Arm Announces Neoverse V1, N2 Platforms & CPUs, CMN-700 Mesh: More Performance, More Cores, More Flexibility
by Andrei Frumusanu on April 27, 2021 9:00 AM EST- Posted in
- CPUs
- Arm
- Servers
- Infrastructure
- Neoverse N1
- Neoverse V1
- Neoverse N2
- CMN-700
The Neoverse V1 Microarchitecture: Platform Enhancements
Aside from the core-side microarchitectural aspects of the V1, the new design also features some new system-facing novelties that promise to help vendors integrate the CPU IP better in larger scale implementations.
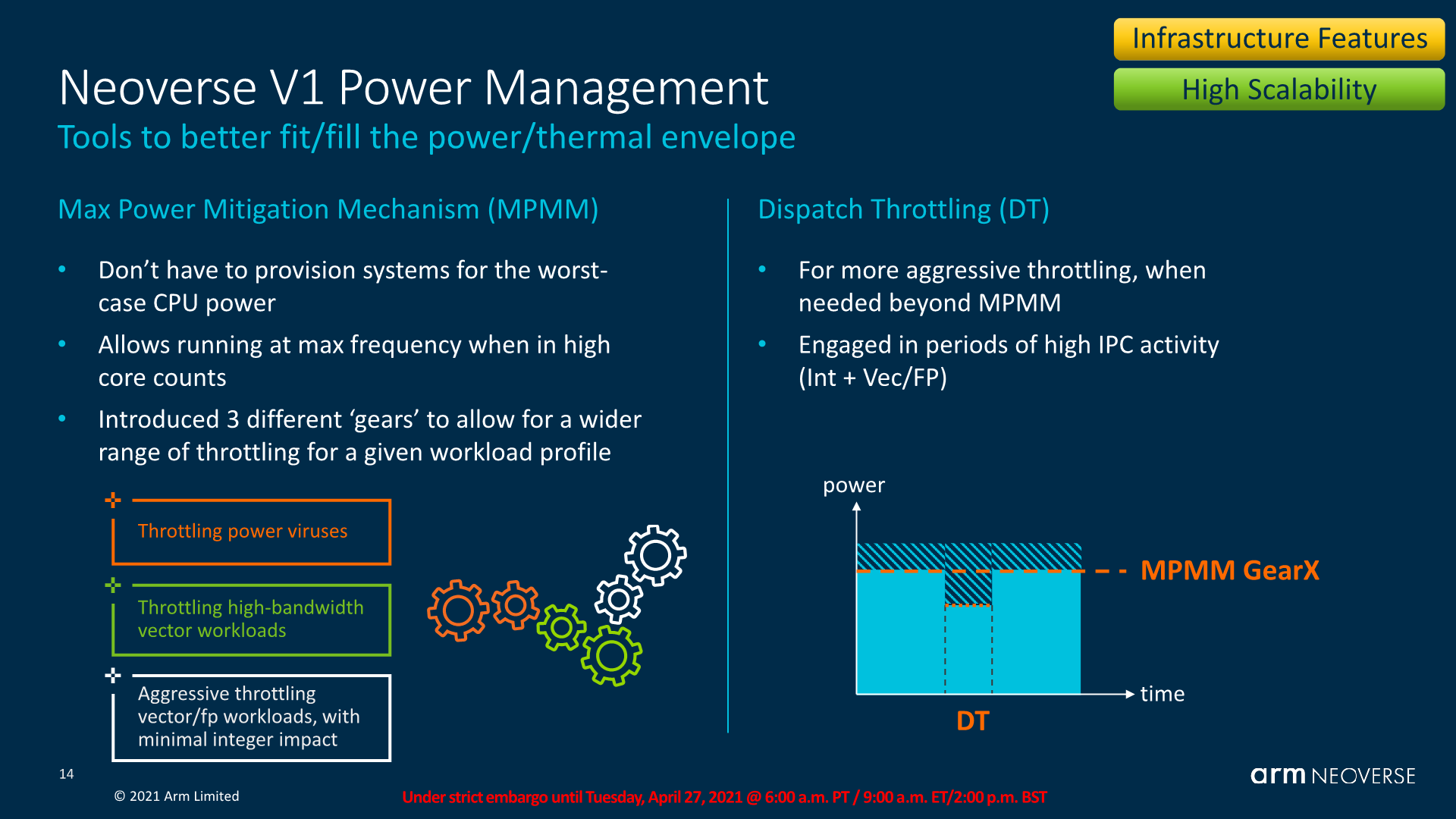
MPAM, or Max Power Mitigation Mechanism is a new fine-grained (to around 100 clock cycles) power management mechanism that promises to help smooth out the power behaviour of the core, and allow vendors’ implementations of the chip’s power delivery mechanisms to be so to say, be built to lesser requirements.
As we’ve seen in our review of the Ampere Altra, instead of fluctuating frequency at maximum TDP like how most x86 CPUs behave right now, the chip rather prefers to stay most of the time at maximum frequency, with the actual power consumption many times landing in at quite below the TDP (maximum allowed power consumption). A mechanism such as MPAM would allow, if possible, for the system’s average frequency to be higher by throttling the power limited cores to a finer degree. The mechanism to which this can be achieved can also include microarchitectural features such as dispatch throttling where the core slows down the dispatched instructions, smoothing out high power requirements in workloads having high execution periods, particularly important now with the new wider 2x256b SVE pipelines for example.

MPAM is a different mechanism helping interactions in larger system implementations. The Memory partitioning and monitoring feature is supposed to help with quality of service and reducing side-effects of noisy neighbours in deployments where multiple workloads, such as multiple VMs or processes, operate on the same system. This naturally requires software-hardware cooperation and implementation, but should be something that is particularly helpful in cloud environments.
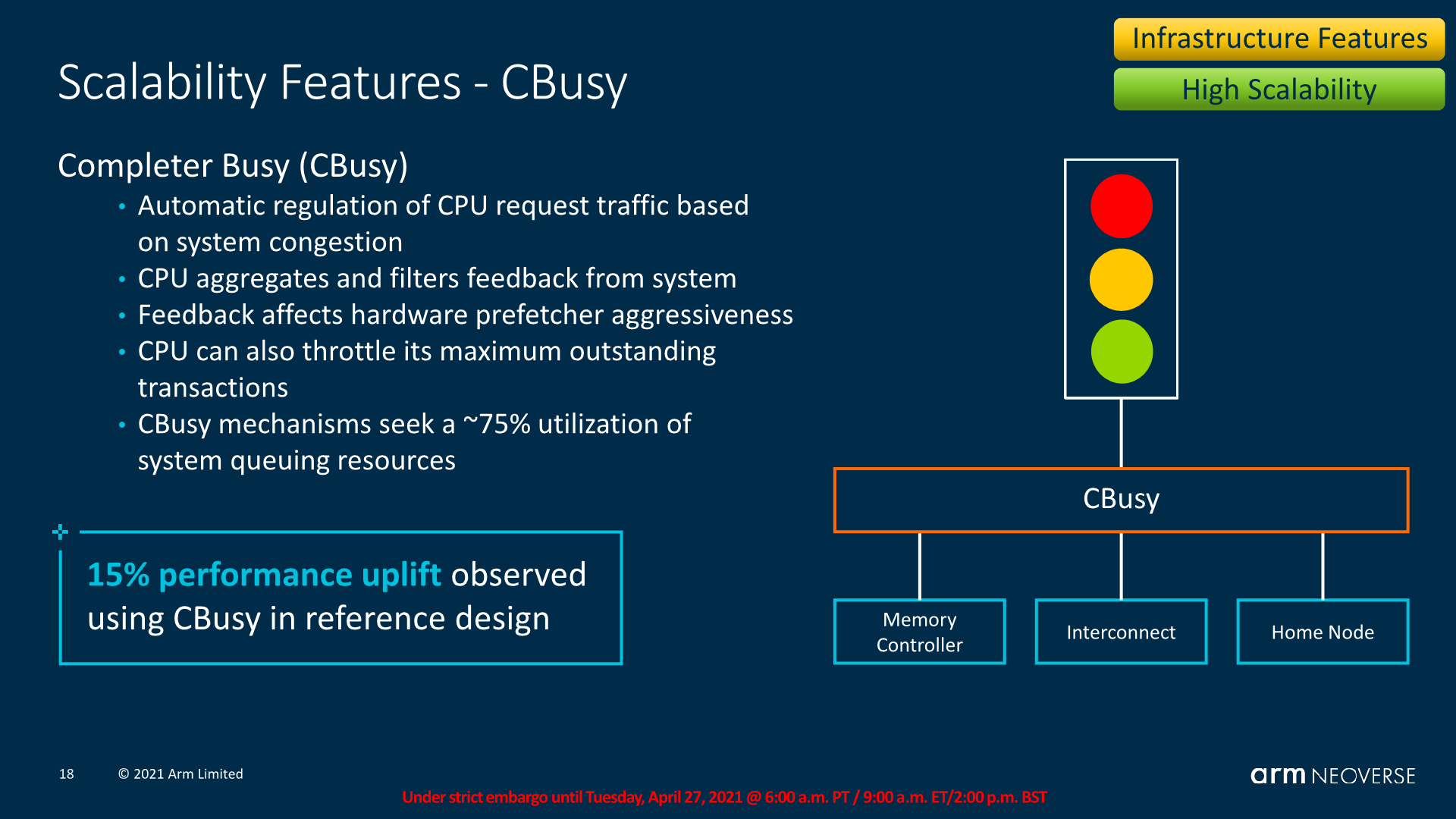
CBusy or Completer Busy is also a new system-side mechanism where the CPU cores interact with the mesh interconnect on a feedback-based basis, where the CPUs can vary their memory prefetcher aggressiveness depending on the overall mesh and system memory load. This ties in with the previously mentioned dynamic prefetcher behaviour where one can have the best of both worlds – better prefetching for more performance per core when the bandwidth is available, and very conservative prefetching when the system is under high load and there’s no room for wasted speculative bandwidth and data transfers.








95 Comments
View All Comments
yeeeeman - Tuesday, April 27, 2021 - link
what about a cortex a55 successor?SarahKerrigan - Tuesday, April 27, 2021 - link
I'd expect to see one next month launching alongside Matterhorn.eastcoast_pete - Tuesday, April 27, 2021 - link
Hi Sarah, can you post any links (including rumors) about that? Given ARM's focus on bigger, high performance-oriented designs, the LITTLE cores haven't gotten a lot of love in recent years. The persistence of the in-order designs for ARM LITTLE cores is one of the reasons why I find the dominance of ARM troubling; that clearly stood still because there is nowhere else to turn to for many, i.e. they didn't have to change it. In x86, at least we have two larger players having their own, yet compatible designs.SarahKerrigan - Tuesday, April 27, 2021 - link
I've seen it reported in a few places, including on RWT which is a pain to search - but since task migration generally requires compatible instruction sets between big and little cores, it's pretty clear that Matterhorn will bring a small, low-power friend when it arrives.Raqia - Tuesday, April 27, 2021 - link
I wonder if they could simply repurpose either a refresh of the A73 or A75 as the little core. Surely with the new fabrication processes available, die area relative to a big Matterhorn core should be comparable to A55 vs A78/X1, but the question becomes performance / energy. Integer performance of A75/73 vs. Ice Storm is comparable with the former winning by a bit in FP, but efficiency is light years apart:https://images.anandtech.com/doci/13614/SPEC-perf-...
https://images.anandtech.com/doci/16192/spec2006_A...
SarahKerrigan - Tuesday, April 27, 2021 - link
I think use of a refreshed A65 without multithreading and with the new ops seems more plausible to me.Raqia - Tuesday, April 27, 2021 - link
That could make sense; there's fairly little information on the micro-architecture of the A65 or A65AE at present except that it does do OoOE, and it's unclear what clocks and efficiency it can achieve as well:https://developer.arm.com/documentation/100439/010...
It does sport a bigger maximum L2 configuration than the A55. They do need to up their game here as the A55 makes a pretty poor showing for efficiency compared to Apple's small core (which got even worse in the A14 generation):
https://images.anandtech.com/doci/14072/SPEC2006ef...
At least wattage and hence current draw is low.
SarahKerrigan - Tuesday, April 27, 2021 - link
A65 is E1, which has had a uarch dive on this site.Raqia - Wednesday, April 28, 2021 - link
Got it, thanks for that! The A65 is interesting, without SMT they are quoting a pretty modest bump in integer performance < 20% at a bit more than half the power of A55 at 7nm:https://images.anandtech.com/doci/13959/07_Infra%2...
https://images.anandtech.com/doci/13959/07_Infra%2...
They could probably tune this to be better without SMT, but are you against having SMT for security reasons?
It's still not close to Apple's small cores in performance, but efficiency might be in the same ballpark now. ARM designs are quite good in terms of PPA but even their performance oriented X1 is likely only 70% the die area as a Firestorm core, and their cache hierarchies are more complex as core designs pull double duty for servers parts too.
It probably made sense to have fewer transistors per CPU core as quite a few Android SoC vendors integrated modems on die, but this may change once Qualcomm digests its Nuvia purchase and move to a smaller node. All parties may hit a wall for per core improvements as slowing SRAM density improvements at new nodes bottleneck what gains are gotten from logic density improvements.
Kangal - Thursday, April 29, 2021 - link
TL;DR - ARM needs to focus on a new product stack. It needs to have a diverse ARMv9 lineup of small, medium, large chipset options. With the small chipset being very scalable down to Tiny IoT Sensor level. Whereas the large chipset being scalable up to large supercomputers and servers. Whilst the medium chipset focusing on phones and tablets. As this covers full SoC, it includes both CPUs and GPUs.Long version:
I know making these architectures is a huge challenge, but ARM has been a little lazy in some scenarios. I know they're basically following the money in the industry, and that means chasing the "phablet" market for CPUs and GPUs. But they've been leaving themselves vulnerable to gaps, in either smaller power or larger power systems, that can be exploited by competitors, such as RISC-V. If not, even x86 might poke some wins here and there.
Ages ago, like 2013, they had the A7 (tiny), A15 (small), and A57 (medium) core designs. Basically covering most bases. Along with the Mali-400 iGPU, and 1GB-2GB Shared-RAM, to do some compute tasks. To say ARM was innovative would be a disservice to the technology they brought forward. That's in contrast to x86 Intel's Atom (small) and Intel's Core-i7Y/M (large), as well as Intel Iris Pro iGPU with 8GB Shared-RAM in systems of the time. Then ARM made the leap into 64bit processing around 2016. The lineup evolved into the A35 (tiny), A53 (small), A73 (medium) core designs, running with 1GB-2GB-4GB sRAM, and used modest G31 (tiny) to G51 (small) to G71 (medium) iGPU options. Again, this lineup was very innovative and impressive. Contrast that to the new x86 competition in AMD's 16nm Vega Large-iGPU, and Zen1 Large-CPU.
However... There hasn't been any upgrades for the "tiny" portfolio, being stuck to the offerings of Cortex A35 CPU and G31 GPU ever since. There has been only a slight refresh to the "small" portfolio, upgrading to the Cortex A55 CPU, and the G52 and G57 iGPUs. To the point that they're a joke, and easily surpassable by the competitors. ARM really needs a revolutionary new design here, it needs to be super-efficient. Perhaps something that can scale between both tiny and small categories: with performance ranging from the A55 (or more) at the "tiny" power-level, to the A73 (or more) at the "small" power-level. Basically catching up to Apple, if unable to surpass them.
Whereas the "medium" portfolio has seen very frequent upgrades, in the CPU-side to the Cortex A75, A76, A77, and A78. In the GPU-side we've seen G72, G76, G77, G78 which have been mostly competitive, surpassing some custom implementations (Samsung/MediaTek) and losing to others (Apple/Qualcomm). Not much needs to change here to be honest. We've also seen the emergence of a new "large" category of ARM processors. Firstly popularised by custom implementations from Apple (A10 and onwards), then Samsung (Mongoose M3, and onwards). Now it's supported officially by ARM in the form of the Cortex A77+ and the Cortex A78X / X1. This has been mostly underwhelming and uncompetitive, with Apple being the only one implementing good designs. There hasn't been any new "large" category for iGPUs from ARM or competitors, with the only Large-iGPU exception actually being inside the Apple Silicon M1. ARM (without counting Apple) needs to do better here, and it looks like ARM might already be focussing here in the future with ARMv9. Again contrast this to the x86 markets offering 7nm Large-CPUs of Zen2 and Zen3, with RDNA-1 and RDNA-2 Large-GPUs.