Hot Chips 31 Live Blogs: Intel Spring Crest NNP-T on 16nm TSMC
by Dr. Ian Cutress on August 19, 2019 8:15 PM EST
08:23PM EDT - Intel is showing us some of the design features of its new ML training product, Spring Crest.
08:23PM EDT - NNP-T = Training

08:24PM EDT - Spring Crest is what Intel purchased when it acquired Nervana in 2016. THis is the big chip that came with the acquisition
08:24PM EDT - Trend in Neural Networks means compute requirements doubles every 3.5x months
08:25PM EDT - Need to fill the die with as much compute that can be fed
08:25PM EDT - DL is as much as a communication problem as it is a compute problem
08:25PM EDT - Need a scale-out model for larger models
08:26PM EDT - Want to train a model as fast as possible within a power budget. Aim for high utilization, and a scalable solution

08:26PM EDT - Balance between compute, comms, and memory
08:26PM EDT - Best is to be compute bound on all but the smallest problems
08:27PM EDT - Keep data local and reuse it as much as possible
08:27PM EDT - Consistent programming model
08:27PM EDT - Flexibility for future workloads
08:27PM EDT - Spring Crest uses 2.5D

08:27PM EDT - PCIe Gen 4 x16 with host CPU
08:28PM EDT - 4x 8GB HBM2
08:28PM EDT - 24 Tensor Processors (TPCs), Up to 119 TOPs
08:28PM EDT - 8x8 lanes SerDes for chip-to-chip communications
08:28PM EDT - Built on 16FF+ TSMC with CoWoS

08:29PM EDT - 680mm2 with 1200mm2 passive interposer, 27 billion transistors
08:29PM EDT - Up to 1.1 GHz Core frequ
08:29PM EDT - HBM2-2400
08:29PM EDT - Supports PCIe and OAM (Open Compute)
08:29PM EDT - TensorFlow and PaddlePaddle first frameworks supported, more to come. Uses NGraph
08:30PM EDT - Intel provide the low level compiler performance optimizations

08:30PM EDT - Tensor based ISA
08:30PM EDT - Limited instruction set

08:30PM EDT - Extensible with custom microcontroller custom instructions
08:30PM EDT - Same distributed model on-chip and off-chip
08:30PM EDT - Compute has affinity for local data
08:31PM EDT - DL worklaods are dominated by a limited set of operations
08:31PM EDT - Explicit SW memory management and message passing
08:31PM EDT - 150-250W power
08:32PM EDT - Here's a TPC
08:32PM EDT - On-chip router, controller, two arrays, memory
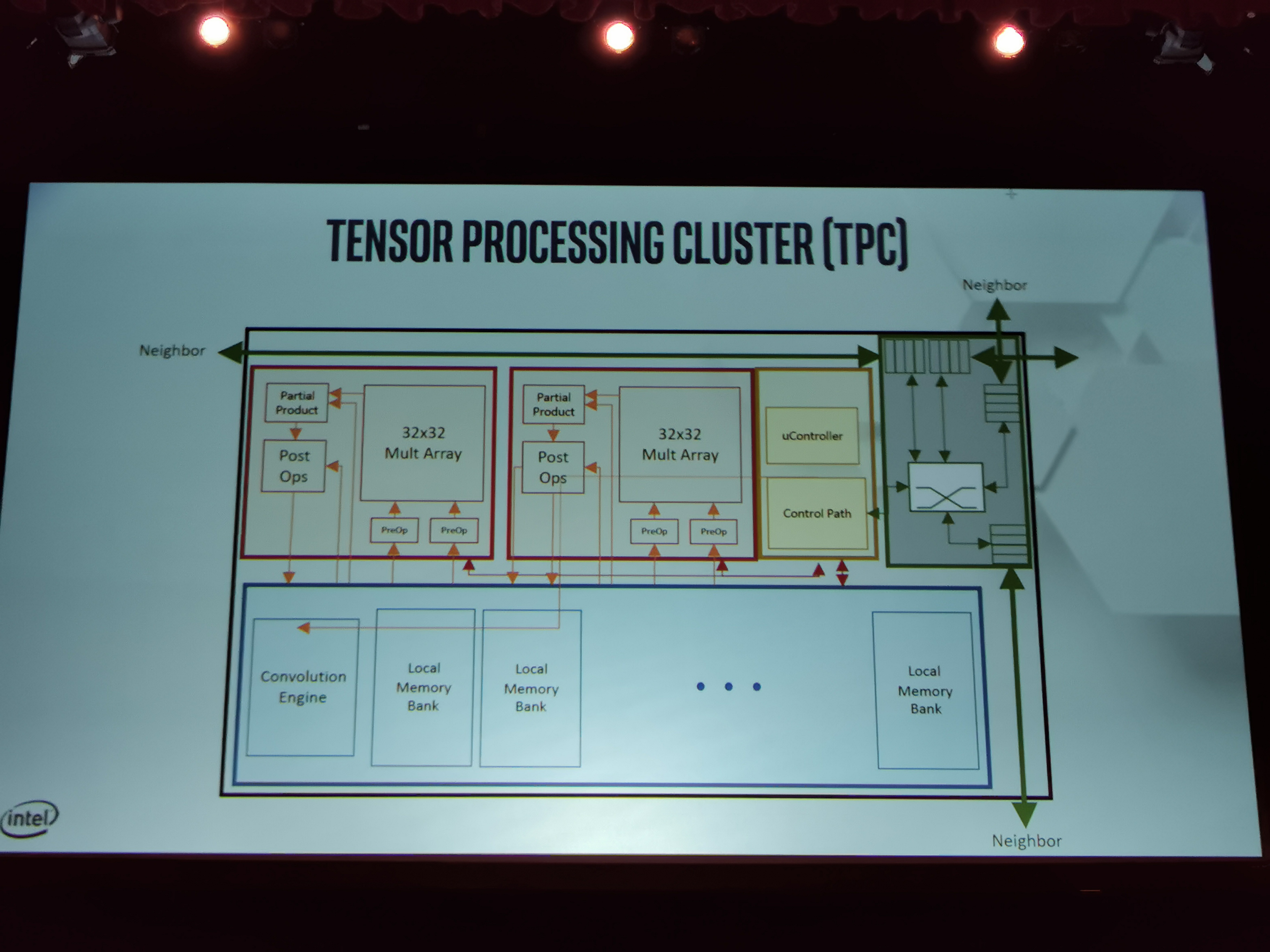
08:33PM EDT - Each 32x32 array has pre-op and post-op support
08:33PM EDT - dedicated convolution engine for non-MAC compute
08:33PM EDT - BFloat16 support with FP32 accumulation

08:34PM EDT - BF16 32x32 MAC Core
08:34PM EDT - 2x Multiply Cores per TPC to amortize SoC resources

08:35PM EDT - Compound vector pipeline with DL specific optimizations on non-GEMM ops
08:35PM EDT - 1.22 TBps raw HBM2 bandwidth
08:36PM EDT - 2.5MB / TPC local scratchpad memory
08:36PM EDT - Native Tensor Transpose without any overhead

08:36PM EDT - 1.4 TBps local read/write bw per TPC
08:36PM EDT - Cna do TPC-to-TPC data movement without HBM involvement
08:37PM EDT - 2D Meshes, multiple meshes for different data types
08:37PM EDT - prioritized for throughput over latency
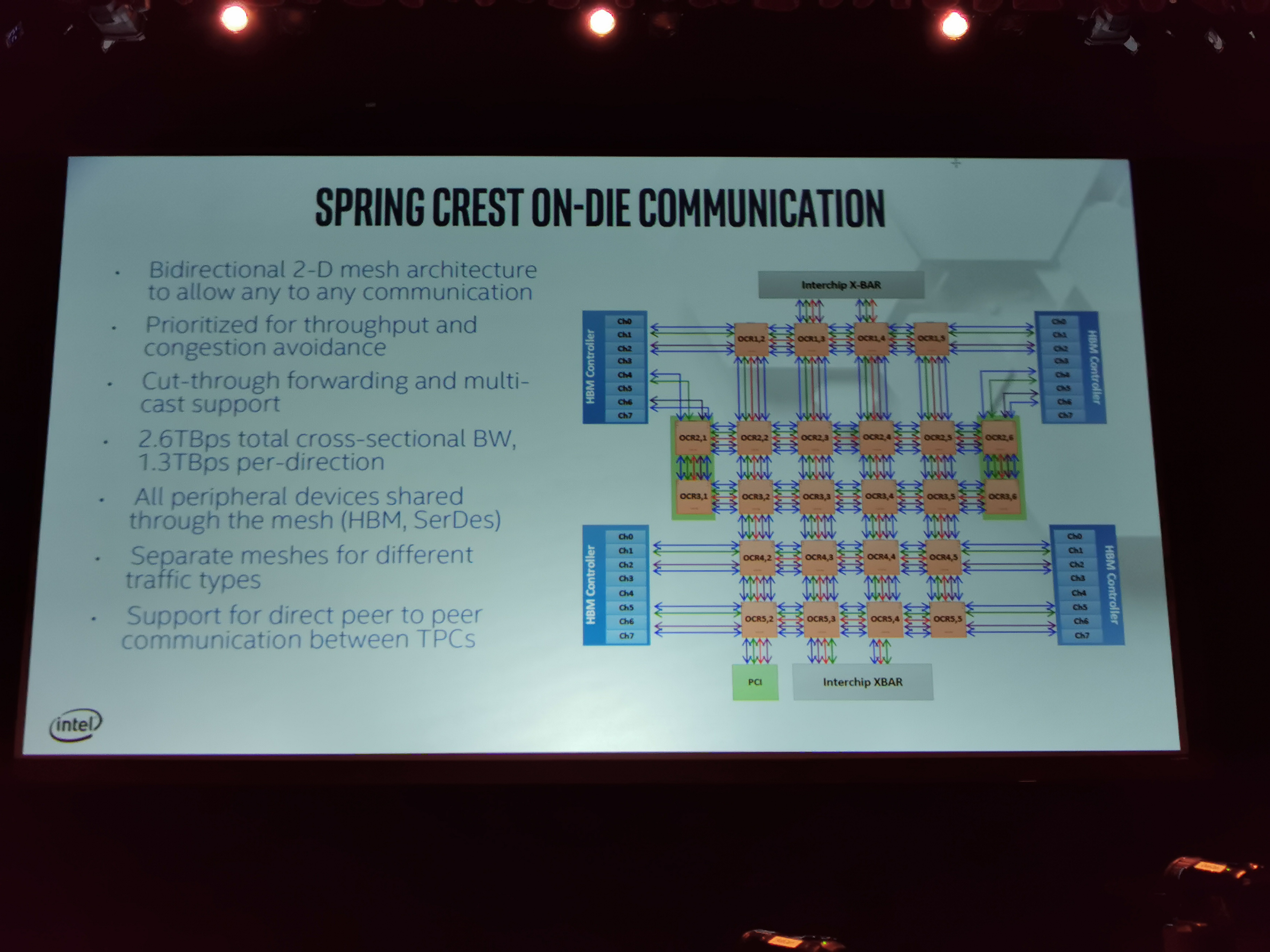
08:37PM EDT - 1.3 TBps bandwidth in each direction
08:38PM EDT - Designed for a fully connected topology

08:38PM EDT - Looks like one large system to simplify the software model
08:38PM EDT - Up to 1024 nodes supported gluelessly
08:38PM EDT - 3.58 TBps total bidirectional SerDes BW per chip
08:39PM EDT - Fully programable router with multi-cast support and virtual channel support
08:39PM EDT - Aiming for high utilization across many GEMM sizes

08:40PM EDT - Most architectures do well on large square GEMMs. Not all hardware can do different matrix sizes well
08:40PM EDT - Looking at GEMM utilization that is difficult to solve
08:42PM EDT - Ring topology bandwidth benchmarked across 32-chips
08:42PM EDT - Equivalent bandwidth between cards and between racks

08:43PM EDT - Performance measured using 22 TPCs at 900 MHz core clock and 2 GHz HBM. Host is Xeon Gold 6130T @ 2.1 GHz
08:43PM EDT - Whisper connectivity
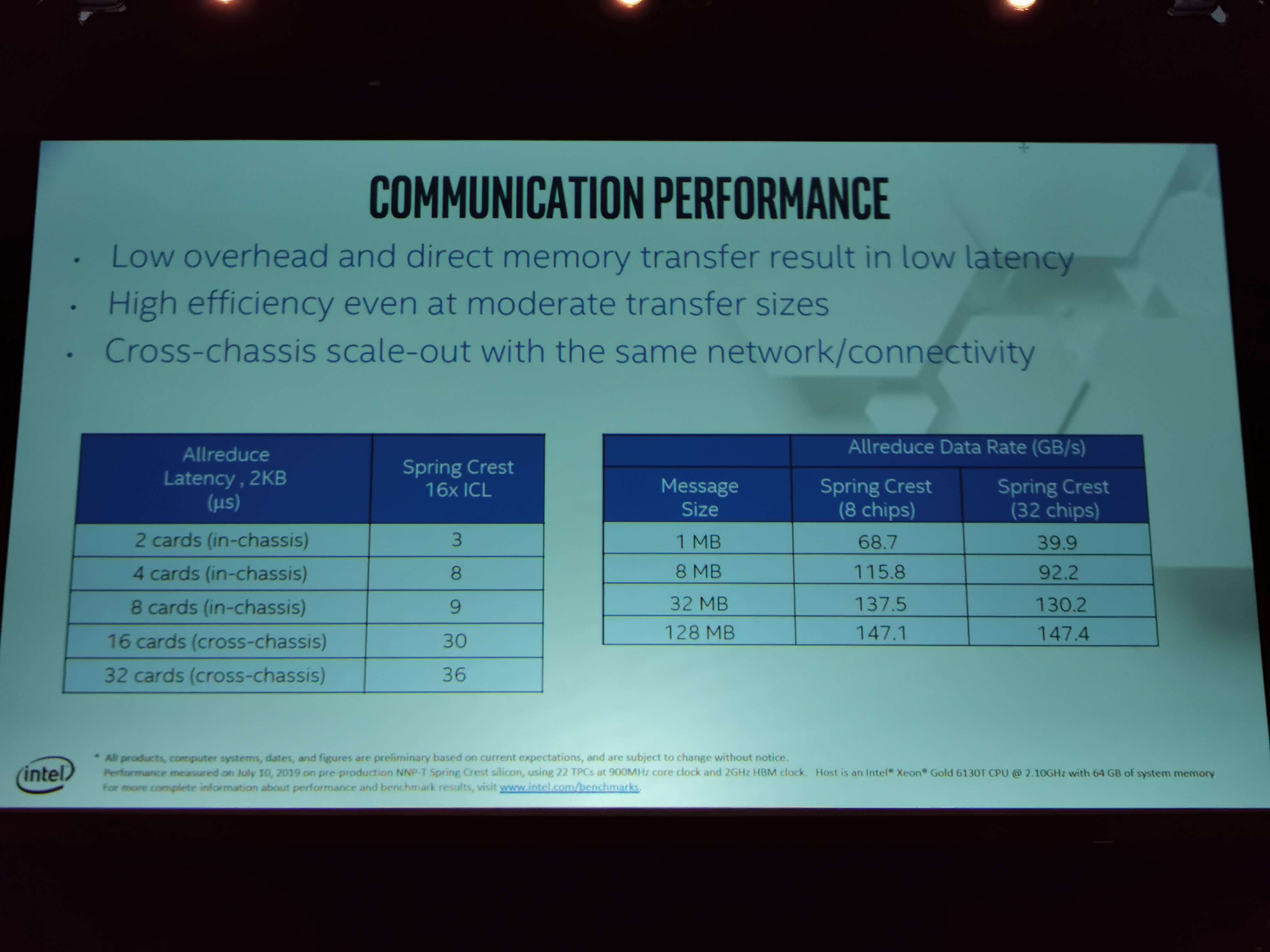
08:45PM EDT - Latency card-to-card at 3-9 microseconds, cross chassis at 30-36 microseconds

08:46PM EDT - Coming to customers soon
08:46PM EDT - Q&A
08:47PM EDT - Q: How do you support structured sparsity? A: More benchmarks to come
08:47PM EDT - Q: MLperf? A: Can't comment. More data before the end of the year
08:49PM EDT - That's a wrap. Next up Cerebras








3 Comments
View All Comments
Elstar - Tuesday, August 20, 2019 - link
Whither Knights Crest?Dodozoid - Tuesday, August 20, 2019 - link
Does PCIe 4.0 suppotr means this intel product is best used in an AMD Epyc Rome host system?Elstar - Tuesday, August 20, 2019 - link
This isn't out yet – and by the time it is Intel's CPUs will support PCIe 4.0.