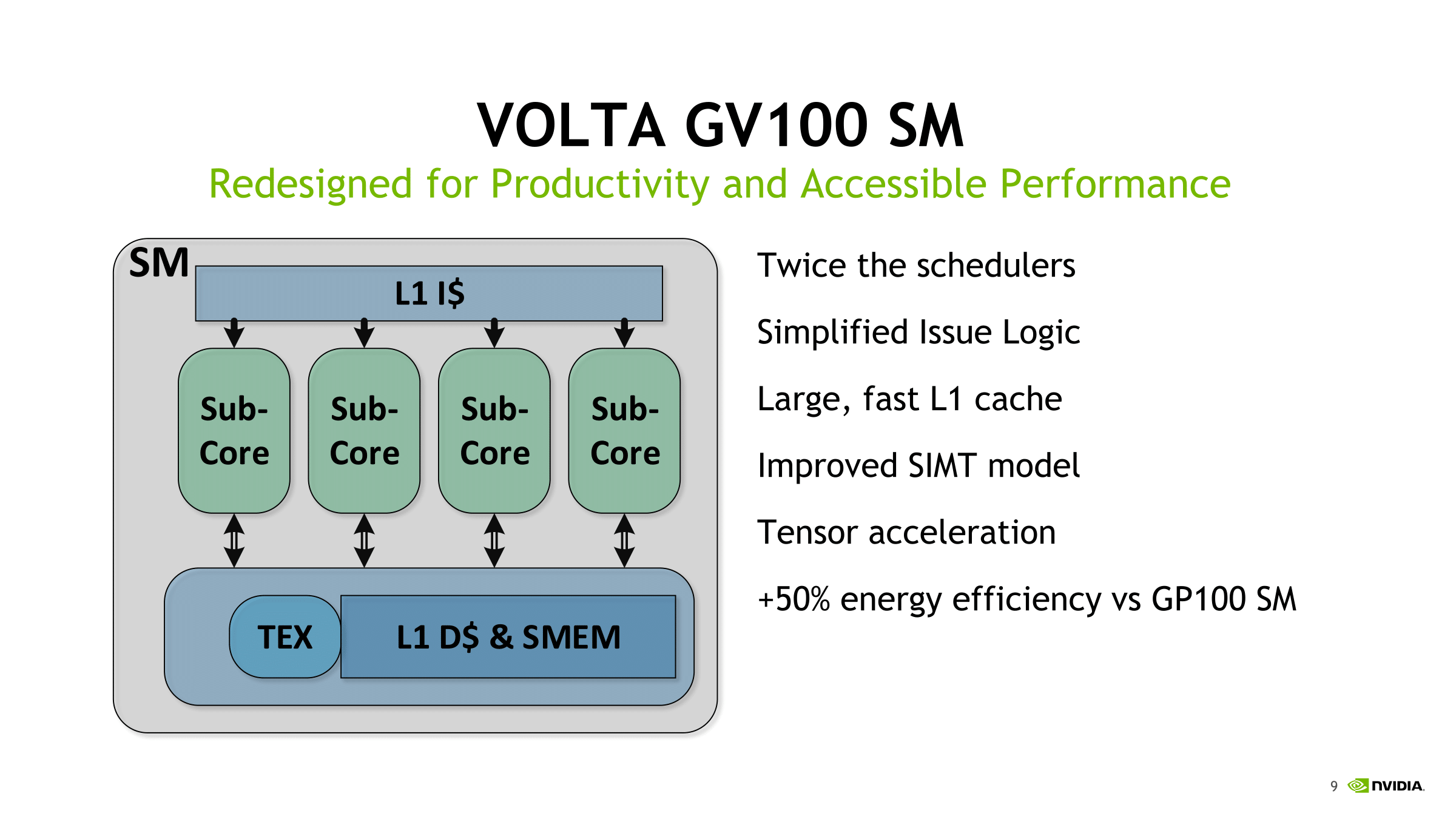
With the ratio of schedulers per SM increased, the loss of the second dispatch port seems to be a tradeoff in favor of independent sub-core with separate data paths and math dispatch unit; with simultaneous FP32/INT32 execution capability, it also opens the door to other lower precision/mixed precision models. Overall, the sub-core enhancements that we detailed earlier look to optimize the tensor core array.
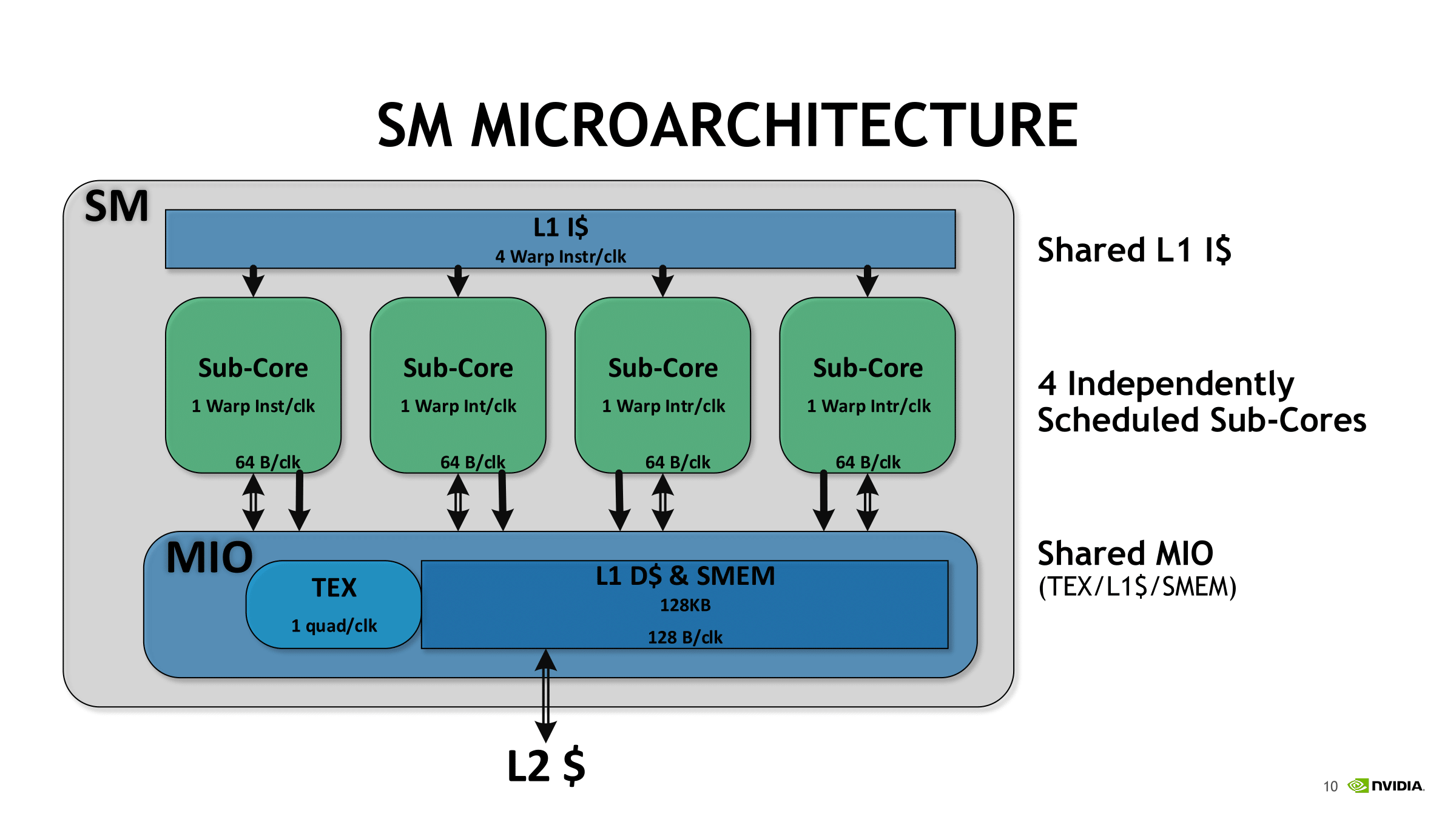
Another big change was merging the L1 cache and shared memory. While in the same block, the shared memory is configurable up to 96 KiB per SM. The HBM2 controller was also updated, and NVIDIA and others have noted 10 - 15% increase in efficiency.
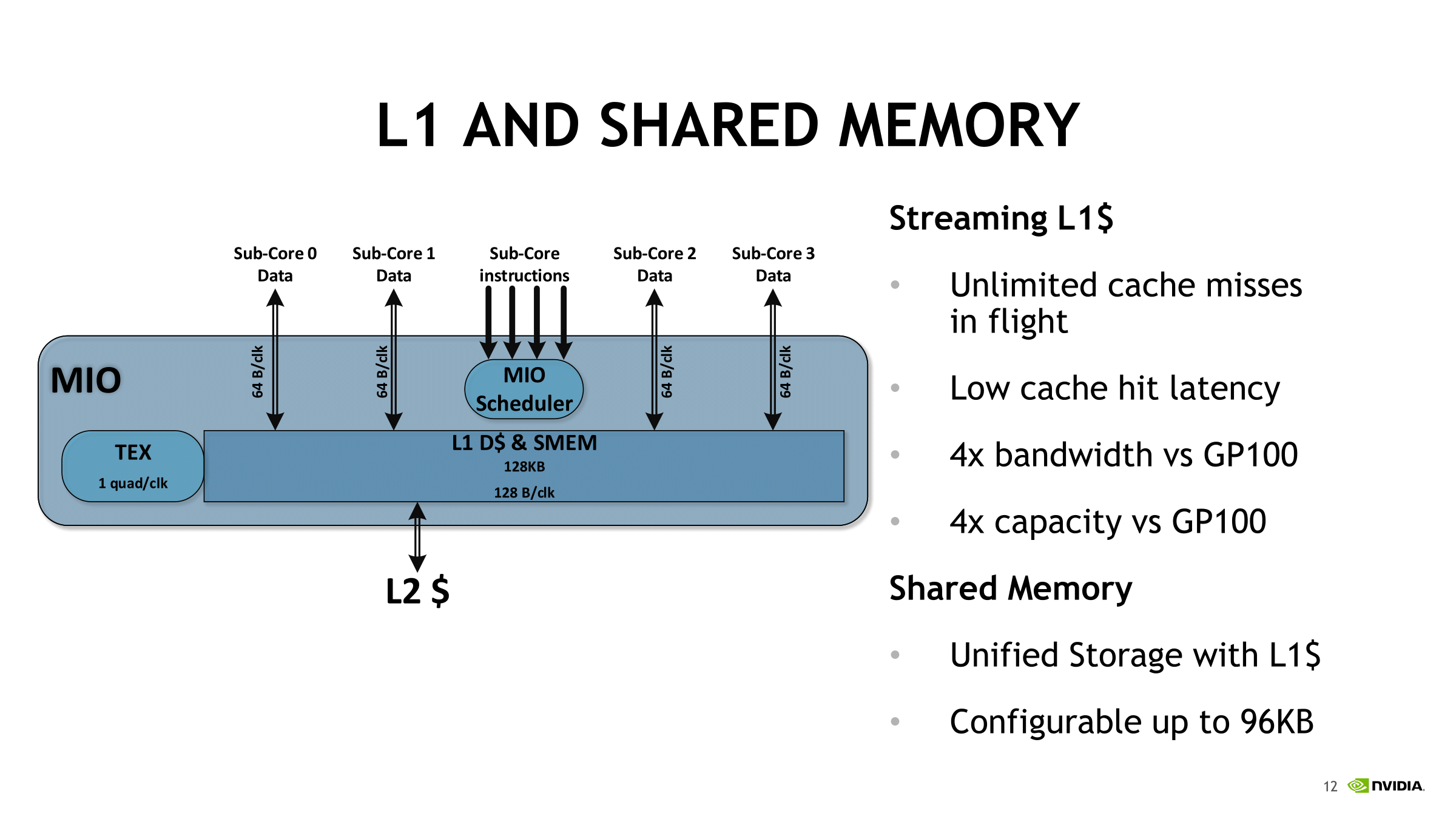
Summing up the SM, Volta looks to be building around a new style of independent partition that supports tensor cores, and one leaning far more on the compute side than on gaming.








65 Comments
View All Comments
SirPerro - Thursday, July 5, 2018 - link
The fancy girls with the macbook in starbucks are not exactly the target demographics for a deep learning desktop card. Or if they are, their laptop plays no part in that.This card is meant for professionals who can spend more than its price in google cloud training neural networks. For everyone else it makes absolutely no sense.
tipoo - Tuesday, July 3, 2018 - link
That Vega 56/64 in the iMac Pro pitched for deep learning also looks pretty underwhelming...Demiurge - Wednesday, July 4, 2018 - link
First of all, who "pitched" a iMac Pro for Deep Learning? Why would Apple put a $3k GPU in a model that is typically selling for $4-5k?Second, what model are you training on Vega that isn't sufficient with 2-4x the FP16/FP8/INT8 throughput of a 1080 Ti? How is that underwhelming?
mode_13h - Wednesday, July 4, 2018 - link
The GP102 in the 1080 Ti and Titan Xp doesn't support double-rate fp16. Just 4x int8 dot product, AFAIK, which you can't really use for training.Demiurge - Friday, July 6, 2018 - link
My point exactly since Vega does support double-rate FP16, among other things that the consumer GPU's typically don't support.As for the DP4A instruction, it is very much used in training.
INT8 datatype support is becoming more important, as is FP8 for reducing training time. Two more features Vega supports free of additional charge.
mode_13h - Friday, July 6, 2018 - link
If 8-bit int were acceptable for training, then why would anyone bother with fp16?Vega 10 doesn't have meaningful packed 8-bit support of any kind. It has only a couple such instructions that are intended for video compression. Vega 20 will change that, even adding support for packed 4-bit. But your comment seems oriented towards the current Vega.
Demiurge - Sunday, July 8, 2018 - link
Here's some reading (read the first line of the conclusion of the paper: Dettmers, 8-Bit Approximations for Parallelism in Deep Learning, ICLR 2016 https://arxiv.org/pdf/1511.04561.pdf):https://www.xilinx.com/support/documentation/white...
We shall disagree on "Vega 10 does not have meaningful packed 8-bit support". I'll let someone else argue with you, but I know what you mean. I don't agree, but I think I understand where you are coming from.
mode_13h - Monday, July 9, 2018 - link
Aww... don't pick a fight, then walk away!Here's the current Vega ISA doc. The only 8-bit packed arithmetic I see is unweighted blending and sum of absolute differences. AFAIK, this is not a useful degree of functionality for deep learning. If I'm wrong, show me.
http://developer.amd.com/wordpress/media/2013/12/V...
As for your first link, that deals with a *custom* 8-bit datatype, from what I can tell - not the int8 supported by Nvidia's DP4A or Vega 20 (from what we know).
Finally, your second link appears to deal *exclusively* with inference. Just like I said.
Nate Oh - Tuesday, July 10, 2018 - link
AMD says in the Vega whitepaper that INT8 SAD is applicable to several machine learning applications. It’s not new to Vega though. Various types of INT8 SAD dates back to earlier versions of GCN, and Kepler/Maxwell have single cycle packed INT8 SAD anyhow. But technically, according to AMD it is a useful degree of functionality.The real caveat to this is real-world DL performance has never been about raw operations per seconds, new instructions or not. This is one of the main points I wanted to convey with the article. (And to ward off any concerns, DeepBench does not fall under that because A) it uses DL kernels representative of DL applications and B) results are all in microseconds that are converted to TFLOPS using the kernel dimensions; TFLOPS is much is easier to present as a measure of performance.)
These instructions are only as good as their DL support. Even with ROCm/HIP/etc, Vega isn’t a drop-in replacement for a 1080 Ti, where you expect the hardware advantage to ‘just work’ in training. You have to port the model and retune with ROCm/MIOpen, HIP or OpenCL, etc., troubleshoot and make sure the hardware features you want to use is actually supported in MIOpen (if MIOpen support is even production-ready in your framework of choice), and the list goes on. Tuning guides for AMD architectures are not yet filled out on their ROCm documentation, and I couldn’t find out if packed INT8 xSAD is well-integrated as some DL primitive in MIOpen. MIOpen also still doesn’t support FP16 for RNNs, or training with CNNs, so no Rapid Packed Math there. Unless you implement these things yourself. I hope you know your GCN assembly.
What I’m trying to say is that for DL hardware (especially GPUs), software support and ecosystem are basically more important right now. If you’re more focused on the DL and not on the GPU side, then you’re more interested in the models and neural networking, less interested in low-level GPU tuning for a new architecture, only familiar with the CUDA ecosystem, and less willing to be a ROCm adventurer without immediate results that you need to publish or use.
So it’s true that Vega brings features to consumer GPUs that they don’t usually support, but using them for DL is not trivial. It’s easy to just say that it’ll work; I can tell you that sitting back in my chair I am super curious about Radeon SSG and DL’s perennial main memory bandwidth/size issue, but somebody has to go develop that implementation.
Which is a long way of stating, Vega doesn’t have packed 8-bit support as influential as Demiurge has claimed.
Links/References
https://radeon.com/_downloads/vega-whitepaper-11.6...
https://www.amd.com/Documents/GCN_Architecture_whi... (SAD for pixel shaders introduced)
http://rocm-documentation.readthedocs.io/en/latest...
http://rocm-documentation.readthedocs.io/en/latest...
https://www.hotchips.org/wp-content/uploads/hc_arc...
https://devtalk.nvidia.com/default/topic/966491/te...
mode_13h - Tuesday, July 10, 2018 - link
> AMD says in the Vega whitepaper that INT8 SAD is applicable to several machine learning applications."The NCU also supports a set of 8-bit integer SAD (Sum of Absolute Differences) operations. These operations are important for a wide range of video and image processing algorithms, including image classification for machine learning, motion detection, gesture recognition, stereo depth extraction, and computer vision."
Eh, I still don't think they mean deep learning. Probably, they're referring to some classical image processing techniques, or maybe preprocessing prior to feeding a CNN. Ideally, you might ask them for examples of where it's used, or maybe at least paper citations (which are conspicuously absent from that part of their whitepaper). But I know this was an ambitious article, so maybe it's something to keep in mind for your coverage of Vega 20.
> results are all in microseconds that are converted to TFLOPS using the kernel dimensions
Dude, that's messed up. At the very least, it shouldn't be TFLOPS unless you're actually using floating-point arithmetic. And if you're using a framework that optimizes your model (such as TensorRT, I think), I wouldn't report end performance as if it were actually using the unoptimized kernel.
> Tuning guides for AMD architectures are not yet filled out on their ROCm documentation, and I couldn’t find out if packed INT8 xSAD is well-integrated as some DL primitive in MIOpen.
Well, "Open" means open source, in this case. One could try and have a look. That said, it's a huge article and nobody could've reasonably expected you to do more. It'd be more digestible if broken into a couple installments, actually.
Anyway, the rough state of MIOpen is actually one of the main reasons we don't currently use AMD. I hope the situation changes by the time Vega 20 launches.
Anyhow, thanks for the comprehensive reply, not to mention the article. There are still a few parts I need to go back & read!