HiSilicon Kirin 970 - Android SoC Power & Performance Overview
by Andrei Frumusanu on January 22, 2018 9:15 AM ESTAn Introduction to Neural Network Processing
AI is currently the big buzzword when talking about consumer electronics. While marketing departments all over are trying to embrace the term, when we’re talking about the current use of AI in computing terms we’re specifically talking about machine learning. More precisely when talking about the latest generations of silicon IPs, we’re talking about the implementation of specialized hardware block which are optimized to run convolutional neural networks (CNNs).
While explaining how convolutional neural networks work in detail is far beyond this piece, they have been a research topic since the 1980’s. The idea is to try to simulate the behaviour of the human brain’s neurons. The keyword here again is simulation; no the various neural network IP’s hardware implementations do not mimic the human brain structure. While the field of neural networks in academia has been around for a long time, it’s only been in the last decade with the introduction software implementations that are able to run on GPUs that things have literally accelerated to become a lot more interesting. Via breakthroughs over the last half-decade, we’ve seen researchers iterate and develop CNN models that improve in terms of accuracy and efficiency.
Looking under the hood, it turns out that CNNs map pretty well to highly threaded execution models. The work itself has minimal branching or other "complex" behavior that requires a general purpose processor (CPU), and instead can typically be broken up into discrete, semi-independent threads. Furthermore the required computational accuracy is not all that high – running fully developed networks can be done via low-precision integers in some cases – again simplifying the scope of the problem. As a result, CNN research & development hit its stride earlier this decade when GPUs began shipping with the necessary compute features and the overall performance to resolve complex CNN execution in a reasonable-by-human-standards timeframe.
Of course, while GPUs have been the most adapted to running them, GPUs are not the only kind of highly parallel processor out there. As the field is evolving and companies want to commercialize their use in actual use-cases, we saw the need for much higher performance requirements as well as consideration for power efficiency. At this point we started seeing the move towards more specialized processing units whose architecture is built with machine learning in mind. Google was the first to announce such hardware with the announcement of the TPU back in 2016. More specialized hardware loses some flexibility, but in turn it gains power and area (die space) efficiency by only including the hardware and features necessary for the task.

There are two key aspect to actually running NN workloads: first you have to have a trained model which contains the actual information that describes the data that the model is later meant to be run on. The training of models is rather processor intensive – not only is it a lot of work to begin with, but it has to be done with greater levels of precision than the execution of those models, which is to say that efficient neural network training requires more powerful and complex hardware than executing neural networks. Consequently, the idea is that the bulk of models will be trained by high performance hardware, such as server-class GPUs and specialized hardware such a Google’s TPUs on servers in the cloud.
The second aspect of NN is the execution the models; taking the completed models, feeding them new data, and generating results based on what the model perceives. The execution of a neural network model with input data to get an output result is called inferencing. And not unlike the conceptual differences between training and inferencing, the compute requirements for inferencing are quite a bit different as well. The name of the game is still highly parallel compute, but it can be done with lower precision computations and the overall amount of performance required for timely execution is lower as well. Which means that inference can be done on cheaper hardware in many more locations and scenarios.
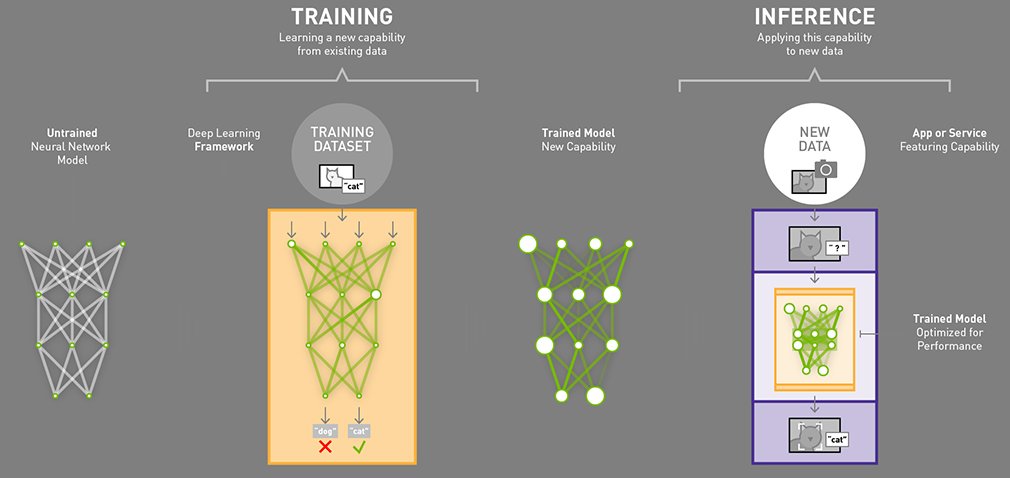
Graphic source: Nvidia Blog
This in turn has caused the industry to move towards inferencing on edge devices (consumer devices) because it’s a much more performant and power efficient. If you have your trained model on your device locally you can just use the processing power of the device to run the inference and avoid having to upload data to the cloud and have a server do it. This alleviates issues such as latency, bandwidth, and power consumption but also eliminates privacy concerns as the input data never leaves your device.
With the goal of running neural network inferencing locally on an edge device, we have the choice of running the implementation on various different processing blocks on devices such as a smartphone. CPU, GPU and even DSPs are all able to run inferencing tasks, however there are vast efficiency differences between them. General purpose CPUs are the least suited for the task as they are not designed with massive parallelised execution in mind. GPUs and DSPs are much better choices but even then there’s much room for improvement. It is here were we see a new class of processing accelerator like the NPU on the Kirin 970.
As these new IP blocks are still new the industry hasn’t had time to agree on a common nomenclature. HiSilicon/Huawei have coined the term NPU/neural processing unit while Apple publicly uses NE/neural engine. Other IP providers such as Cadence/Tensilica just outright call their implementation a neural network DSP (Vision C5), Imagination Technologies (Series 2NX) uses the term NNA/neural network accelerator and CEVA’s NeuPro settled on the marketing friendly “AI processor”. In the sense of simplicity I’ll just continue to refer to them as neural network IPs.
In the case of the Kirin 970 the NPU is provided by a new Chinese IP provider called Cambricon. The Kirin 970 NPU however isn’t a straight off-the-shelf offering but rather a co-development between Cambricon and HiSilicon optimized to HiSilicon’s requirements. Huawei quotes 2 TeraOPS FP16 performance on the IP, however this metric is misleading as the performance figure quotes sparse equivalent peak data, meaning the 8-bit quantized throughput. At this point in time we should largely shy away from theoretical performance figures of the neural network IPs as they don’t necessarily correlate to actual performance and there’s less understood architectural characteristics of the IPs that can play larger roles for the resulting end-performance.
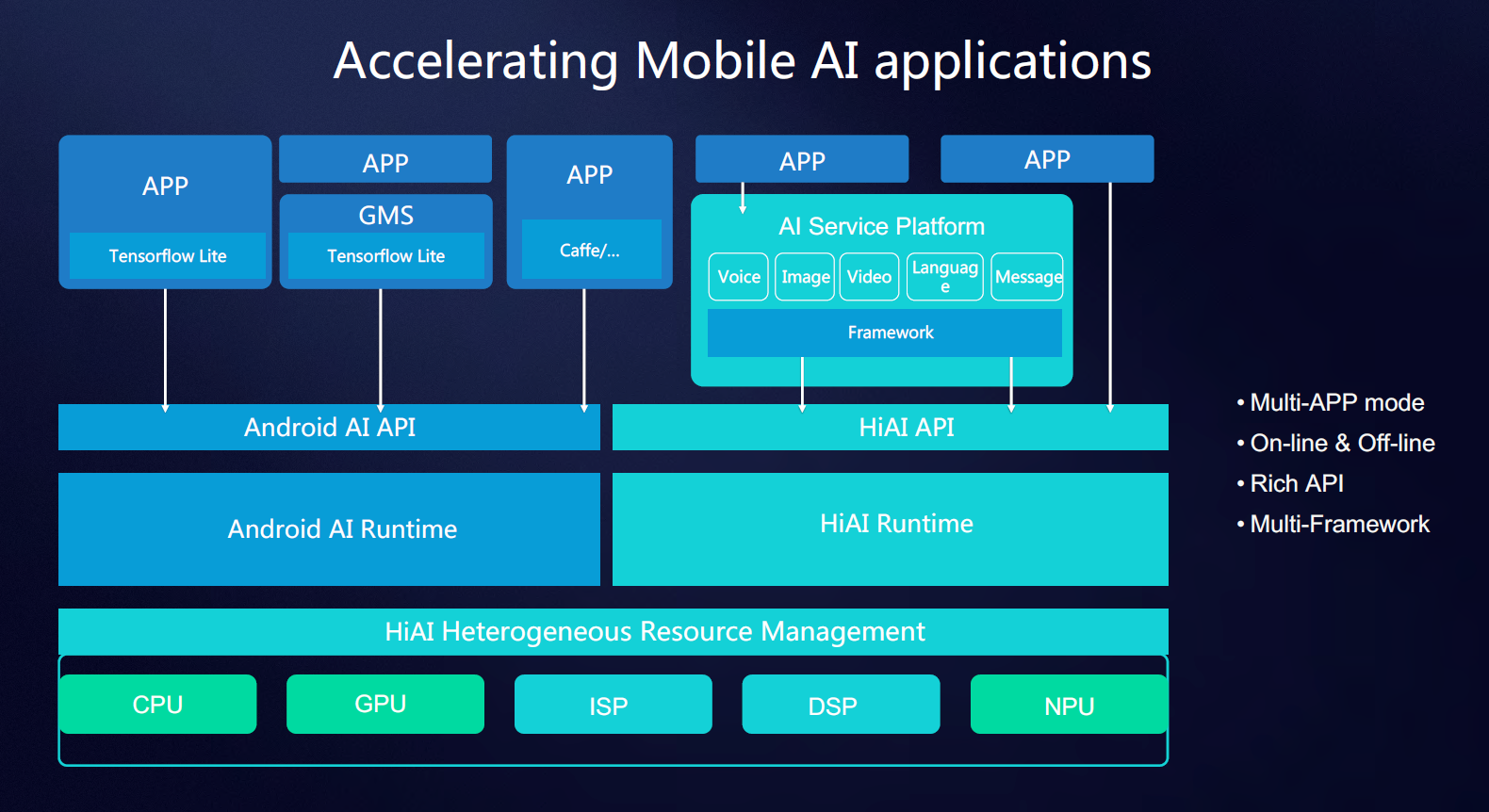
The first hurdle to using a neural network on a hardware block other than the CPU is to make use of the proper APIs to access that block. The SoC and IP vendors all currently ship proprietary APIs and SDKs to enable application development for using hardware acceleration for neural networks. In the case of HiSilicon they offer the HiAI API which can manage the workloads between CPU, GPU and NPU. The API is currently not publicly available as it’s still under development, but developers which reach out to HiSilicon can get early access before the public release later in the year. Vendors such as Qualcomm make available the SNPE (Snapdragon Neural Processing Engine) SDK which does the equivalent task of enabling app developers to tap into resources of the GPU and DSP for neural network processing workloads. Other IP vendors of course have their own SDKs for their respective IPs.
However vendor-specific APIs may end up being a temporary quirk of the present time; the goal in the future is to have a common universal API alongside the respective vendor’s IPs. Google has already been working on this and the NN API introduced in Android 8.1 is already actively shipping on Pixel 2 devices. One note that I’ve been made aware of is that currently the NN API only supports a subset of features that is available to IP like the NPU, so for developers to take full advantage of the hardware and extract maximum performance Huawei still sees application developers targeting the various proprietary APIs while using the NN API as a fall-back method.








116 Comments
View All Comments
zorxd - Monday, January 22, 2018 - link
Samsung isn't vertically integrated? They also have their own SoC and even fabs (which Huawei and Apple don't)Myrandex - Monday, January 22, 2018 - link
Agreed, but they don't even always use their own components like Huawei and Apple do, I think I've yet to own a Samsung Smartphone that uses a Samsung SoC. I think they will eventually get there though although I can't say I have any idea why they aren't doing it today.jospoortvliet - Saturday, January 27, 2018 - link
Samsung always uses their own SOCs unless they are legally forced not to, like in the US...levizx - Saturday, January 27, 2018 - link
They are DEFINITELY NOT legally forced to use Qualcomm chips in China, especially for the worlds biggest carrier China Mobile. As for the US, if Huawei is not forced to use Qualcomm, I can't imagine why Samsung would unless they signed a deal with Qualcomm - then again that's just by choice.Andrei Frumusanu - Monday, January 22, 2018 - link
Samsung's mobile division (which makes the phones) still makes key use of Snapdragon SoCs for certain markets. Whatever the reason for this and we can argue a lot about it, fact is that the end product more often than not ends up being as the lowest common denominator in terms of features and performance between the two SoC's capabilities. In that sense, Samsung is not vertically integrated and does not control the full stack in the same way Apple and Huawei do.Someguyperson - Monday, January 22, 2018 - link
No, Samsung simply isn't so vain as to use it's own solutions when they are inferior. Samsung skipped the Snapdragon 810 because their chip was much better. Samsung used the 835 instead of their chip last year because the 835 performed nearly exactly the same as the Samsung chip, but was smaller, so they could get more chips out of an early 10 nm process. Huawei chooses their chips so they don't look stupid by making an inferior chip that costs more compared to the competition.Samus - Monday, January 22, 2018 - link
Someguyperson, that isn't the case at all. Samsung simply doesn't use Exynos in various markets for legal reasons. Qualcomm, for example, wouldn't license Exynos for mobile phones as early as the Galaxy S III, which is why a (surprise) Qualcomm SoC was used instead. Samsung licenses Qualcomm's modem IP, much like virtually every SoC designer, for use in their Exynos. The only other option has historically been Intel, who until recently, made inferior LTE modems.I think it's pretty obvious to anybody that if Samsung could, they would, sell their SoC's in all their devices. They might even sell them to competitors, but again, Qualcomm won't let them do that.
lilmoe - Monday, January 22, 2018 - link
Since their Shannon modem integration in the Exynos platform, I struggled to understand why...My best guess would be a bulk deal they made with Qualcomm in order for them to build Snapdragons on both their 14nm and 10nm. Samsung offered a fab deal, Qualcomm agreed to build using Samsung fabs and provide a generous discount in Snapdragon resale for Galaxies, but in the condition to buy a big minimum amount of SoCs. That minimum quantity was more than what was needed for the US market. Samsung did the math, and figured that it was more profitable to keep their fabs ramped up, and save money on LTE volume licensing. So Samsung made a bigger order and included Chinese variants in the bulk.
I believe this is all a bean counter decision, not technical or legal.
KarlKastor - Thursday, January 25, 2018 - link
That's easy to answer. Samus is right, it's a legal problem. The reason is named CDMA2000.Qualcomm owns all IP concerning CDMA2000.
Look at the regions where a Galaxy S is shipped with a Snapdragon and look a the Countries using CDMA2000. That's North America, Chna and Japan.
Samsung has two choices: Using a Snapdragon SoC with integrated QC Modem or plant a dedicated QC Modem alongside their own SoC.
The latter is a bad choice concerning space and i think it's more expensive to buy an extra chip instead of just using a Snapdragon.
I bet all this will end when Verizon quits CDMA2000 in late 2019 and Samsung will use their Exynos SoCs only. CDMA200 is useless since LTE and is just maintained for compatibility reasons.
In all regions not using this crappy network, Samsung uses Exynos SoCs in every phone from low cost to high end.
So of course Samsung IS vertically integrated. Telling something else is pretty ridicoulous.
They have theor own fabs, produce and develope their own SoC, modem, DRAM and NAND Flash and have their own CPU and modem IP. They only lack their own GPU IP.
So who is more vertically integrated?
KarlKastor - Thursday, January 25, 2018 - link
I forgot their own displays and cameras. Especially the first is very important. The fact, that they make their own displays enabled more options in design.Think of their Edge-Displays, you may like them or not, but with them the whole design differed much from their competitors.