Sizing Up Servers: Intel's Skylake-SP Xeon versus AMD's EPYC 7000 - The Server CPU Battle of the Decade?
by Johan De Gelas & Ian Cutress on July 11, 2017 12:15 PM EST- Posted in
- CPUs
- AMD
- Intel
- Xeon
- Enterprise
- Skylake
- Zen
- Naples
- Skylake-SP
- EPYC
Java Performance
The SPECjbb 2015 benchmark has "a usage model based on a world-wide supermarket company with an IT infrastructure that handles a mix of point-of-sale requests, online purchases, and data-mining operations." It uses the latest Java 7 features and makes use of XML, compressed communication, and messaging with security.
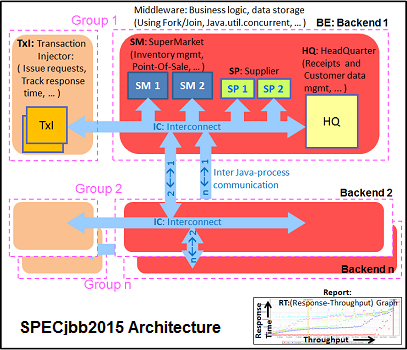
We tested SPECjbb with four groups of transaction injectors and backends. The reason why we use the "Multi JVM" test is that it is more realistic: multiple VMs on a server is a very common practice.
The Java version was OpenJDK 1.8.0_131. We applied relatively basic tuning to mimic real-world use, while aiming to fit everything inside a server with 128 GB of RAM:
The graph below shows the maximum throughput numbers for our MultiJVM SPECJbb test.
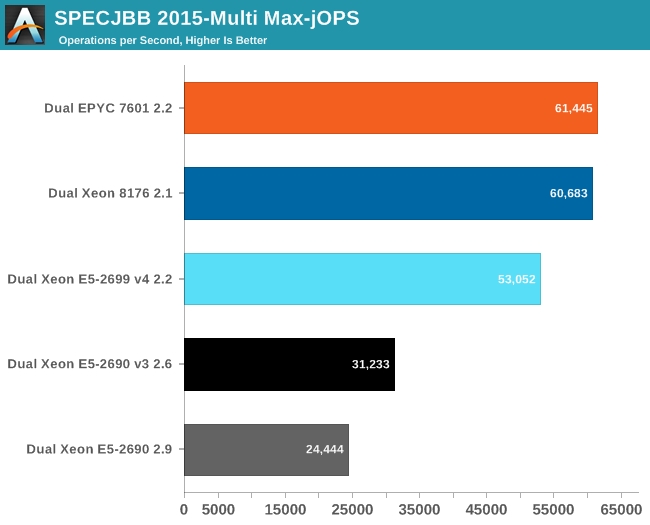
Even though our testing is not the ideal case for AMD (you would probably choose 8 or even 16 back-ends), the EPYC edges out the Xeon 8176. Using 8 JVMs increases the gap from 1% to 4-5%.
The Critical-jOPS metric is a throughput metric under response time constraint.
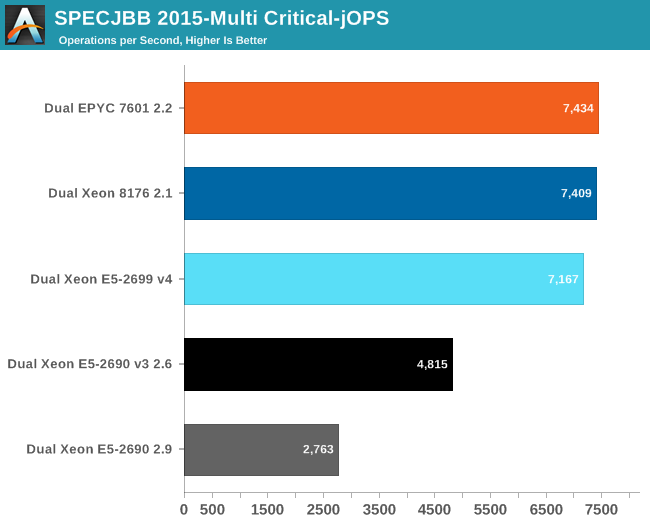
With this number of threads active, you can get much higher Critical-jOps by significantly increasing the RAM per JVM. However, we did not want that as this would mean we can not compare with systems that can only accommodate 128 GB of RAM.








219 Comments
View All Comments
oldlaptop - Thursday, July 13, 2017 - link
Why on earth is gcc -Ofast being used to mimic "real-world", non-"aggressively optimized"(!) conditions? This is in fact the *most* aggressive optimization setting available; it is very sensitive to the exact program being compiled at best, and generates bloated (low priority on code size) and/or buggy code at worst (possibly even harming performance if the generated code is so big as to harm cache coherency). Most real-world software will be built with -O2 or possibly -Os. I can't help but wonder why questions weren't asked when SPEC complained about this unwisely aggressive optimization setting...peevee - Thursday, July 13, 2017 - link
"added a second full-blown 512 bit AVX-512 unit. "Do you mean "added second 256 ALU, which in combination with the first one implements full 512-bit AVX-512 unit"?
peevee - Thursday, July 13, 2017 - link
"getting data from the right top node to the bottom left node – should demand around 13 cycles. And before you get too concerned with that number, keep in mind that it compares very favorably with any off die communication that has to happen between different dies in (AMD's) Multi Chip Module (MCM), with the Skylake-SP's latency being around one-tenth of EPYC's."1/10th? Asking data from L3 on the chip next to it will take 130 (or even 65 if they are talking about averages) cycles? Does not sound realistic, you can request data from RAM at similar latencies already.
AmericasCup - Friday, July 14, 2017 - link
'For enterprises with a small infrastructure crew and server hardware on premise, spending time on hardware tuning is not an option most of the time.'Conversely, our small crew shop has been tuning AMD (selected for scalar floating point operations performance) for years. The experience and familiarity makes switching less attractive.
Also, you did all this in one week for AMD and two weeks for Intel? Did you ever sleep? KUDOS!
JohanAnandtech - Friday, July 21, 2017 - link
Thanks for appreciating the effort. Luckily, I got some help from Ian on Tuesday. :-)AntonErtl - Friday, July 14, 2017 - link
According to http://www.anandtech.com/show/10158/the-intel-xeon... if you execute just one AVX256 instruction on one core, this slows down the clocks of all E5v4 cores on the same socket for at least 1ms. Somewhere I read that newer Xeons only slow down the core that executes the AVX256 instruction. I expect that it works the same way for AVX512, and yes, this means that if you don't have a load with a heavy proportion of SIMD instructions, you are better off with AVX128 or SSE. The AMD variant of having only 128-bit FPUs and no clock slowdown looks better balanced to me. It might not win Linpack benchmark competitions, but for that one uses GPUs anyway these days.wagoo - Sunday, July 16, 2017 - link
Typo on the CLOSING THOUGHTS page: "dual Silver Xeon solutions" (dual socket)Great read though, thanks! Can finally replace my dual socket shanghai opteron home server soon :)
Chaser - Sunday, July 16, 2017 - link
AMD's CPU future is looking very promising!bongey - Tuesday, July 18, 2017 - link
EPYC power consumption is just wrong. Somehow you are 50W over what everyone else is getting at idle. https://www.servethehome.com/amd-epyc-7601-dual-so...Nenad - Thursday, July 20, 2017 - link
Interesting SPECint2006 results:- Intel in their slide #9 claims that Intel 8160 is 2% faster than EPYC 7601
- Anandtech in article tests that EPYC 7601 is 42% faster than Intel 8176
Those two are quite different, even if we ignore that 8176 should be faster than 8160. In other words, those Intel test results look very suspicious.