Hot Chips 31 Live Blogs: MLperf Benchmark
by Dr. Ian Cutress on August 19, 2019 6:10 PM EST- Posted in
- Machine Learning
- Hot Chips
- Live Blog
- MLperf

05:58PM EDT - MLperf is an up-and-coming benchmark aimed at machine learning, backed by a number of industry leaders in this area.
06:08PM EDT - Over 50 partners

06:08PM EDT - ML hardware is projected to be $60B in 2025
06:09PM EDT - Benchmarking helps drive hardware development

06:09PM EDT - Benchmark design overview
06:10PM EDT - ML is different to traditional SPEC
06:10PM EDT - Training and Inference have different issues

06:11PM EDT - Training develops to a target quality

06:11PM EDT - Two divisions:
06:11PM EDT - Closed division is a fixed model, open division where the model is unspecified
06:11PM EDT - Create a set of benchmarks around key ML areas

06:12PM EDT - Commerce, Research, Vision, Speech, Language
06:12PM EDT - Have to choose the model in the closed division

06:13PM EDT - MLperf requires real world datasets
06:14PM EDT - Chose the metrics. Throughput or time to train?
06:14PM EDT - MLperf goes on time-to-train, as the least bad choice

06:15PM EDT - Architecture, framework, implementation. Overall model must be mathematically equivalent
06:15PM EDT - Also hyperparameter tuning

06:16PM EDT - Finding good hyperparameters is expensive and not the point of the benchmark. It would make it a search contest
06:16PM EDT - Solution is hyperparameter borrowing between submissions
06:16PM EDT - Another challenge is variance

06:17PM EDT - Because convergence changes, solution is to run each benchmark multiple times and drop outliers
06:17PM EDT - Aim for 2-5% variance without 1000 runs required
06:17PM EDT - Now inference benchmarks
06:17PM EDT - Same as closed division and open division

06:18PM EDT - Inference is used differently: single stream, multiple stream, server stream, offline
06:18PM EDT - Inference has prioritized around vision, reflecting real world use cases
06:18PM EDT - Four different metrics
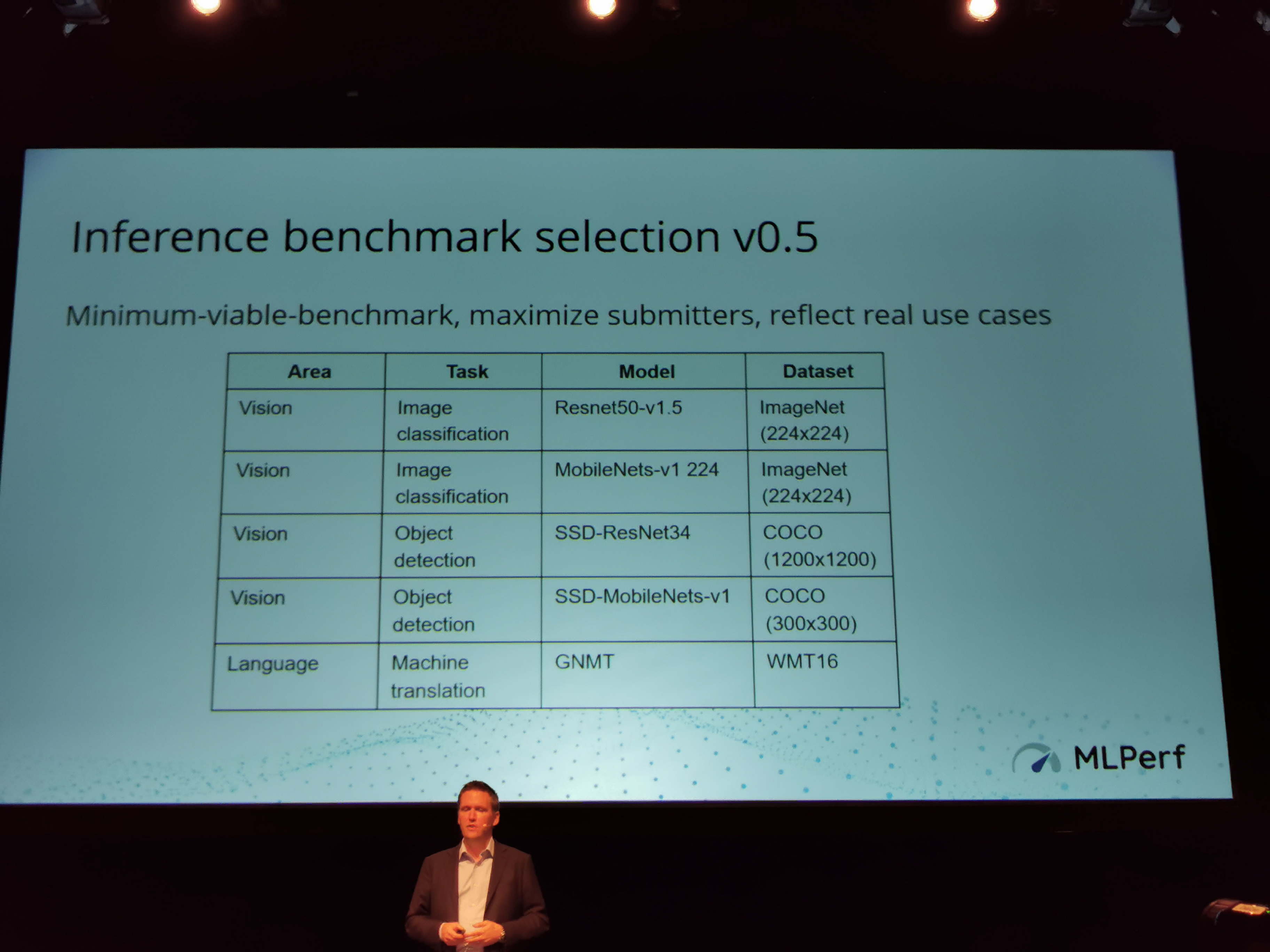
06:19PM EDT - Latency, QPS, Minimum Latency, Throughput

06:19PM EDT - Pre-trained weights for closed division, have to use standard C++ load generator
06:20PM EDT - Inference specific: quantization and retraining

06:20PM EDT - In closed division, quantization must be principled

06:22PM EDT - Results have the issue of scale. Number of chips, power, time etc

06:23PM EDT - Impact of benchmarking on MLperf
06:23PM EDT - Is this benchmark moving the industry forward


06:27PM EDT - Developing the framework to move forward. Aiming for agile benchmarking
06:27PM EDT - Rules have changed and parameters are being learned
06:27PM EDT - Rule challenges to optimize for something the industry needs and works to drive the industry forward
06:28PM EDT - Making reference implementations faster and more reliable

06:28PM EDT - Launching a non-profit called MLcommons, the home of MLperf
06:28PM EDT - Mission to accelerate ML innovation
06:29PM EDT - Benchmarks, large public datasets, best practices, outreach
06:29PM EDT - Helping push a young industry forward

06:30PM EDT - In the process of getting founding members of MLcommons
06:30PM EDT - Q&A time
06:32PM EDT - Q: How do you make the benchmark useful if ML iterates every few months? A: First goal was to create a benchmark match reality. We like to lower the barrier to entry over time. Try to make the reference implementaitons on higher perf. Also sub-benchmarks using traces.
06:33PM EDT - Q: Is MLperf a non-standard at this point? A: We're aiming to build a consensus between hardware that won't do MLperf and accept everything apporach. We believe in actual benchmarking. We're still feeling our way.
06:33PM EDT - That's a wrap.








2 Comments
View All Comments
DanNeely - Tuesday, August 20, 2019 - link
So is this available and easy enough to run to add to your next round of benchmark updates?beginning - Wednesday, August 21, 2019 - link
Much needed! Glad to finally see it released.