Sizing Up Servers: Intel's Skylake-SP Xeon versus AMD's EPYC 7000 - The Server CPU Battle of the Decade?
by Johan De Gelas & Ian Cutress on July 11, 2017 12:15 PM EST- Posted in
- CPUs
- AMD
- Intel
- Xeon
- Enterprise
- Skylake
- Zen
- Naples
- Skylake-SP
- EPYC
Memory Subsystem: Latency
The performance of modern CPUs depends heavily on the cache subsystem. And some applications depend heavily on the DRAM subsystem too. We used LMBench in an effort to try to measure cache and memory latency. The numbers we looked at were "Random load latency stride=16 Bytes".
| Mem Hierarchy |
AMD EPYC 7601 DDR4-2400 |
Intel Skylake-SP DDR4-2666 |
Intel Broadwell Xeon E5-2699v4 DDR4-2400 |
| L1 Cache cycles | 4 | 4 | 4 |
| L2 Cache cycles | 12 | 14-22 | 12-15 |
| L3 Cache 4-8 MB - cycles | 34-47 | 54-56 | 38-51 |
| 16-32 MB - ns | 89-95 ns | 25-27 ns (+/- 55 cycles?) |
27-42 ns (+/- 47 cycles) |
| Memory 384-512 MB - ns | 96-98 ns | 89-91 ns | 95 ns |
Previously, Ian has described the AMD Infinity Fabric that stitches the two CCXes together in one die and interconnects the 4 different "Zeppelin" dies in one MCM. The choice of using two CCXes in a single die is certainly not optimal for Naples. The local "inside the CCX" 8 MB L3-cache is accessed with very little latency. But once the core needs to access another L3-cache chunk – even on the same die – unloaded latency is pretty bad: it's only slightly better than the DRAM access latency. Accessing DRAM is on all modern CPUs a naturally high latency operation: signals have to travel from the memory controller over the memory bus, and the internal memory matrix of DDR4-2666 DRAM is only running at 333 MHz (hence the very high CAS latencies of DDR4). So it is surprising that accessing SRAM over an on-chip fabric requires so many cycles.
What does this mean to the end user? The 64 MB L3 on the spec sheet does not really exist. In fact even the 16 MB L3 on a single Zeppelin die consists of two 8 MB L3-caches. There is no cache that truly functions as single, unified L3-cache on the MCM; instead there are eight separate 8 MB L3-caches.
That will work out fine for applications that have a footprint that fits within a single 8 MB L3 slice, like virtual machines (JVM, Hypervisors based ones) and HPC/Big Data applications that work on separate chunks of data in parallel (for example, the "map" phase of "map/reduce"). However this kind of setup will definitely hurt the performance of applications that need "central" access to one big data pool, such as database applications and big data applications in the "Shuffle phase".
Memory Subsystem: TinyMemBench
To double check our latency measurements and get a deeper understanding of the respective architectures, we also use the open source TinyMemBench benchmark. The source was compiled for x86 with GCC 5.4 and the optimization level was set to "-O3". The measurement is described well by the manual of TinyMemBench:
Average time is measured for random memory accesses in the buffers of different sizes. The larger the buffer, the more significant the relative contributions of TLB, L1/L2 cache misses, and DRAM accesses become. All the numbers represent extra time, which needs to be added to L1 cache latency (4 cycles).
We tested with dual random read, as we wanted to see how the memory system coped with multiple read requests.
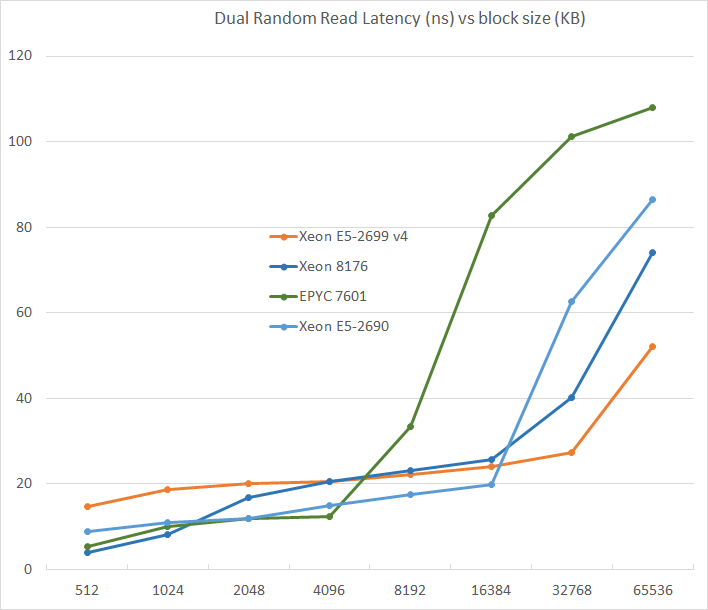
L3-cache sizes have increased steadily over the years. The Xeon E5 v1 had up to 20 MB, v3 came with 45 MB, and v4 "Broadwell EP" further increased this to 55 MB. But the fatter the cache, the higher the latency became. L3 latency doubled from Sandy Bridge-EP to Broadwell-EP. So it is no wonder that Skylake went for a larger L2-cache and a smaller but faster L3. The L2-cache offers 4 times lower latency at 512 KB.
AMD's unloaded latency is very competitive under 8 MB, and is a vast improvement over previous AMD server CPUs. Unfortunately, accessing more 8 MB incurs worse latency than a Broadwell core accessing DRAM. Due to the slow L3-cache access, AMD's DRAM access is also the slowest. The importance of unloaded DRAM latency should of course not be exaggerated: in most applications most of the loads are done in the caches. Still, it is bad news for applications with pointer chasing or other latency-sensitive operations.








219 Comments
View All Comments
ddriver - Tuesday, July 11, 2017 - link
Gotta love the "you don't care about the xeon prices" part thou. Now that intel don't have a performance advantage, and their product value at the high end is half that of amd, AT plays the "intel is the better brand" card. So expected...OZRN - Wednesday, July 12, 2017 - link
You need some perspective. Database licensing for Oracle happens per core, where Intel's performance is frequently better in a straight line and since they achieve it on lower core count it's actually better value for the use case. Higher per-CPU cost is not so much of a concern when you pay twice as much for a processor license to cover those cores.I'm an AMD fan and I made this account just for you, sweetheart, but don't blind yourself to the truth just because Intel has a history of shady business. In most regards this is a balanced review, and where it isn't, they tell you why it might not be. Chill out.
ddriver - Thursday, July 13, 2017 - link
You are such a clown. Nobody, I repeat, NOBODY on this planet uses 64 core 128 thread 512 gigabytes of ram servers to run a few MB worth of database. You telling me to get pespective thus can mean only two things, that you are a buthurt intel fanboy troll or that you are in serious need of head examination. Or maybe even both. At any rate, that perfectly explains your ridiculously low standards for "balanced review".Notmyusualid - Friday, July 14, 2017 - link
It seems no matter what opinion someone presents that might exhibit Intel in a better light - you are going to hate it anyway.What a life you must lead.
OZRN - Friday, July 14, 2017 - link
No, they don't. They use them to host gigabytes to terabytes worth of mission critical databases, with specified amounts of cores dedicated to seperate environments of hard partitioned data manipulation. I've done some quick math for you and in an average setup of Enterprise Edition of Oracle DB, with only the usually reported options and extras, this type of database would cost over $3.7m to run on *64 cores alone*. At this point, where is your hardware sunk costs argument?Also, I don't think anyone here is impressed by your ability to immediately personally insult people making valid points. Good luck finding your head that deep in your colon.
CajunArson - Tuesday, July 11, 2017 - link
"All of our testing was conducted on Ubuntu Server "Xenial" 16.04.2 LTS (Linux kernel 4.4.0 64 bit). The compiler that ships with this distribution is GCC 5.4.0."I'd recommend using a more updated distro and especially a more up to date compiler (GCC 5.4 is only a bug-fix release of a compiler from *2015*) if you want to see what these parts are truly capable of.
Phoronix does heavy-duty Linux reviews and got some major performance boosts on the i9 7900X simply by using up to date distros: http://www.phoronix.com/scan.php?page=article&...
Considering that Purley is just an upscaled version of the i9 7900X, I wouldn't be surprised to see different results.
CajunArson - Tuesday, July 11, 2017 - link
As a followup to my earlier comment, that Phoronix story, for example, shows a speedup factor of almost 5X on the C-ray benchmark simply by using a modern distro with some tuning for the more modern Skylake architecture.I'm not saying Purley would have a 5X speedup on C-ray per-say, but I'd be shocked if it didn't get a good boost using modern software that's actually designed for the Skylake architecture.
CoachAub - Wednesday, July 12, 2017 - link
Keywords: "actually designed for the Skylake architecture". Will there be optimizations for AMD Epyc chips?mkozakewich - Friday, July 14, 2017 - link
If it's a reasonable optimization, it makes sense to include it in the benchmark. If I were building these systems, I'd want to see benchmarks that resembled as closely as possible my company's workflow. (Which may be for older software or newer software; neither are inherently more relevant, though benchmarks on newer software will usually be relevant further into the future.)CajunArson - Tuesday, July 11, 2017 - link
And another followup: The time kernel compilation on the i9 7900X got almost a factor of 2 speedup over the Ubuntu 16.04 using more modern distros.