The AMD 2nd Gen Ryzen Deep Dive: The 2700X, 2700, 2600X, and 2600 Tested
by Ian Cutress on April 19, 2018 9:00 AM ESTImprovements to the Cache Hierarchy
The biggest under-the-hood change for the Ryzen 2000-series processors is in the cache latency. AMD is claiming that they were able to knock one-cycle from L1 and L2 caches, several cycles from L3, and better DRAM performance. Because pure core IPC is intimately intertwined with the caches (the size, the latency, the bandwidth), these new numbers are leading AMD to claim that these new processors can offer a +3% IPC gain over the previous generation.

The numbers AMD gives are:
- 13% Better L1 Latency (1.10ns vs 0.95ns)
- 34% Better L2 Latency (4.6ns vs 3.0ns)
- 16% Better L3 Latency (11.0ns vs 9.2ns)
- 11% Better Memory Latency (74ns vs 66ns at DDR4-3200)
- Increased DRAM Frequency Support (DDR4-2666 vs DDR4-2933)
It is interesting that in the official slide deck AMD quotes latency measured as time, although in private conversations in our briefing it was discussed in terms of clock cycles. Ultimately latency measured as time can take advantage of other internal enhancements; however a pure engineer prefers to discuss clock cycles.
Naturally we went ahead to test the two aspects of this equation: are the cache metrics actually lower, and do we get an IPC uplift?
Cache Me Ousside, How Bow Dah?
For our testing, we use a memory latency checker over the stride range of the cache hierarchy of a single core. For this test we used the following:
- Ryzen 7 2700X (Zen+)
- Ryzen 5 2400G (Zen APU)
- Ryzen 7 1800X (Zen)
- Intel Core i7-8700K (Coffee Lake)
- Intel Core i7-7700K (Kaby Lake)
The most obvious comparison is between the AMD processors. Here we have the Ryzen 7 1800X from the initial launch, the Ryzen 5 2400G APU that pairs Zen cores with Vega graphics, and the new Ryzen 7 2700X processor.
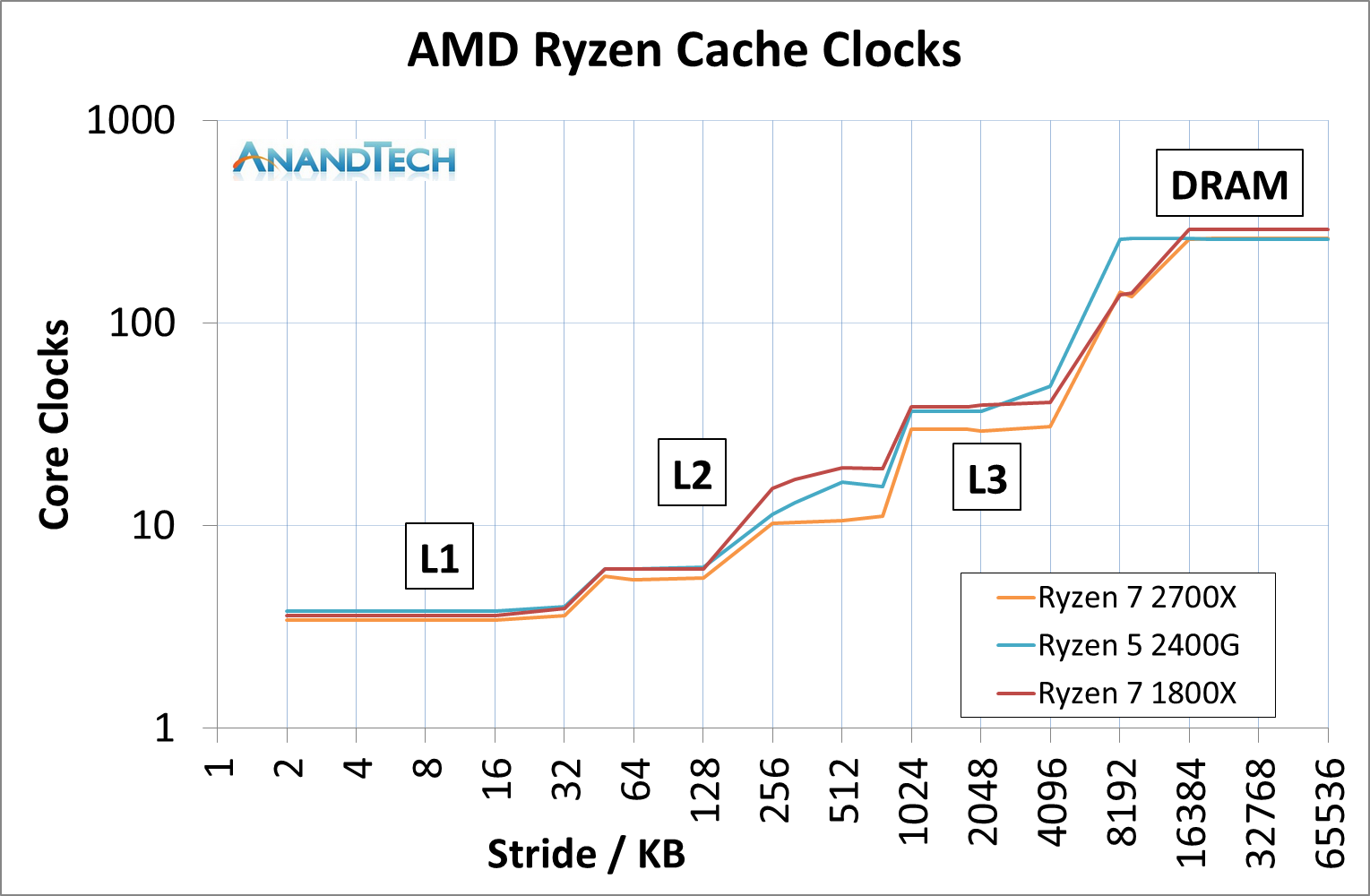
This graph is logarithmic in both axes.
This graph shows that in every phase of the cache design, the newest Ryzen 7 2700X requires fewer core clocks. The biggest difference is on the L2 cache latency, but L3 has a sizeable gain as well. The reason that the L2 gain is so large, especially between the 1800X and 2700X, is an interesting story.
When AMD first launched the Ryzen 7 1800X, the L2 latency was tested and listed at 17 clocks. This was a little high – it turns out that the engineers had intended for the L2 latency to be 12 clocks initially, but run out of time to tune the firmware and layout before sending the design off to be manufactured, leaving 17 cycles as the best compromise based on what the design was capable of and did not cause issues. With Threadripper and the Ryzen APUs, AMD tweaked the design enough to hit an L2 latency of 12 cycles, which was not specifically promoted at the time despite the benefits it provides. Now with the Ryzen 2000-series, AMD has reduced it down further to 11 cycles. We were told that this was due to both the new manufacturing process but also additional tweaks made to ensure signal coherency. In our testing, we actually saw an average L2 latency of 10.4 cycles, down from 16.9 cycles in on the Ryzen 7 1800X.
The L3 difference is a little unexpected: AMD stated a 16% better latency: 11.0 ns to 9.2 ns. We saw a change from 10.7 ns to 8.1 ns, which was a drop from 39 cycles to 30 cycles.
Of course, we could not go without comparing AMD to Intel. This is where it got very interesting. Now the cache configurations between the Ryzen 7 2700X and Core i7-8700K are different:
| CPU Cache uArch Comparison | ||
| AMD Zen (Ryzen 1000) Zen+ (Ryzen 2000) |
Intel Kaby Lake (Core 7000) Coffee Lake (Core 8000) |
|
| L1-I Size | 64 KB/core | 32 KB/core |
| L1-I Assoc | 4-way | 8-way |
| L1-D Size | 32 KB/core | 32 KB/core |
| L1-D Assoc | 8-way | 8-way |
| L2 Size | 512 KB/core | 256 KB/core |
| L2 Assoc | 8-way | 4-way |
| L3 Size | 8 MB/CCX (2 MB/core) |
2 MB/core |
| L3 Assoc | 16-way | 16-way |
| L3 Type | Victim | Write-back |
AMD has a larger L2 cache, however the AMD L3 cache is a non-inclusive victim cache, which means it cannot be pre-fetched into unlike the Intel L3 cache.
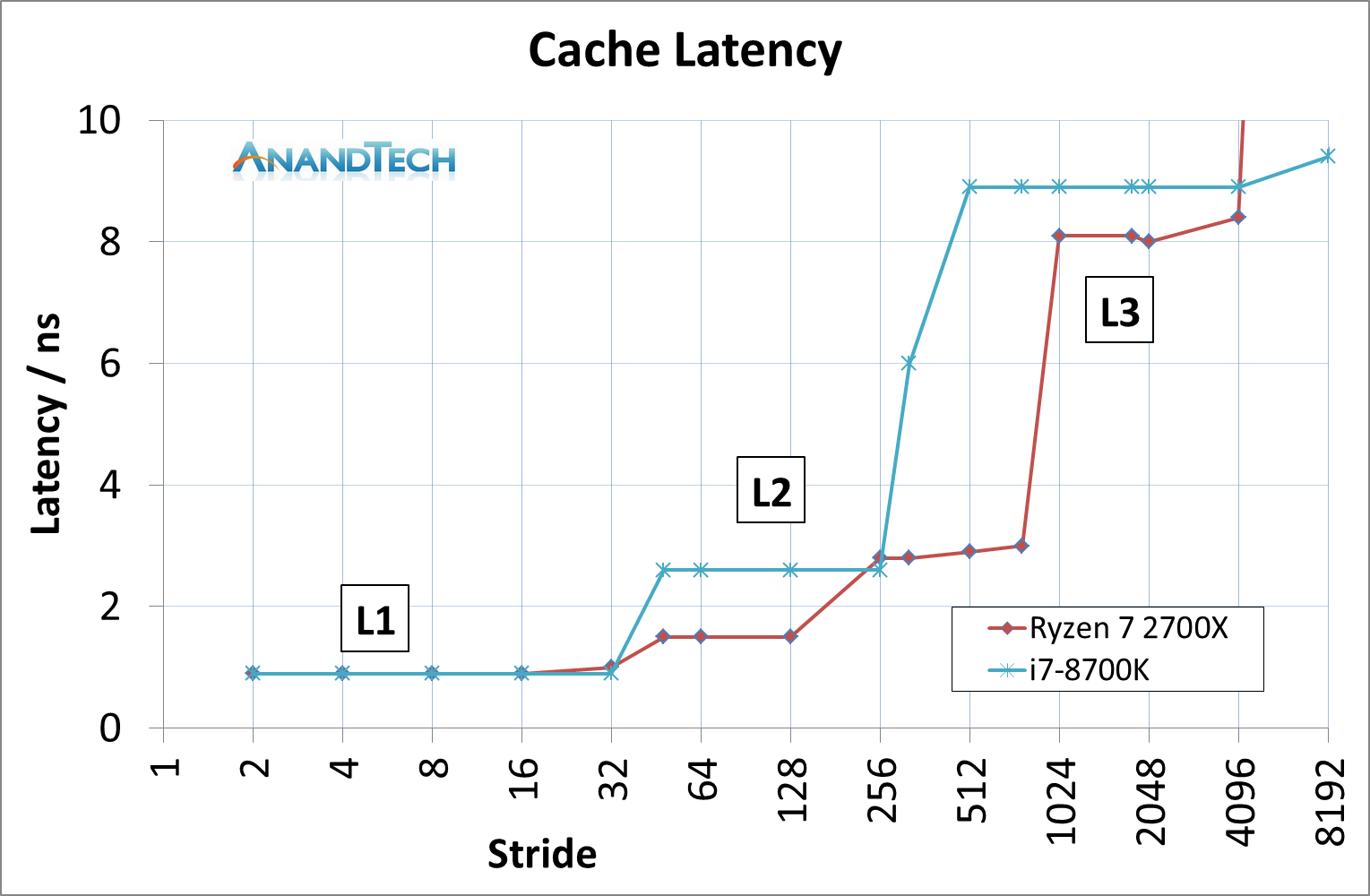
This was an unexpected result, but we can see clearly that AMD has a latency timing advantage across the L2 and L3 caches. There is a sizable difference in DRAM, however the core performance metrics are here in the lower caches.
We can expand this out to include the three AMD chips, as well as Intel’s Coffee Lake and Kaby Lake cores.

This is a graph using cycles rather than timing latency: Intel has a small L1 advantage, however the larger L2 caches in AMD’s Zen designs mean that Intel has to hit the higher latency L3 earlier. Intel makes quick work of DRAM cycle latency however.








545 Comments
View All Comments
Marlin1975 - Thursday, April 19, 2018 - link
Looks good, guess AMD will replace my Intel system next.Just waiting for GPU and memory prices to fall.
3DoubleD - Thursday, April 19, 2018 - link
Agreed... the waiting continuesWorldWithoutMadness - Thursday, April 19, 2018 - link
Lol, you might even wait until Zen 2 comes out next year or even later.Dragonstongue - Thursday, April 26, 2018 - link
should be out next year as AMD has been very much on the ball with Ryzen launches more or less to the DAY they claimed would launch which is very nice...basically what they are promising for product delivery they are doing what they say IMO, not to mention TSMC recently announced volume production of their 7nm, so that likely means GloFo will be very soon to follow, and AMD can use TSMC just the same :)t.s - Tuesday, July 31, 2018 - link
What @WWM want to say is: You can wait forever for the RAM price to go down, rather than when ryzen 2 out.StevoLincolnite - Thursday, April 19, 2018 - link
I still haven't felt limited by my old 3930K yet.Can't wait to see what Zen 2 brings and how Intel counters that.
mapesdhs - Friday, April 20, 2018 - link
If you ever do fancy a bit more oomph in the meantime (and assuming IPC is less important than threaded performance, eg. HandBrake is more important than PDF loading), a decent temporary sideways step for X79 is a XEON E5-2697 v2 (IB-EP). An oc'd 3930K is quicker for single-threaded of course, but for multithreaded the XEON does very well, easily beating an oc'd 3930K, and the XEON has native PCIe 3.0 so no need to bother with the not entirely stable forced NVIDIA tool. See my results (for FireFox, set Page Style to No Style in the View menu):http://www.sgidepot.co.uk/misc/tests-jj.txt
mapesdhs - Monday, April 23, 2018 - link
Correction, I meant the 2680 v2.Samus - Friday, April 20, 2018 - link
I never felt limited by my i5-4670k either, especially mildly overclocked to 4.0GHz.Until I build a new PC around the same old components because the MSI Z97 motherboard (thanks MSI) failed (it was 4 years old but still...) so I picked up a new i3-8350k + ASRock Z270 at Microcenter bundled together for $200 a month ago, and it's a joke how much faster it is than my old i5.
First off, it's noticeably faster, at STOCK, than the max stable overclock I could get on my old i5. Granted I replaced the RAM too, but still 16GB, now PC4-2400 instead of PC3-2133. Doubt it makes a huge difference.
Where things are noticeably faster comes down to boot times, app launches and gaming. All of this is on the same Intel SSD730 480GB SATA3 I've had for years. I didn't even do a fresh install, I just dropped it in and let Windows 10 rebuild the HAL, and reactivated with my product key.
Even on paper, the 8th gen i3's are faster than previous gen i5's. The i3 stock is still faster than the 4th gen i5 mildly overclocked.
I wish I waited. It's compelling (although more expensive) to build an AMD Ryzen 2 now. It really wasn't before, but now that performance is slightly better and prices are slightly lower, it would be worth the gamble.
gglaw - Saturday, April 21, 2018 - link
i think there's something wrong with your old Haswell setup if the difference is that noticeable. I have every generation of Intel I7 or I5 except Coffee Lake running in 2 rooms attached to each other, and I can't even notice a significant difference from my SANDY 2600k system with a SATA 850 Evo Pro sitting literally right next to my Kaby I7 with a 960 EVO NVMe SSD. I want to convince myself how much better the newer one is, but it just isn't. And this is 5 generations apart for the CPU's/mobos and using one of the fastest SSD's ever made compared to a SATA drive, although about the fastest SATA drive there is. Coffee Lake is faster than Kaby but so tiny between the equivalent I7 to I7, I can't see myself noticing a major difference.In the same room across from these 2 is my first Ryzen build, the 1800X also with an 960 EVO SSD. Again, I can barely convince myself it's a different system than the Sandy 2600k with SATA SSD. I have your exact Haswell I5 too, and it feels fast as hell still. Especially for app launches and gaming. The only time I notice major differences between these systems is when I'm encoding videos or running synthetic benchmarks. Just for the thrill of a new flagship release I just ordered the 2700X too and it'll be sitting next to the 1800X for another side by side experience. It'll be fun to setup but I'm pretty convinced I won't be able to tell the 2 systems apart when not benchmarking.