The AMD 2nd Gen Ryzen Deep Dive: The 2700X, 2700, 2600X, and 2600 Tested
by Ian Cutress on April 19, 2018 9:00 AM ESTTranslating to IPC: All This for 3%?
Contrary to popular belief, increasing IPC is difficult. Attempt to ensure that each execution port is fed every cycle requires having wide decoders, large out-of-order queues, fast caches, and the right execution port configuration. It might sound easy to pile it all on, however both physics and economics get in the way: the chip still has to be thermally efficient and it has to make money for the company. Every generational design update will go for what is called the ‘low-hanging fruit’: the identified changes that give the most gain for the smallest effort. Usually reducing cache latency is not always the easiest task, and for non-semiconductor engineers (myself included), it sounds like a lot of work for a small gain.
For our IPC testing, we use the following rules. Each CPU is allocated four cores, without extra threading, and power modes are disabled such that the cores run at a specific frequency only. The DRAM is set to what the processor supports, so in the case of the new CPUs, that is DDR4-2933, and the previous generation at DDR4-2666. I have recently seen threads which dispute if this is fair: this is an IPC test, not an instruction efficiency test. The DRAM official support is part of the hardware specifications, just as much as the size of the caches or the number of execution ports. Running the two CPUs at the same DRAM frequency gives an unfair advantage to one of them: either a bigger overclock/underclock, and deviates from the intended design.
So in our test, we take the new Ryzen 7 2700X, the first generation Ryzen 7 1800X, and the pre-Zen Bristol Ridge based A12-9800, which is based on the AM4 platform and uses DDR4. We set each processors at four cores, no multi-threading, and 3.0 GHz, then ran through some of our tests.
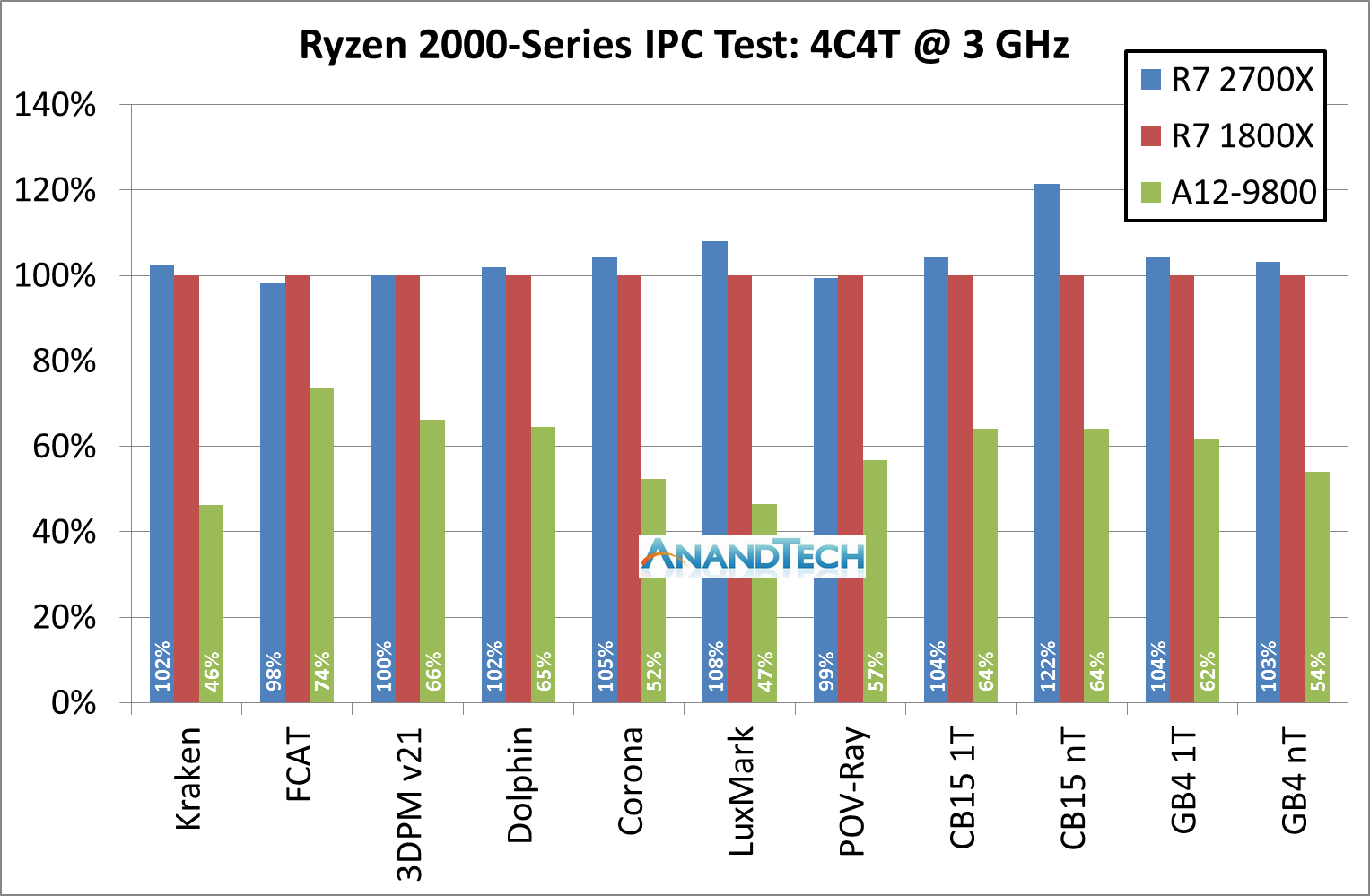
For this graph we have rooted the first generation Ryzen 7 1800X as our 100% marker, with the blue columns as the Ryzen 7 2700X. The problem with trying to identify a 3% IPC increase is that 3% could easily fall within the noise of a benchmark run: if the cache is not fully set before the run, it could encounter different performance. Shown above, a good number of tests fall in that +/- 2% range.
However, for compute heavy tasks, there are 3-4% benefits: Corona, LuxMark, CineBench and GeekBench are the ones here. We haven’t included the GeekBench sub-test results in the graph above, but most of those fall into the 2-5% category for gains.
If we take out Cinebench R15 nT result and the Geekbench memory tests, the average of all of the tests comes out to a +3.1% gain for the new Ryzen 2700X. That sounds bang on the money for what AMD stated it would do.
Cycling back to that Cinebench R15 nT result that showed a 22% gain. We also had some other IPC testing done at 3.0 GHz but with 8C/16T (which we couldn’t compare to Bristol Ridge), and a few other tests also showed 20%+ gains. This is probably a sign that AMD might have also adjusted how it manages its simultaneous multi-threading. This requires further testing.
AMD’s Overall 10% Increase
With some of the benefits of the 12LP manufacturing process, a few editors internally have questioned exactly why AMD hasn’t redesigned certain elements of the microarchitecture to take advantage. Ultimately it would appear that the ‘free’ frequency boost is worth just putting the same design in – as mentioned previously, the 12LP design is based on 14LPP with performance bump improvements. In the past it might not have been mentioned as a separate product line. So pushing through the same design is an easy win, allowing the teams to focus on the next major core redesign.
That all being said, AMD has previously already stated its intentions for the Zen+ core design – rolling back to CES at the beginning of the year, AMD stated that they wanted Zen+ and future products to go above and beyond the ‘industry standard’ of a 7-8% performance gain each year.
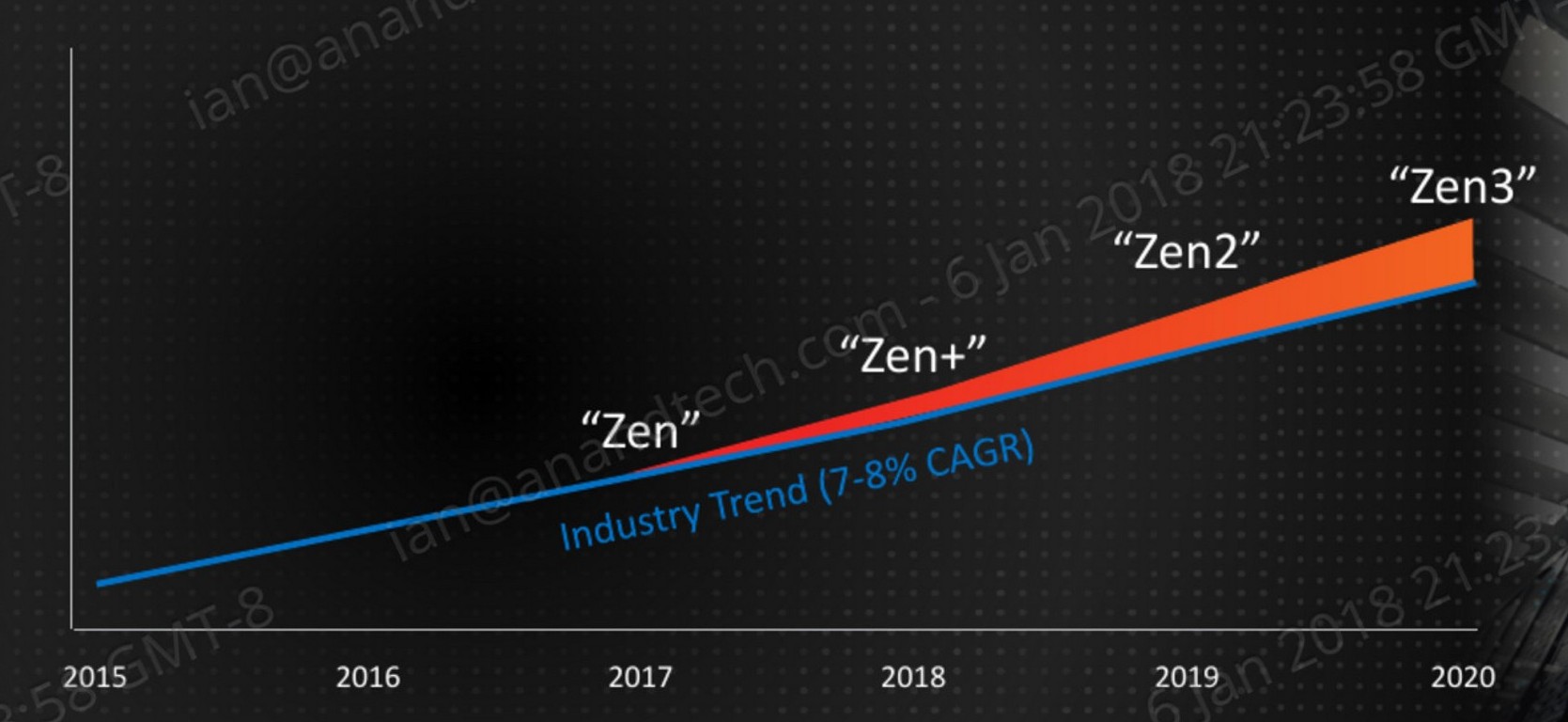
Clearly 3% IPC is not enough, so AMD is combining the performance gain with the +250 MHz increase, which is about another 6% peak frequency, with better turbo performance with Precision Boost 2 / XFR 2. This is about 10%, on paper at least. Benchmarks to follow.








545 Comments
View All Comments
rocky12345 - Tuesday, April 24, 2018 - link
They ran all systems at both Intel's & AMD's listed specs as such AMD's memory was at 2933MHz on Zen+ & 2666MHz on Intel's Coffee lake 8700K,they did the same for the older gen parts as well and ran those at the spec's listed for them as well.There have been a few other media outlets that did the same thing and got the same results or very close to the same results. AMD's memory bandwidth as in memory controller seems to give more bandwidth than Intel's does at the same speed so with Intel not running at 3200MHz like most media outlets did maybe Intel loses a lot of performance because of that and AMD lost next to nothing from not going 3200MHz. It is all just guesses on my part at the moment.
Food for thought when Intel released the entire Coffee Lake line up they only released the z370 chip set which has full support for over clocking including the memory and almost all reviews were done with 3200MHz-3400MHz memory on the test beds even for the non K Coffee lakes CPU's. Maybe Intel knew this would happen and made sure all Coffee lakes looked their best in the reviews. For a few sites that retested once the lower tier chip sets were released the non K's using their rated memory speeds lost about 5%-7% performance in some cases a bit even more.
I am no fanboy of any company I just put out my opinions & theories that are based off of the information we are given by the companies and as well as the media sites.
Maxiking - Tuesday, April 24, 2018 - link
People never fail to amaze me, so you basically know nothing about the topic, yet you still managed to spit 4 paragraphs of mess, even made some "food for thought".Slower ram - performance regression unless you have big caches which is not the case of Intel nor AMD.
rocky12345 - Tuesday, April 24, 2018 - link
It seems pretty basic to me as to what was said in the post. It is not my problem if you do not under stand what myself and some others have said about this topic. Pretty simple slower memory less bandwidth which in turn will give less performance in memory intensive work loads such as most games. ALl you have to do is go and look at some benches in the reviews to see AMD has the upper hand when it comes to memory bandwidth even Hardware Unboxed was pretty surprised by how good AMD's memory controller when compared to Intel's. Yes Intel's can run memory at higher speeds than AMD but even with that said AMD does just fine. You are right about cache sizes neither has a overly large cache but AMD 's is bigger on the desktop class CPU's and that is most likely one of the reasons their bandwidth for memory is slightly better.Maxiking - Wednesday, April 25, 2018 - link
The raw bandwidth doesn't matter, it's cas latency what makes the difference here.https://www.anandtech.com/show/11857/memory-scalin...
https://imgur.com/MhqKfkf
With CL16, it doesn't look that much impressive, is it.
Now, lower the CL latencies to something more 2k18-ish, booom.
https://www.eteknix.com/memory-speed-large-impact-...
Another test
https://www.pcper.com/reviews/Processors/Ryzen-Mem...
Almost all the popular hw reviewers don't have a clue. They tell you to OC but do not explain why and what you should accomplish by overclocking. Imagine you have some bad hynix ram which can be barelly OC from 2666 to 3000mhz but you have to loose timing from CL15 for CL20 to get there.
mapesdhs - Monday, May 14, 2018 - link
schlock, the chips were run at official spec. Or are you saying it's AMD's fault that Intel doesn't officially support faster speeds? :D Also, GN showed that subtimings have become rather important for AMD CPUs; some mbds left on Auto for subtimings will make very good selections for them, giving a measurable performance advantage.peevee - Tuesday, April 24, 2018 - link
It is April 24th, and the page on X470 still states: "Technically the details of the chipset are also covered by the April 19th embargo, so we cannot mention exactly what makes them different to the X370 platform until then."jor5 - Tuesday, April 24, 2018 - link
The review is a shambles. They've gone to ground.coburn_c - Tuesday, April 24, 2018 - link
I have been wanting to read their take on x470..risa2000 - Wednesday, April 25, 2018 - link
It is my favorite page too.mpbello - Tuesday, April 24, 2018 - link
Today phoronix is reporting that after AMD's newest AGESA update their 2700X system is showing 10+% improvement on a number of benchmarks. It is unknown if on Windows the impact will be the same. But you see how all the many variables could explain the differences.