Sizing Up Servers: Intel's Skylake-SP Xeon versus AMD's EPYC 7000 - The Server CPU Battle of the Decade?
by Johan De Gelas & Ian Cutress on July 11, 2017 12:15 PM EST- Posted in
- CPUs
- AMD
- Intel
- Xeon
- Enterprise
- Skylake
- Zen
- Naples
- Skylake-SP
- EPYC
Memory Subsystem: Latency
The performance of modern CPUs depends heavily on the cache subsystem. And some applications depend heavily on the DRAM subsystem too. We used LMBench in an effort to try to measure cache and memory latency. The numbers we looked at were "Random load latency stride=16 Bytes".
| Mem Hierarchy |
AMD EPYC 7601 DDR4-2400 |
Intel Skylake-SP DDR4-2666 |
Intel Broadwell Xeon E5-2699v4 DDR4-2400 |
| L1 Cache cycles | 4 | 4 | 4 |
| L2 Cache cycles | 12 | 14-22 | 12-15 |
| L3 Cache 4-8 MB - cycles | 34-47 | 54-56 | 38-51 |
| 16-32 MB - ns | 89-95 ns | 25-27 ns (+/- 55 cycles?) |
27-42 ns (+/- 47 cycles) |
| Memory 384-512 MB - ns | 96-98 ns | 89-91 ns | 95 ns |
Previously, Ian has described the AMD Infinity Fabric that stitches the two CCXes together in one die and interconnects the 4 different "Zeppelin" dies in one MCM. The choice of using two CCXes in a single die is certainly not optimal for Naples. The local "inside the CCX" 8 MB L3-cache is accessed with very little latency. But once the core needs to access another L3-cache chunk – even on the same die – unloaded latency is pretty bad: it's only slightly better than the DRAM access latency. Accessing DRAM is on all modern CPUs a naturally high latency operation: signals have to travel from the memory controller over the memory bus, and the internal memory matrix of DDR4-2666 DRAM is only running at 333 MHz (hence the very high CAS latencies of DDR4). So it is surprising that accessing SRAM over an on-chip fabric requires so many cycles.
What does this mean to the end user? The 64 MB L3 on the spec sheet does not really exist. In fact even the 16 MB L3 on a single Zeppelin die consists of two 8 MB L3-caches. There is no cache that truly functions as single, unified L3-cache on the MCM; instead there are eight separate 8 MB L3-caches.
That will work out fine for applications that have a footprint that fits within a single 8 MB L3 slice, like virtual machines (JVM, Hypervisors based ones) and HPC/Big Data applications that work on separate chunks of data in parallel (for example, the "map" phase of "map/reduce"). However this kind of setup will definitely hurt the performance of applications that need "central" access to one big data pool, such as database applications and big data applications in the "Shuffle phase".
Memory Subsystem: TinyMemBench
To double check our latency measurements and get a deeper understanding of the respective architectures, we also use the open source TinyMemBench benchmark. The source was compiled for x86 with GCC 5.4 and the optimization level was set to "-O3". The measurement is described well by the manual of TinyMemBench:
Average time is measured for random memory accesses in the buffers of different sizes. The larger the buffer, the more significant the relative contributions of TLB, L1/L2 cache misses, and DRAM accesses become. All the numbers represent extra time, which needs to be added to L1 cache latency (4 cycles).
We tested with dual random read, as we wanted to see how the memory system coped with multiple read requests.
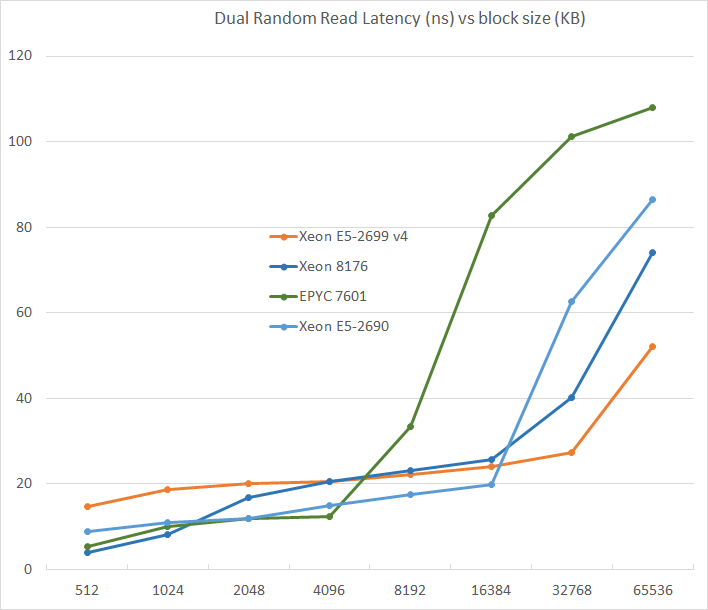
L3-cache sizes have increased steadily over the years. The Xeon E5 v1 had up to 20 MB, v3 came with 45 MB, and v4 "Broadwell EP" further increased this to 55 MB. But the fatter the cache, the higher the latency became. L3 latency doubled from Sandy Bridge-EP to Broadwell-EP. So it is no wonder that Skylake went for a larger L2-cache and a smaller but faster L3. The L2-cache offers 4 times lower latency at 512 KB.
AMD's unloaded latency is very competitive under 8 MB, and is a vast improvement over previous AMD server CPUs. Unfortunately, accessing more 8 MB incurs worse latency than a Broadwell core accessing DRAM. Due to the slow L3-cache access, AMD's DRAM access is also the slowest. The importance of unloaded DRAM latency should of course not be exaggerated: in most applications most of the loads are done in the caches. Still, it is bad news for applications with pointer chasing or other latency-sensitive operations.








219 Comments
View All Comments
JohanAnandtech - Friday, July 21, 2017 - link
Thanks! It is was a challenge, and we will update this article later on, when better kernel support is available.serendip - Tuesday, July 11, 2017 - link
What idiot marketroid thought it was cool to have a huge list of SKUs and gimped "precious metals" branding? I'd like to see Epyc kicking Xeon butt simply because AMD has much more sensible product lists and there's not much gimping going on.ParanoidFactoid - Tuesday, July 11, 2017 - link
Reading through this, the takeaway seems thus. Epyc has latency concerns in communicating between CCX blocks, though this is true of all NUMA systems. If your application is latency sensitive, you either want a kernel that can dynamically migrate threads to keep them close to their memory channel - with an exposed API so applications can request migration. (Linux could easily do this, good luck convincing MS). OR, you take the hit. OR, you buy a monolithic die Intel solution for much more capital outlay. Further, the takeaway on Intel is, they have the better technology. But their market segmentation strategy is so confusing, and so limiting, it's near impossible to determine best cost/performance for your application. So you wind up spending more than expected anyway. AMD is much more open and clear about what they can and can't do. Intel expects to make their money by obfuscating as part of their marketing strategy. Finally, Intel can go 8 socket, so if you need that - say, high core low latency securities trading - they're the only game in town. Sun, Silicon Graphics, and IBM have all ceded that market.msroadkill612 - Wednesday, July 12, 2017 - link
"it's near impossible to determine best cost/performance for your application. So you wind up spending more than expected anyway. AMD is much more open and clear about what they can and can't do. Intel expects to make their money by obfuscating as part of their marketing strategy.Finally, Intel can go 8 socket, so if you need that - say, high core low latency securities trading - they're the only game in town. Sun, Silicon Graphics, and IBM have all ceded that market."
& given time is money, & intelwastes customers time, then intel is expensive.
Those guys will go intel anyway, but just sayin, there is already talk of a 48 core zen cpu, making 98 cores on a mere 2p mobo.
As i have posted b4, if wall street starts liking gpu compute for prompter answers, amdS monster apuS will be unanswerable.
nils_ - Wednesday, July 19, 2017 - link
98 cores on a 2p mobo isn't quite right if you keep in mind that the 32 core versions already constitute a 4 CPU system, unless AMD somehow manages to get more cores on a single die.nils_ - Wednesday, July 19, 2017 - link
Good analysis, although Sun and IBM are still coming out with new CPUs and at least with IBM there is renewed interest in the POWER ecosystem.eek2121 - Wednesday, July 12, 2017 - link
, but rather AMD's spanking new EPYC server CPU. Both CPUs are without a doubt very different: micro architecture, ISA extentions, <snip>Should be extensions.
intelemployee2012 - Wednesday, July 12, 2017 - link
After looking at the number of people who really do not fully understand the entire architecture and workloads and thinking that AMD Naples is superior because it has more cores, pci lanes etc is surprising.AMD made a 32 core server by gluing four 8core desktop dies whereas Intel has a single die balanced datacenter specific architecture which offers more perf if you make the entire Rack comparison. It's not the no of cores its the entire Rack which matters.
Intel cores are superior than AMD so a 28 core xeon is equal to ~40 cores if you compare again Ryzen core so this whole 28core vs 32core is a marketing trick. Everyone thinks Intel is expensive but if you go by performance per dollar Intel has a cheaper option at every price point to match Naples without compromising perf/dollar.
To be honest with so many Fabs, don't you think Intel is capable of gluing desktop dies to create a 32core,64core or evn 128core server (if it wants to) if thats the implementation style it needs to adopt like AMD?
The problem these days is layman looks at just numbers but that's not how you compare.
sharath.naik - Wednesday, July 12, 2017 - link
Agree, Most who look at these numbers will walk away thinking AMD is doing well with EPYC. The article points out the approach to testing and also states the performance challenges with EPYC, which can be missed who reading this review without the prior review on the older Xeons. For example the Big data test, I bet the newbies will walk away thinking EPYC beats the older XEONS E5 v4, as thats what the graphs show,without ever looking back at the numbers for a single 22 core Xeon e5 v4. So yes, a few back links in the article will be helpful.warreo - Wednesday, July 12, 2017 - link
Not a fanboi of either company, but care to elaborate more? I checked the original Xeon E5 v4 review. It shows that a single Xeon E5 v4 performs about 10% slower than a dual setup. Extrapolating that here, that means the single Xeon E5 v4 setup would be right around 4.5 jobs per day, which would make it roughly 50% slower than the dual Epyc and Xeon 8176.Sure, you could argue perf/dollar is better against a dual Epyc setup...but one could make the same argument against Intel's Skylake Xeons? I also wouldn't expect the performance to scale linearly anyway. Please let me know what I'm missing.