SiFive Announces First RISC-V OoO CPU Core: The U8-Series Processor IP
by Andrei Frumusanu on October 30, 2019 10:00 AM ESTThe U8-Series Microarchitecture
We’ve had the pleasure of being briefed on the key aspects of the U8 microarchitecture, and we’ll be able to have a more in-depth look (albeit high-level) at how the new CPU design functions.
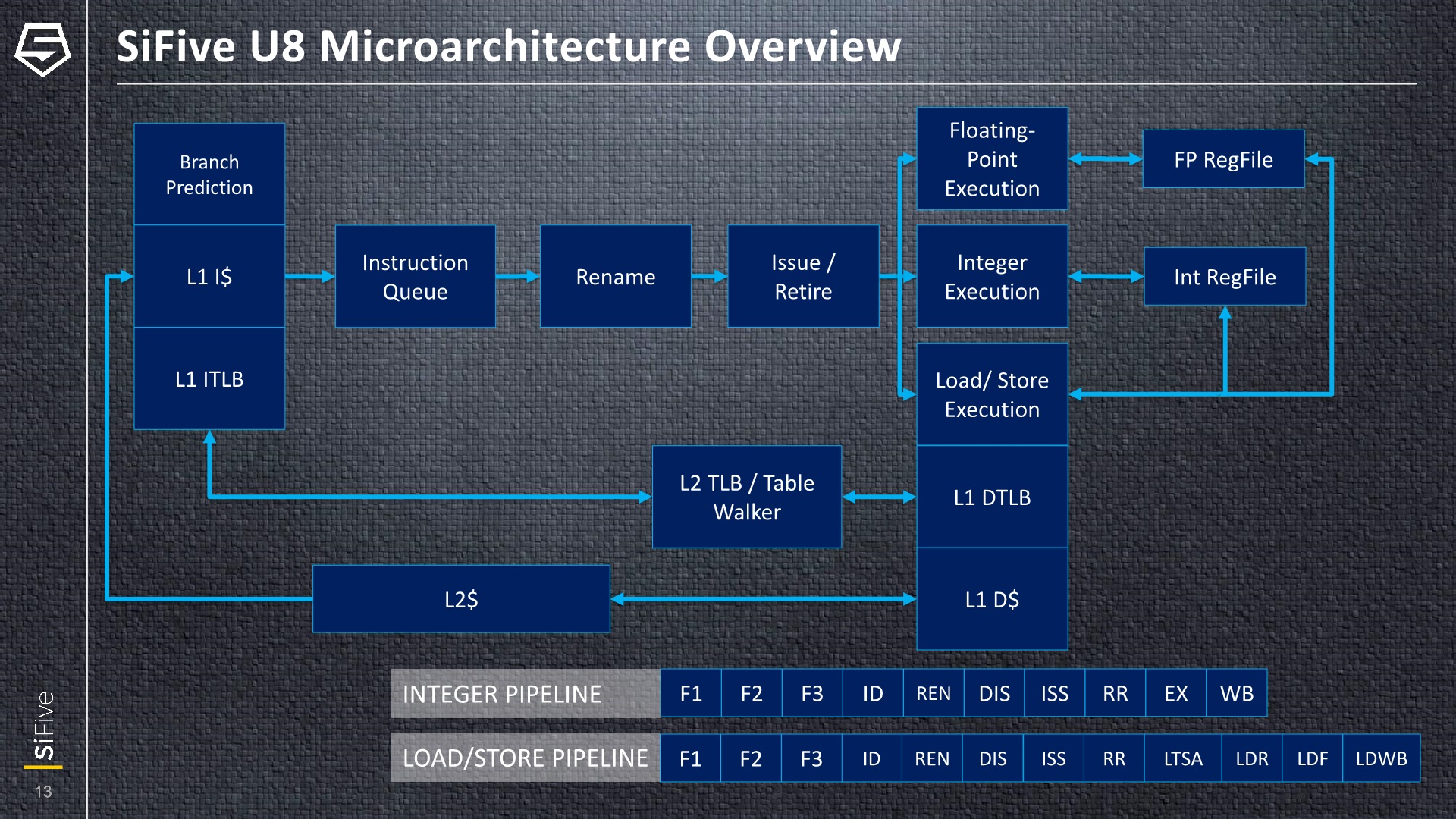
At the highest level, the U8 is a 3-wide issue out-of-order CPU with a pipeline depth of 12 stages, feeding 3 execution units. It’s a pretty traditional OoO-design and the noteworthy design choice here is the core’s use of physical register files instead of an architectural one, such as seen in initial Arm designs such as the A72.
One thing to note as we’re covering the microarchitecture is that SiFive didn’t disclose the exact sizes of some of the structures, which is somewhat natural given the core’s purported scalable configuration design where one can change many aspects of the IP, and we’re only covering the generic U8-Series microarchitecture as individual implementations (Such as an U84) will have different configurations.
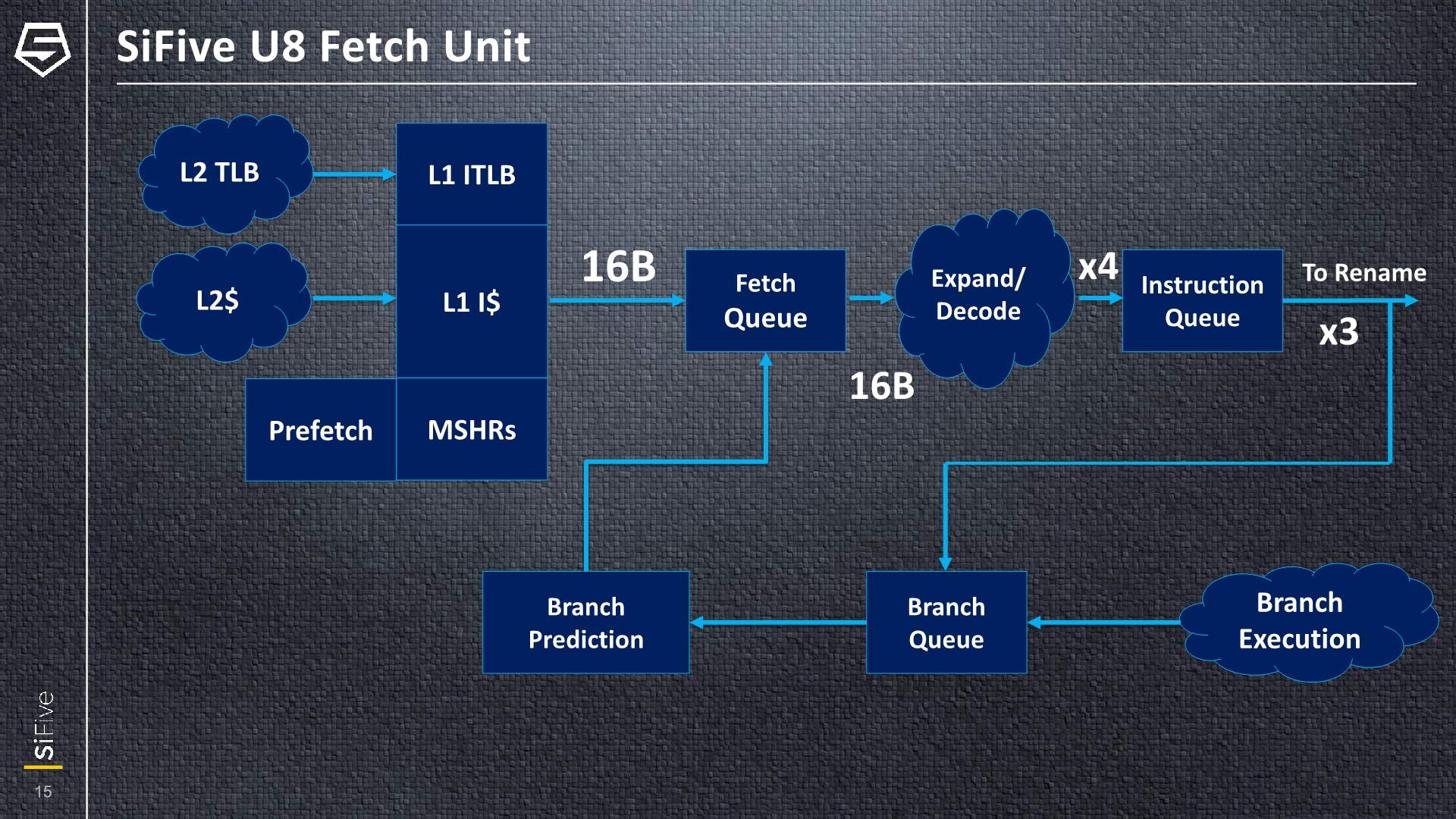
The fetch unit of the core is able to request instructions out of the L1I at 16 bytes per cycle and put it into the fetch queue of the front-end. The RISC-V ISA has a variable instruction encoding size, so it’s not possible to map this to an exact number on instructions as one can on the Arm ISA, but if we naively assume a 32-bit average, it would correspond to 4 instructions per cycle. Of course, this isn’t surprising as the decoder on the U8 is 4-wide, feeding expanded instructions into the instruction queue.
The interesting thing here about the core is that the instruction queue is only able to issue 3 instructions out to the rename stage. Having the fetch width being higher than your issuing rate helps in the case of branch mispredictions and bubbles and allows the front-end to catch up with the execution backend, something we’ve also seen in other cores; however, we never quite saw an implementation in which the decoder was wider than the issue rate (Actually, only Intel's recent Tremont microarchitecture would also fit this characteristic). Beyond it being a deliberate design decision for the balance of the microarchitecture, maybe it’s also a forward-looking implementation on the part of the decoder whilst we may see wider issue configurations in future U8 designs.
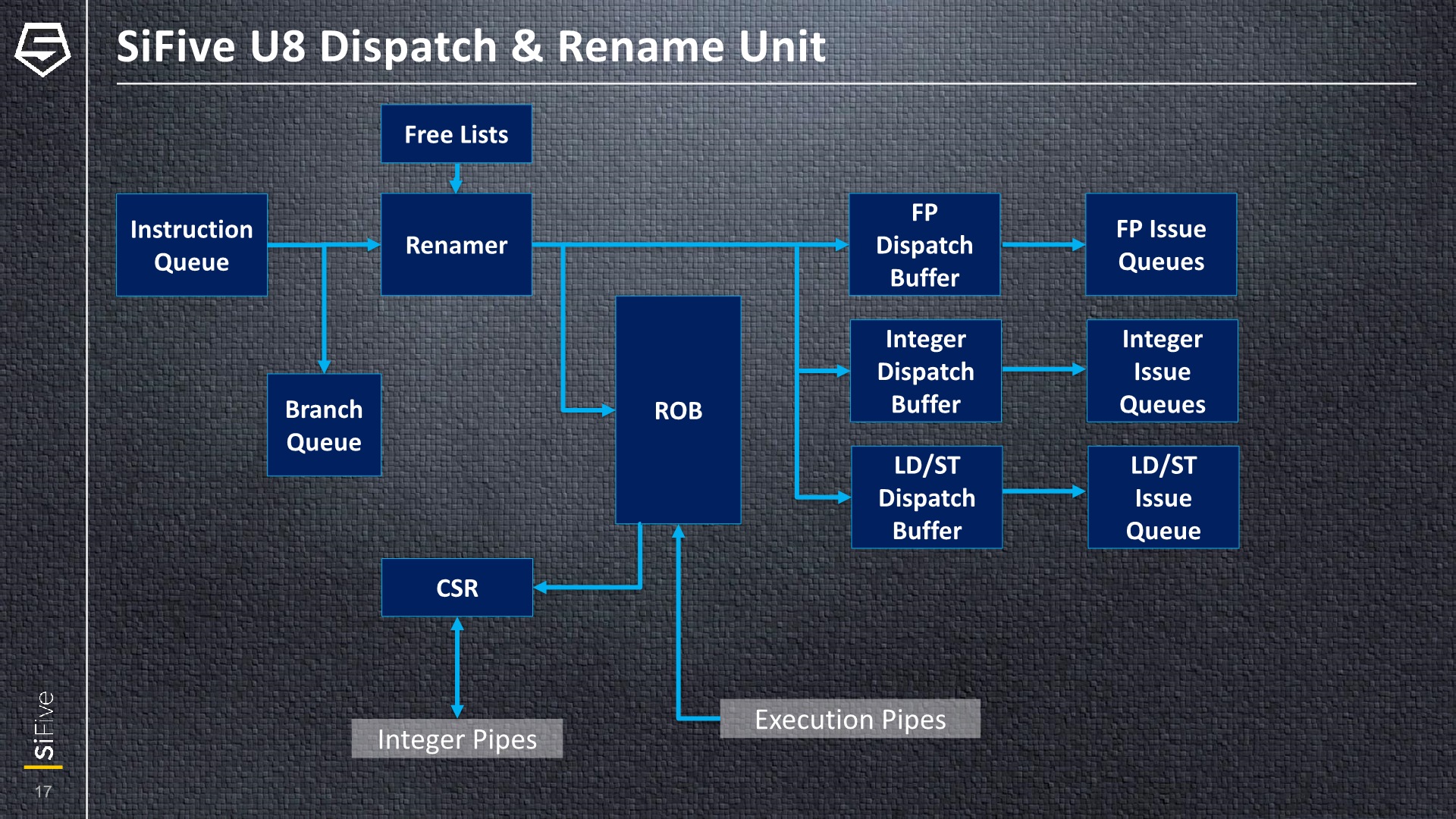
Moving on to the mid-core, we see a traditional design into the rename stage, a re-order buffer and three dispatch engines feeding into the execution pipelines. The diagram here is a bit misleading in terms of the arrows going into the issue queues – it doesn’t mean that it’s only one instruction per issue queue, the core can still dispatch up to 3 instructions into the integer issue queues for example.
It would have been interesting to hear about the exact structure sizes on this part of the core but SiFive didn’t cover these details during the presentation.
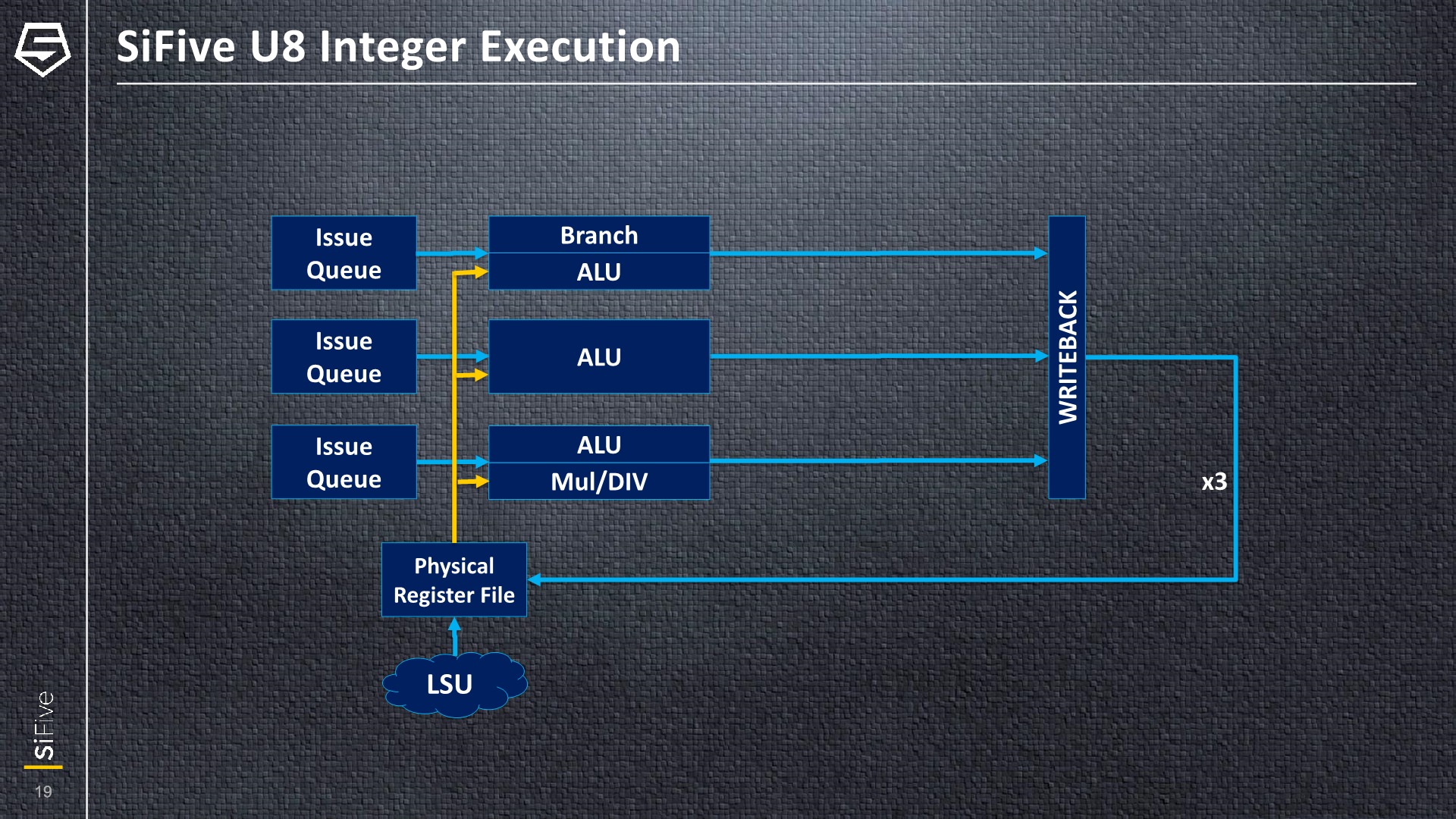
On the integer execution block, we see that it’s actually composed of three execution pipelines. Each has its own issue queue, feeding into three ALU pipelines with different capabilities. One pipeline serves just as a regular ALU, a second one shares the port with the branch unit, while the third pipeline is a more complex one capable of integer multiplication and division.
Unfortunately, SiFive didn’t go into any detail of the floating-point pipelines or the L/S units. On the FP side, things should be relatively simple in terms of the execution capabilities, at least on the U84 core. Currently, RISC-V does not have any SIMD/Vector instructions as that ISA extension has not been finalized yet. SiFive explains that this might happen at the end of the year, and the U87 is poised to adopt the new vector capabilities next year.








68 Comments
View All Comments
The_Assimilator - Wednesday, October 30, 2019 - link
Half a decade and they don't even have a production part with SIMD or vector capabilities? Arm has nothing to worry about.bji - Wednesday, October 30, 2019 - link
That seems particularly short-sighted. Your criteria for ARM needing to worry apparently is production silicon with vector capabilities and according to this article that will be available next year.PeachNCream - Wednesday, October 30, 2019 - link
It is a valid point right now to argue that RISC-V isn't a threat while production parts are not available to purchase. Ad present, even if I wanted to acquire a competing product, I would be unable to due to the lack of ability to make an acquisition. The situation may change next year, but we won't know until we see what both ARM and RISC-V look like at that point. The dynamics may change on both sides of that coin after time has passed.bji - Wednesday, October 30, 2019 - link
Strawman. He didn't say they are not a threat. He said ARM has nothing to worry about. The distinction is slim I admit and also just semantic, but the sentiment I read from The_Assimilator was more about how this company has not produced a product that ARM would need to worry about in half a decade and by saying that ARM has nothing to worry about, implies that they will not be producing any product that would compete with ARM for a long time. But the article states that the will be releasing the product that The_Assimilator says compete with ARM next year, and any company would naturally worry about a competing product that close on the horizon.In terms of being threatened, ARM cannot be threatened by something that cannot exist. But they may want to worry, i.e. take seriously the notion that a competitor may be threatening them soon.
bji - Wednesday, October 30, 2019 - link
"by something that cannot exist" should have been "by something that does not exist". Post editing, Ananadtech-style!PeachNCream - Wednesday, October 30, 2019 - link
Okay, that's cool.There's never anything wrong with competitive designs. Either way, we are likely to enjoy improvements that result from various interests attempting to get ahead of one another so it's good all the same no matter what the outcome.
Sivar - Wednesday, October 30, 2019 - link
ARM was able to take over because of its inherent advantage over x86: Efficiency. As R&D advanced, ARM cores like the Apple A* line and Qualcomm Snapdragon have slowly worked towards Intel-level performance.MIPS has no large inherent benefit over ARM, but it has some of the same disadvantages vs. x86 such as larger executable code size. MIPS is an elegant architecture and lacks some of the strange baggage the architectures have (read about THUMB some time) but the story of semiconductors does have elegance as a main protagonist. See Intel's history of success as an example.
rrinker - Wednesday, October 30, 2019 - link
Indeed, back in the early 8 bit days, the RCA CDP1802 was absolutely the most elegant architecture, but most people probably day "the what?". Outside of some niche applications, where the completely static nature allowed it to clock down to 0 and draw picoamps, and it being all CMOS so low power even when running, and being available in rad hardened form, it was all but invisible in the pre-IBM PC 8 bit days. Elegance doesn't equal design wins.Sivar - Wednesday, October 30, 2019 - link
Interesting, I hadn't heard of this. I wonder if the same principles could be applied to idle processors today. Now if only Android would let the CPU go idle for more than a few ms.rrinker - Wednesday, October 30, 2019 - link
The registers and such aren't static though, I don't think, on most modern processors, so they have to run at some minimum clock rate to be refreshed. Unused elements can be turned off today, and with turbo you have varying frequency, but the old 1802 could run from 0-4MHz (or 6, or 8, or as high as 12MHz in the last variants. It was almost RISC-like, as well, just 91 instructions, and that very well organized (for Hex, Intel just loved Octal so the 8080 instruction set it highly aligned for octal - it makes no sense in hex). Most 1802 contemporaries had a very small register count - the 1802 has 16x16 general purpose registers plus accumulator and a coupe others. Of the 16, any one could be program counter, which could be switched on the fly (that's how they did subroutine calls with no CALL instruction), and any could be the index pointer for memory directed operations, also switchable on the fly, which means the 1802 has the best operand ever - SEX, for SEt indeX. It was my first computer, and later when I had to add an assembly routing to an Apple 2 BASIC program to get proper performance, I was hugely frustrated by the lack of registers int he 6502. SO many people worship the 6502, I frankly hated the thing. 1802 remains my favorite 8-bitter, followed by the Z80. Best part is, that computer I built from a kit more than 40 years ago still works perfectly.