Sizing Up Servers: Intel's Skylake-SP Xeon versus AMD's EPYC 7000 - The Server CPU Battle of the Decade?
by Johan De Gelas & Ian Cutress on July 11, 2017 12:15 PM EST- Posted in
- CPUs
- AMD
- Intel
- Xeon
- Enterprise
- Skylake
- Zen
- Naples
- Skylake-SP
- EPYC
Memory Subsystem: Latency
The performance of modern CPUs depends heavily on the cache subsystem. And some applications depend heavily on the DRAM subsystem too. We used LMBench in an effort to try to measure cache and memory latency. The numbers we looked at were "Random load latency stride=16 Bytes".
| Mem Hierarchy |
AMD EPYC 7601 DDR4-2400 |
Intel Skylake-SP DDR4-2666 |
Intel Broadwell Xeon E5-2699v4 DDR4-2400 |
| L1 Cache cycles | 4 | 4 | 4 |
| L2 Cache cycles | 12 | 14-22 | 12-15 |
| L3 Cache 4-8 MB - cycles | 34-47 | 54-56 | 38-51 |
| 16-32 MB - ns | 89-95 ns | 25-27 ns (+/- 55 cycles?) |
27-42 ns (+/- 47 cycles) |
| Memory 384-512 MB - ns | 96-98 ns | 89-91 ns | 95 ns |
Previously, Ian has described the AMD Infinity Fabric that stitches the two CCXes together in one die and interconnects the 4 different "Zeppelin" dies in one MCM. The choice of using two CCXes in a single die is certainly not optimal for Naples. The local "inside the CCX" 8 MB L3-cache is accessed with very little latency. But once the core needs to access another L3-cache chunk – even on the same die – unloaded latency is pretty bad: it's only slightly better than the DRAM access latency. Accessing DRAM is on all modern CPUs a naturally high latency operation: signals have to travel from the memory controller over the memory bus, and the internal memory matrix of DDR4-2666 DRAM is only running at 333 MHz (hence the very high CAS latencies of DDR4). So it is surprising that accessing SRAM over an on-chip fabric requires so many cycles.
What does this mean to the end user? The 64 MB L3 on the spec sheet does not really exist. In fact even the 16 MB L3 on a single Zeppelin die consists of two 8 MB L3-caches. There is no cache that truly functions as single, unified L3-cache on the MCM; instead there are eight separate 8 MB L3-caches.
That will work out fine for applications that have a footprint that fits within a single 8 MB L3 slice, like virtual machines (JVM, Hypervisors based ones) and HPC/Big Data applications that work on separate chunks of data in parallel (for example, the "map" phase of "map/reduce"). However this kind of setup will definitely hurt the performance of applications that need "central" access to one big data pool, such as database applications and big data applications in the "Shuffle phase".
Memory Subsystem: TinyMemBench
To double check our latency measurements and get a deeper understanding of the respective architectures, we also use the open source TinyMemBench benchmark. The source was compiled for x86 with GCC 5.4 and the optimization level was set to "-O3". The measurement is described well by the manual of TinyMemBench:
Average time is measured for random memory accesses in the buffers of different sizes. The larger the buffer, the more significant the relative contributions of TLB, L1/L2 cache misses, and DRAM accesses become. All the numbers represent extra time, which needs to be added to L1 cache latency (4 cycles).
We tested with dual random read, as we wanted to see how the memory system coped with multiple read requests.
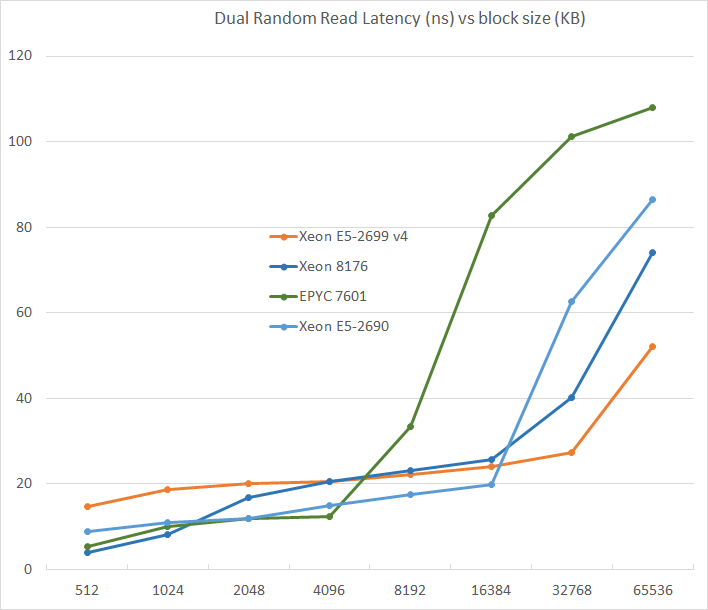
L3-cache sizes have increased steadily over the years. The Xeon E5 v1 had up to 20 MB, v3 came with 45 MB, and v4 "Broadwell EP" further increased this to 55 MB. But the fatter the cache, the higher the latency became. L3 latency doubled from Sandy Bridge-EP to Broadwell-EP. So it is no wonder that Skylake went for a larger L2-cache and a smaller but faster L3. The L2-cache offers 4 times lower latency at 512 KB.
AMD's unloaded latency is very competitive under 8 MB, and is a vast improvement over previous AMD server CPUs. Unfortunately, accessing more 8 MB incurs worse latency than a Broadwell core accessing DRAM. Due to the slow L3-cache access, AMD's DRAM access is also the slowest. The importance of unloaded DRAM latency should of course not be exaggerated: in most applications most of the loads are done in the caches. Still, it is bad news for applications with pointer chasing or other latency-sensitive operations.








219 Comments
View All Comments
Shankar1962 - Thursday, July 13, 2017 - link
So you think Intel won't release anything new again by then? Intel would be ready for cascadelake by then. None of the big players won't switch to AMD. Skylake alone is enough to beat epyc handsomely and cascadelake will just blow epyc. Its funny people are looking at lab results when real workloads are showing 1.5-1.7x speed improvementPixyMisa - Saturday, July 15, 2017 - link
This IS comparing AMD to Intel's newest CPUs, you idiot. Skylake loses to Epyc outright on many workloads, and is destroyed by Epyc on TCO.Shankar1962 - Sunday, July 16, 2017 - link
Mind your language assholeEither continue the debate or find another place for your shit and ur language
Real workloads don't happen in the labs you moron
Real workloads are specific to each company and Intel is ahead either way
If you have the guts come out with Q3 Q4 2017 and 2018 revenues from AMD
If you come back debating epyc won over skylake if AMD gets 5-10% share then i pity your common sense and your analysis
You are a bigger idiot because you spoiled a healthy thread where people were taking sides by presenting technical perspective
PixyMisa - Tuesday, July 25, 2017 - link
I'm sorry you're an idiot.Shankar1962 - Thursday, July 13, 2017 - link
Does not matter. We can debate this forever but Intel is just ahead and better optimized for real world workloads. Nvidia i agree is a potential threat and ahead in AI workloads which is the future but AMD is just an unnecessary hype. Since the fan boys are so excited with lab results (funny) lets look at Q3,Q4 results to see how many are ordering to test it for future deployment.martinpw - Wednesday, July 12, 2017 - link
I'm curious about the clock speed reduction with AVX-512. If code makes use of these instructions and gets a speedup, will all other code slow down due to lower overall clock speeds? In other words, how much AVX-512 do you have to use before things start clocking down? It feels like it might be a risk that AVX-512 may actually be counterproductive if not used heavily.msroadkill612 - Wednesday, July 12, 2017 - link
(sorry if a repost)Well yeah, but this is where it starts getting weird - 4-6 vega gpuS, hbm2 ram & huge raid nvme , all on the second socket of your 32 core, c/gpu compute ~Epyc server:
https://marketrealist.imgix.net/uploads/2017/07/A1...
from
http://marketrealist.com/2017/07/how-amd-plans-to-...
All these fabric linked processors, can interact independently of the system bus. Most data seems to get point to point in 2 hops, at about 40GBps bi-directional (~40 pcie3 lanes, which would need many hops), and can be combined to 160GBps - as i recall.
Suitably custom hot rodded for fabric rather than pcie3, the nvme quad arrays could reach 16MBps sequential imo on epycs/vegaS native nvme ports.
To the extent that gpuS are increasing their role in big servers, intel and nvidea simply have no answer to amd in the bulk of this market segment.
davide445 - Wednesday, July 12, 2017 - link
Finally real competition in the HPC market. Waiting for the next top500 AMD powered supercomputer.Shankar1962 - Wednesday, July 12, 2017 - link
Intel makes $60billion a year and its official that Skylake was shipping from Feb17 so i do not understand this excitement from AMD fan boys......if it is so good can we discuss the quarterly revenues between these companies? Why is AMD selling for very low prices when you claim superior performance over Intel? You can charge less but almost 40-50% cheap compared to Intel really?AMD exists because they are always inferior and can beat Intel only by selling for low prices and that too for what gaining 5-10% market which is just a matter of time before Intel releases more SKUs to grab it back
What about the software optimizations and extra BOM if someone switches to AMD?
What if AMD goes into hibernation like they did in last 5-6years?
Can you mention one innovation from AMD that changed the world?
Intel is a leader and all the technology we enjoy today happenned because of Intel technology.
Intel is a data center giant have head start have the resources money acquisitions like altera mobileeye movidus infineon nirvana etc and its just impossible that they will lose
Even if all the competent combines Intel will maintain atleast 80% share even 10years from now
Shankar1962 - Wednesday, July 12, 2017 - link
To add onNo one cares about these lab tests. Let's talk about the real world work loads.
Look at what Google AWS ATT etc has to say as they already switched to xeon sky lake
We should not really be debating if we have the clarity that we are talking about AMD getting just 5% -10% share by selling high end products they have for cheap prices....they fo not make too much money by doing that.....they have no other option as thats the only way they can dream of a 5-10% market share
For Analogy think Intel in semiconductor as Apple in selling smartphones
Intel has gross margins of ~63%
They have a solid product portfolio technologies and roadmap .....we can debate this forever but the revenues profits innovations and history between these companies can answer everything