Intel’s 11th Gen Core Tiger Lake SoC Detailed: SuperFin, Willow Cove and Xe-LP
by Dr. Ian Cutress on August 13, 2020 9:01 AM EST- Posted in
- CPUs
- Intel
- SoCs
- Tiger Lake
- 10+
- Xe-LP
- Willow Cove
- Intel Arch Day 2020
- SuperFin
- 10SF
What is in a Willow Cove Core?
At Intel’s Architecture Day 2018, the company showcased its new CPU core roadmap covering the next several generations of both the high performance cores and the high efficiency cores. Intel updated the slide for the new event.
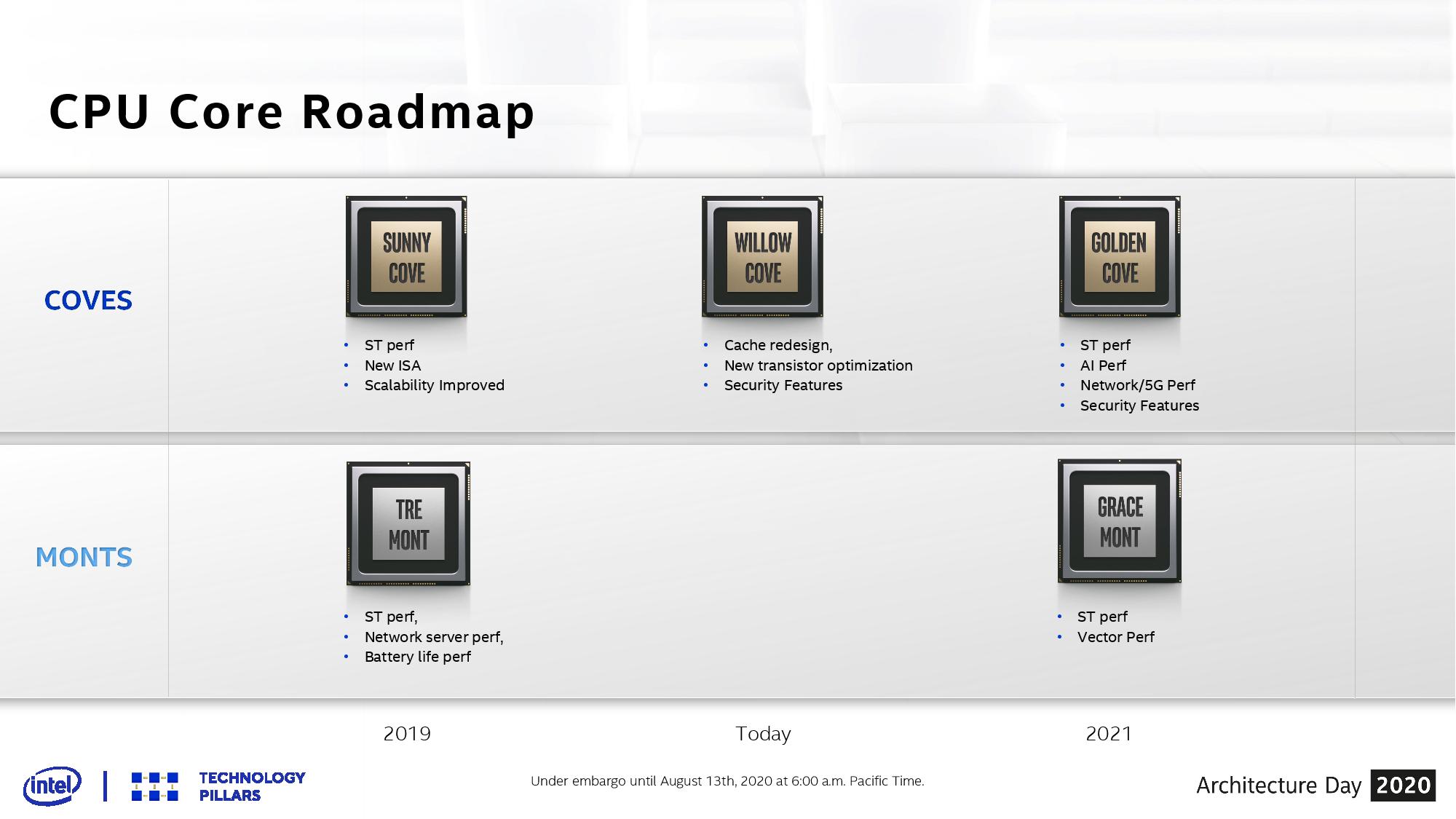
Not so much new has been added, however it is worth covering.
On the top we have the Cove cores, which represent Intel’s high performance designs. It starts with Sunny Cove as the 2019 core, which we can find inside Intel’s Ice Lake and Lakefield processors today. Sunny Cove was set to provide an increase in single threaded performance (we saw 15-20% clock-for-clock), a new set of instructions (VNNI for deep learning), and scalability improvements.
In the middle for the Cove section is Willow Cove, which forms the fundamental compute core for Tiger Lake. On this slide it shows that Willow Cove has a cache redesign (see below), a new transistor optimization (see previous page), and implements new security features.
The 2021 high performance core will be Golden Cove, which Intel states will offer another jump in single threaded performance, more AI performance, and offer performance related to networking and 5G.
Then there’s also some Monts, which are the efficiency-focused Atom cores. We did an analysis of Tremont’s microarchitecture, which you can read here. Gracemont in 2021 will be the Atom core built for Intel’s next generation Hybrid CPU architectures.
Willow Cove: +10-20% Performance Over Sunny Cove
The story of Willow Cove is going to be a bit confusing for a lot of people. It certainly was to me when it was first explained. But I’m going to rip the band-aid off quickly for you, just to get it over and done with.
The microarchitecture of a Willow Cove core is almost identical to that of a Sunny Cove core.
It is almost a copy-paste, but with three key differences that enable a 10-20% performance uplift over Sunny Cove. As it stands, there is no point drawing a diagram to explain the front-end and the back-end of Willow Cove. I suggest you read our deep dive into Sunny Cove, because it’s going to be the same in pretty much all areas. Same branch predictors and decode, same re-order buffers and TLBs, same execution ports, same reservation stations, same load/store capabilities.
Moving the core from Sunny Cove to Willow Cove affords only three differences that need to be highlighted. There is an additional change within the memory subsystem that will be addressed here also.
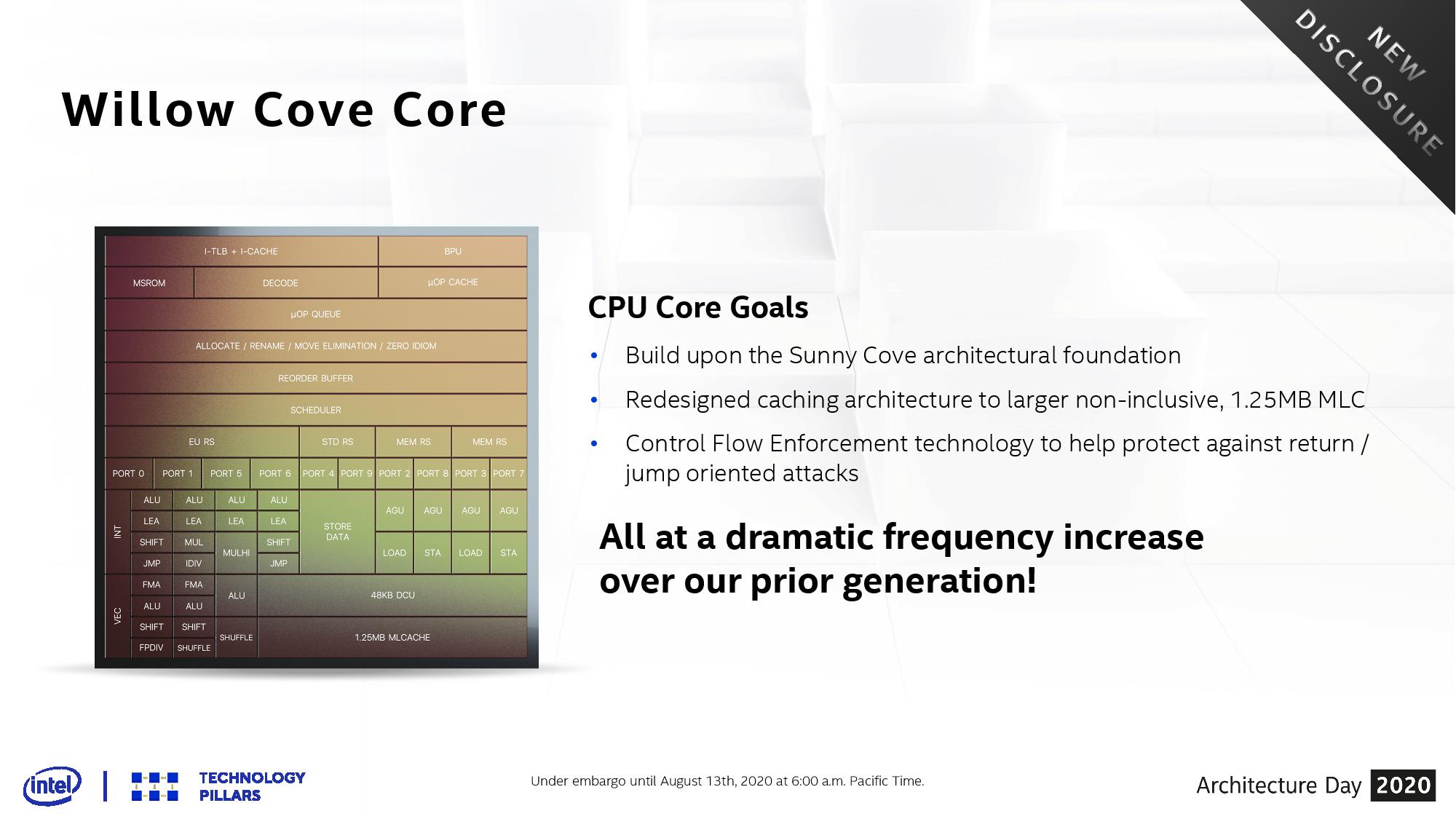
SuperFin Frequency
First, where most of the performance uplift comes from, is the process node. Moving to 10SF and the new SuperFin transistor has enabled Willow Cove to scale better with respect to voltage and frequency, allowing for better metrics across the board. This means better performance at the same voltage, or the same performance at a lower voltage, compared to Sunny Cove. Where the +10-20% performance comes from is at the high-end. Where Sunny Cove was limited to a peak frequency around 4.0 GHz, Willow Cove appears to promise something more akin to 5.0 GHz.

This is Intel’s slide showing this, however at present the company isn’t giving any hard numbers to act as reference points here. We could be talking anything from 10 mV to 100mV or more savings at active frequencies, or not. The only thing that looks eminently readable is that peak frequency. At the same peak voltage as Sunny Cove we see more of a +500 MHz gain for Willow Cove, but it requires more voltage to get to that other peak nearer 5.0 GHz, which obviously would mean higher power consumption.
Bearing in mind that the PL2 values (peak turbo power consumption) for Ice Lake were essentially 50 W when all cores were loaded with AVX-512, this means we could be looking closer to 65 watts for Tiger Lake. Intel at one point did mention that this version of Tiger Lake was supposed to scale from 10 W to 65 W, but despite repeated questioning the company failed to elaborate on what product the ’65 W’ metric would come into play.
More L2 and L3 Cache
The second update to Willow Cove is the cache structure. Intel has boosted the size of both the L2 and L3 cache within the core, however as always with cache sizes, there are trade-offs worth noting.
The private L2 cache gets the biggest update. What used to be an inclusive 512 KiB 8-way L2 cache on Sunny Cove is now a non-inclusive 1.25 MiB 20-way L2 cache. This represents a +150% increase in size, however at the expense of inclusivity. Traditionally increasing the cache size by double will decrease the miss rate by √2, so the 2.5x increase should reduce L2 cache misses by ~58%. The flip side of this is that larger caches often have longer access latencies, so we would expect the new L2 to be slightly slower. Intel declined to give us the new value.
For the L2, there is also an extra small performance gain as non-inclusive caches do not require back-invalidation. However, moving to a non-inclusive cache has a knock-on effect to die area and power. In Intel’s previous architectures, the L2 cache was inclusive of the L1 cache, which meant that every cache line found inside the L1 had an identical copy in the L2. With a non-inclusive cache, extra hardware has to be built into the core in order to satisfy cache coherence rules. It is worth noting that as early as 2010, Intel has been presenting at conferences that it can build inclusive caches that run at the speed of non-inclusive caches; perhaps this does not hold true any longer as cache size is increasing.
As for the L3 cache on a quad-core Willow Cove system, Intel has moved from an 8 MiB non-inclusive shared L3 cache to a 12 MiB shared L3 cache. This is a +50% increase in capacity, however Intel has reduced the associativity, from a 16-way 8 MiB cache to a 12-way 12 MiB cache. The effect of the two on performance is likely to be balanced.
| Cache Comparison | |||||
| AnandTech | Coffee Lake 4C |
Ice Lake 4C |
Tiger Lake 4C |
AMD Zen2 4C |
|
| L1-I | 32 KiB 8-way |
32 KiB 8-way |
32 KiB 8-way |
32 KiB 8-way |
|
| L1-D | 32 KiB 8-way 4-cycle |
48 KiB 12-way 5-cycle |
48 KiB 12-way 5-cycle |
32 KiB 8-way 4-cycle |
|
| L2 | 256 KiB 4-way 12-cycle Inclusive |
512 KiB 8-way 13-cycle Inclusive |
1.25 MiB 20-way ? Non-Inclusive |
512 KiB 8-way 12-cycle Inclusive |
|
| L3 | 8 MiB 16-way 42-cycle Inclusive |
8 MiB 16-way 36-cycle Inclusive |
12 MiB 12-way ? Non-Inclusive |
16 MiB 16-way 34-cycle Non-Inclusive |
|
Overall IPC gains in the core due to this increase are expected to be low single digits. A lot of these features are ultimately an exercise in tuning – increasing one thing to get better throughput might cause extra latency and such. An interesting question will be how these cache changes have had an effect when it comes to die area (is the core bigger?) or power (can the core go into lower power states?). The new SuperFin transistor may also allow Intel to create denser caches, and this is taking advantage of that.
Security and Control-Flow Enforcement Technology
Another aspect of recent news is Intel’s security, and given the life cycle of modern leading edge processors, trying to predict security needs of a future product is often difficult. With every generation and silicon spin, Intel has been plugging security holes as well as enabling more elements to enhance security both for targeted attacks and at a holistic level.
Willow Cove will now enable Control-Flow Enforcement Technology (CET) to protect against return/jump oriented attacks that can potentially divert the instruction stream to undesired code. CET is supported in Willow Cove through enabling Shadow Stacks for return address protection through page tracking. Indirect Branch Tracking is added to defend against misdirected jump/call targets, but requires software to be built with new instructions.
The Memory Subsystem: More Bandwidth, LPDDR5 Support
While not strictly speaking part of the Willow Cove core, with respect to the Tiger Lake SoC, the new memory subsystem will also have an effect on performance. Much like Ice Lake, Tiger Lake will support both up to 64 GB DDR4-3200 or 32 GBLPDDR4X-4266, enabling 51.2 GB/s or 62.8 GB/s of bandwidth respectively, however Tiger Lake also supports 32 GB of LPDDR5-5400 memory for an impressive memory bandwidth increase to 86.4 GB/s.
LPDDR5 is the latest new technology for mobile memory subsystems, and we are told that Tiger Lake will support this out of the box, however it will be up to Intel’s OEM partners to use it in their Tiger Lake systems. At present, we are told that the cost of LPDDR5 is too high for consumer products, so we’re likely to see DDR4/LP4 systems to begin with. The cost of LP5 will come down as manufacturing ramps up and demand increases, however those systems might be later in the Tiger Lake life cycle.
It is worth noting that the Tiger Lake SoC has doubled up to support a dual-ring bi-directional interconnect which allows for 2x32 B/cycle in either direction. This helps the memory controllers to feed the cores as well as the graphics, so we should see some uplift in performance on memory-limited scenarios. One question to ask Intel is why have they gone for a dual ring design, rather than simply making a single ring double-wide – the answer is likely related to sleep state power, if one ring can be put to sleep as required. The trade off to that would be related to control and die area, however.
Total Memory Encryption
Tiger Lake’s Memory system also supports full Total Memory Encryption. TME has been a popular feature of new silicon designs of late, and enables mobile device users to have the data held in the memory on a system physically secure against hardware attacks. In other systems we’ve been told that a feature like TME, when implemented correctly, only gives a 1-2% performance hit in the most usual worst case – Intel has not provided equivalent numbers as of yet. Given the type of feature this is, we suspect TME might be more of a vPro-enabled product feature, however we will have to get clarity on that.








71 Comments
View All Comments
Quantumz0d - Thursday, August 13, 2020 - link
"The others not mentioned will be split between 7nm and external fabs. More on that info in a separate article"So that means they are going for external fab really. Damn. What a shame. I wonder if that's the CPU or this GPU. Anything is a shame on Intel and that beancounter Bob.
IanCutress - Thursday, August 13, 2020 - link
That's referring to the other tiles of Ponte Vecchio. There are 4. We covered 2.Eliadbu - Thursday, August 13, 2020 - link
Shame is when you don't acknowledge your problems and how they might limit you. Going with external fabs allows the company to be competitive where it needs the most. But they sure need a long term strategy and and make critical decisions like which processes they would utilize earlier.Kangal - Thursday, August 13, 2020 - link
It's only GPU.And it's only the Xe-HP (ergo Discreet GPU) variant.
It seems to imply that is only on the 10SFE "enhanced" variant. Basically using TSMC 7nm process for the higher memory and connector chips, named as "Rambo Cache" and "Xe Link". And that's targeting the server market and high-end desktops (ie think Nvidia Titan).
Seems like Intel realise how embarrassing it is to ask for their competitors wafers for their main product, so instead they're taking a half-measure and using it for the GPU only. That way they get to save face and say "well, AMD and Nvidia do it too". Also it seems they couldn't get any good prices, which is why only some chips are made on the 7nm, and rest are made in-house on 10nm. Overall, this is Intel playing hard to catch up to TSMC's 7nm and AMD's Zen2 and AMD's Vega. That's why the whole thing is difficult to understand, as it is purposely obfuscated. Yet these will only ship in (late) 2021, whereas the competition is posied to actually leap ahead in 2020 to +7nm TSMC, Zen3, RDNA2. And when Intel arrives, they might even be facing off against 5nm and a Zen3+ refresh. Just to put things into perspective.
tipoo - Thursday, August 13, 2020 - link
This reads quite promising. Great writeup."A few angstroms thick" it's hard to even think about the scale of this stuff, that's 0.1 nanometres or 100 picometres. How far from atomic bonding limits?
DrJackMiller - Thursday, August 13, 2020 - link
It's pretty damn close, but that depends on the bond :-). For a perhaps more human comparison, that of O-O in Oxygen is 1.208 Å; and in C=O bonds (e.g. in CO2) it's around 1.16 Å.vortmax2 - Friday, August 14, 2020 - link
Would love to see an article here of the next 10-20 years of processors as we enter deeper into the atomic scale. What the next big breakthrough?jospoortvliet - Saturday, August 15, 2020 - link
Less promising is that they went for a four cores design again. With AMD pushing the desktop to 8 with the first Zen you would think they would realize amd would pull the same when going mobile and prepare for it... so is this arrogance thinking their cores are so much better or they control the market? Lack of strategic insight? Or inability to work out things for the yield and cost math?Spunjji - Monday, August 17, 2020 - link
If these cores are as good as they're claiming they are, there will be a legitimate dilemma choosing between 4 Very Fast cores and 8 Really Quite Fast cores.I'd wager that yields are 80% to blame and power is the rest - they have an 8-core Tiger in the works, but it's a 35/45W part and there's nothing firm about a release date yet.
none12345 - Tuesday, August 18, 2020 - link
Depends on the atoms, but for reference how about silicon."Silicon has the diamond cubic crystal structure with a lattice parameter of 0.543 nm. The nearest neighbor distance is 0.235 nm."
Diatomic hydrogen is the smallest molecule with a bond length of 0.74 angstrom.
Bond length is typically 1-2 angstrom.
"Intel states that this is an industry first/leading design, enabled through careful deposition of new Hi-K materials in thin layers, smaller than 0.1nm, to form a superlattice between two or more material types."
Unless im missing something, the above statement does not make any sense to me. thin layers of atoms less then the average bond length between atoms is nonsensical.