The Intel Core i9-7980XE and Core i9-7960X CPU Review Part 1: Workstation
by Ian Cutress on September 25, 2017 3:01 AM ESTNew Features in Skylake-X: Cache, Mesh, and AVX-512
We have covered this in previous Skylake-X reviews, but it is worth a refresher about what is new in these Skylake-X processors over previous generations. The interesting thing to note is that the core design in these processors is different to the consumer-grade Skylake (known as Skylake-S) processors. This is a distinct change in policy from previous generations, where we saw parity on the base microarchitecture design. The changes for Skylake-X over Skylake-S are three fold: a change in the L2/L3 cache arrangement, a new routing mechanism for cores to send data, and the inclusion of AVX-512 units.
In our initial Skylake-X review, we tested how the new changes directly effect IPC / performance against Skylake-S in our benchmark suite. Overall they have a positive effect, with one major exception as noted below.
Cache Me If You Can: More Private L2 Cache
Modern Intel x86 processors use a three level cache design, known as L1, L2, and L3. The L1 cache is the one nearest to where the action happens in the processor core, so it is the fastest but also the smallest. When data is not in the L1 cache, a request is made to L2 cache, which is bigger but slightly slower. L3 follows the same route: bigger but slower. An ideal processor would have all of the data it needs always in the L1 cache in order to perform the best, but software is not always that nice: you cannot load that 4MB cat gif into a 1MB L2 cache.
In all of Intel’s Core microarchitecture designs, both the L1 and L2 caches are private to each core, with the L3 shared among all cores. This is achieved by giving each core a ‘slice’ of L3 cache and having appropriate tags, but allowing all the other cores to pull data from it when needed. The L3 level is typically where cores can ‘share’ data without going out to main memory (discussing simply here, rather than going into complex ideas such as snooping). In all previous Core designs, including Skylake-S, these caches were called inclusive caches: in each core, the L2 would contain a copy of L1, and the overriding L3 would contain a copy of every L2. This means that if a cache line in the L2 was invalidated, it would still be present in the L3 if needed later. This improves the ‘hit rate’ (getting data from a lower level cache), but puts demands on cache size: if a 10-core CPU has 10 L2 caches (one per core) at 256 KB each, the L3 cache must at least be 256 KB per core. Cache is not cheap and takes up a lot of die area, so it becomes a balance of performance and cost.
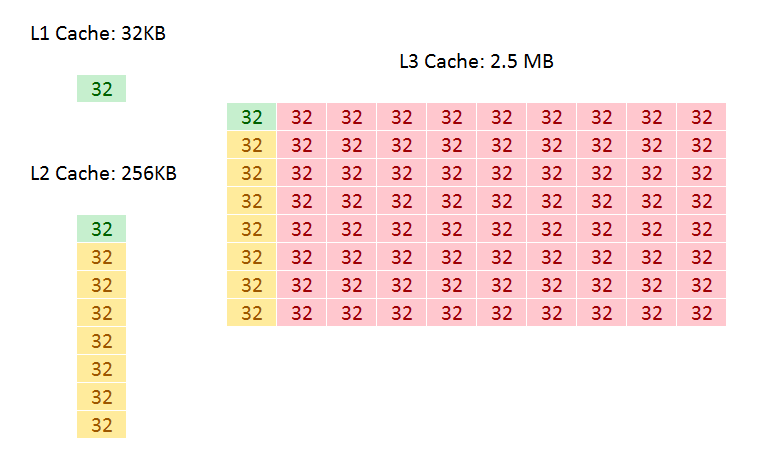
Inclusive Caches in Skylake-S: Green for L1 data, Yellow for L2 data, Red for L3 data
For Skylake-X, Intel does three things: it increases the size of the private L2 cache, which increases the hit rate for loading data, from 256 KB per core to 1 MB per core. To compensate for the increase in die area, Intel reduced the size of the size of the L3 from 2.5 MB per core to 1.375 MB per core, keeping the overall L2+L3 constant. The third element is inclusivity of the L3 cache: with it only being 1.375 MB per core, it no longer made sense for it to also hold 1 MB of the L2 data, and so with Skylake-X the L3 cache is now a non-inclusive cache (basically an exclusive cache) with the inability to obtain pre-fetch data from DRAM.
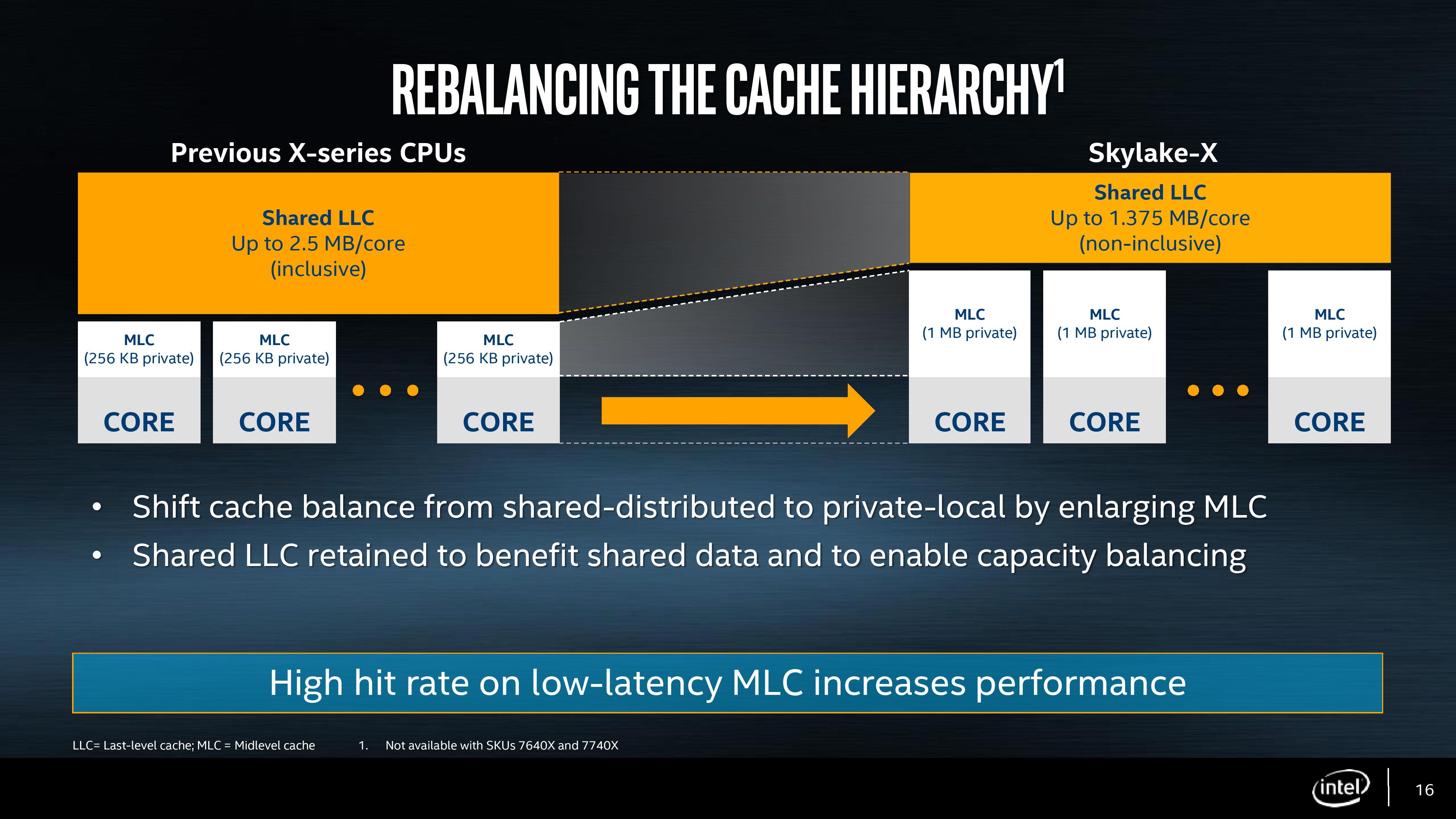
Moving the L3 to a non-inclusive cache with the inability to obtain data direct from DRAM turns it into what is known as a victim cache. When data comes in from DRAM into the L2, is used and then retired/overwritten, a copy is moved into the L3 (the L3 obtains the ‘victim’ cache line). If the data is then needed again in quick succession, there will be a copy in L3 rather than moving all the way out into DRAM. This situation depends highly on the software being used: software that has a large L2 cache requirement (e.g. 2MB) but frequency reuses data can take advantage of this scenario. Unfortunately not a lot of software is like this, and the L3 cache can become almost a dead-weight. Historically we see victim caches perform best with software that has a memory-speed bottleneck, or with integrated graphics. Skylake-X has no integrated graphics.
The upside is the size of the L2 private cache. Having spoken with engineers from different companies, a doubling of the size of the L2 cache often leads to a 1.414x decrease in cache misses (when data is not present and has to move out to the next level of cache). So by increasing the cache from 256 KB to 1 MB, thereby doubling the cache and doubling it again, the cache miss rate should be halved in total, leading to what most engineers would consider a 4-10% general IPC increase. The downside of a larger cache is that it takes longer to process data from it, adding latency. Keeping the latency low is difficult, but Intel claims that it has spent a lot of R&D effort here, with the L2 latency only moving from 11 cycles in Skylake-S to 13 cycles in Skylake-X. This will have a slight knock on that 4-10% IPC increase, but it does provide an overall benefit in almost all scenarios.
Making a Mesh: Replacing Rings with Routers
When reading about high performance processors, one phrase will always crop up: ‘feeding the beast’. In order for a CPU core to run at peak throughput, it has to continually have data to work on – if it does not have data to work on, it will sit idle and the throughput will drop. A lot of the core design is devoted to this problem: multi-level caches can store megabytes of data ready to go, and each generation brings a smarter pre-fetch engine to pull the right data from memory into cache at the right time. We’ve spoken about caches, but when a core needs data from the cache of another core, or needs to send/receive data from main memory, this also becomes a very important element to the design.
Most almost all of Intel’s processors, except for Xeon Phi, the solution to this problem has been bidirectional rings connecting the cores together (known as ring buses). The ring would allow data to travel in both directions, and it would have stations at each core (technically it grouped cores into pairs) as well as the main memory and system agent (IO). For the largest enterprise cores, in order to keep latency low, Intel separated the cores into two sets with some overlap, and a ring in each that had stations which could communicate with each other. As long as the cores and software kept the data it needed close by, latency was fairly low, and successive generations had led to higher frequencies and optimized design. The downside of a ring is scalability: the more cores you put in, the more variable the latency and more inconsistent performance can occur.

A dual ring design with Intel’s Xeon E5 v4 24-core processors
With Skylake-X, Intel felt that the ring strategy was not the right solution, and implemented its Xeon Phi strategy instead.
Rather than each core being a station on a ring, each core becomes a node in a two-dimensional grid or ‘mesh’. The node acts like a router: it is connected to the core above, the core below, and the core either side, and can direct data in each direction or drop it off at the core the node is on, similar to how a router works. In the scientific literature, this is seen as a decoupled crossbar (a central routing block), with the ‘decoupled’ bit being that every core acts like a localized crossbar.
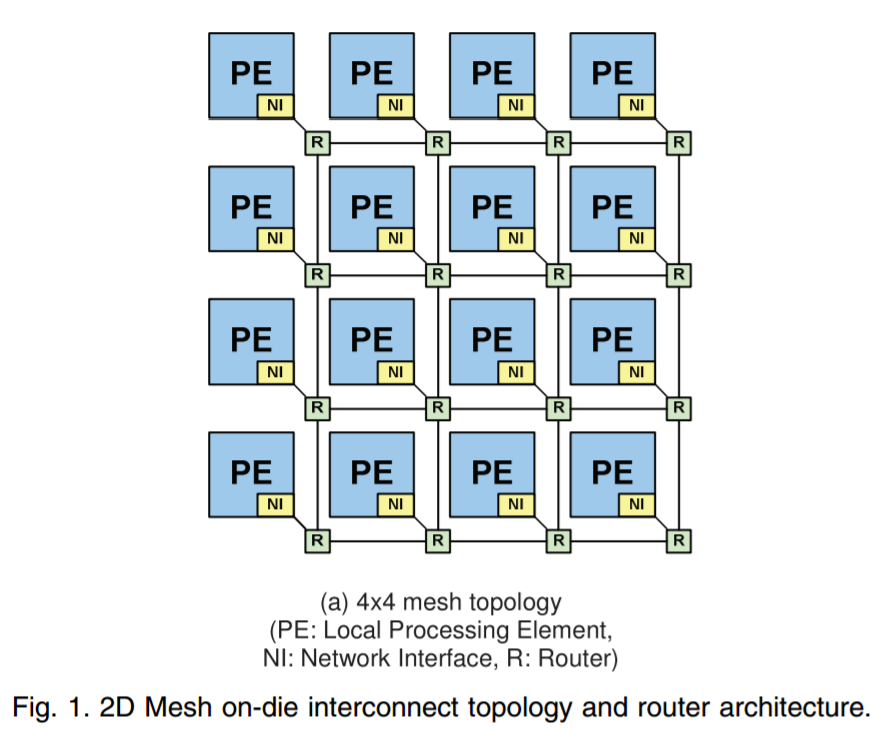
We believe that Intel is using a design known as MoDe-X, which simplifies the router at each stage to a very small routing mechanism, optimized through wiring lengths as these designs can burn power proportional to wire length. By optimizing in this way, Intel wants to reserve the power more for cores and IO. We go into greater depth on how MoDe-X works in our initial Skylake-X review.
So far the reaction to the mesh method has been mixed. While it offers scalability over using rings, it has not had over a decade of optimization, and some users have pointed to the frequency (usually 2.4 GHz) as being a bottleneck in their software over the faster ring design. Intel is likely to continue with the mesh design for the next few generations, so it will be interesting to see what upgrades are made (if disclosed).
I’ve Got 512 Problems but AVX Ain’t One: Accelerating Compute
Both the cache adjustment and the mesh networking are redesigns of features already implemented in the core. AVX-512 by contrast is a distinct addition to the design, requiring a fairly substantial amount of die area (approx. 20% of a Skylake-S core). Much like AVX and AVX2 before it, the point of AVX-512 is bundling sets of data together and performing the same operation on all the data with one instruction, rather than eight or sixteen instructions.

Bundling data together to unify a single instruction is at the heart of many dense compute tasks, and most prosumer and enterprise software with high compute requirements is designed with using instructions like this to accelerate performance. Most professional software today will take advantage of AVX or AVX2 instructions, with Intel expecting the same companies to update their software with AVX512 support soon.
Due to the density of the computation, the localized energy consumption is often very high (higher than in the standard core logic), and draws a lot of power – to compensate the core will often run at a lower frequency when these instructions are used, but there is an overall net gain. The support of AVX-512 is meant to be a highlight of Intel’s enterprise processors, but due to the unified design between enterprise and HEDT, consumers are able to take advantage as well, as long as their software does. For anyone using these new processors for light tasks, or gaming, are unlikely to see any advantage through AVX-512, announcing for a lot of unused silicon on the shiny new processor.
For the new processors launched today, all of them will support dual 512-bit FMA execution through a single 512-bit FMA on port 5, and a two joined 256-bit FMAs on ports 0 and 1. Intel had noted that the six and eight core parts on Skylake-X were manufactured with the port 5 FMA disabled, however several outlets have reported that both FMAs are detected for these parts.
There is a lot to dissect with AVX-512, such as the different instruction support as well as a few new (to Intel) implementations such as mask registers and small-datatype support. We covered this in detail in our initial Skylake-X review.








152 Comments
View All Comments
mmrezaie - Monday, September 25, 2017 - link
unofficially threadripper supports ECC. Do you have the plan to look into it?p.s. I sent an email to Anandtech support about abusive ads directing to some questionable websites. I am in EU and I see these ads for a long time now.
Ryan Smith - Monday, September 25, 2017 - link
"p.s. I sent an email to Anandtech support about abusive ads directing to some questionable websites. I am in EU and I see these ads for a long time now."Er, we don't have a support email address. So I'm not sure who you sent that to.
Anyhow, we're always trying to squash malvertising. It comes in on programmatic ads, which does make the process tricky. But if you can get it to reliably and repeatedly trigger, please contact me. If we can get network logs collected, then we can isolate the source and get said ads pulled.
mmrezaie - Monday, September 25, 2017 - link
I sent it to advertisement link I found in the "contact us" page. Sorry by saying support. That's what we call it in our organization. thanks for the reply.snowmyr - Monday, September 25, 2017 - link
Check that link again and you'll see that it's not really an anandtech email address and might not get forwarded to the right people.mmrezaie - Monday, September 25, 2017 - link
I sent it to advertisement link I found in the "contact us" page. Sorry by saying support. That's what we call it in our organization. thanks for the reply.AdditionalPylons - Monday, September 25, 2017 - link
Just sent you a tweet with a screenshot, Ryan. I've been very annoyed with these clickbait ads for avery long time as well.
hughc - Monday, September 25, 2017 - link
Wasn't sure what you were referring to. I have AdBlock whitelisting the domain, so I see all the display advertising.I'm also using ClickbaitKiller. Disabled it, and now I can see the unit in question - very happy to hide this trash.
thesavvymage - Monday, September 25, 2017 - link
I get inappropriate ads as well. I'm not sure where I can send a screenshot, but the one I have on this page under the article is "This Is Better Than Adderall, According to US College Students. Try It!"Like what? This is a professional tech site and ads like that have no business being on here. Banner ads for tech companies? Good. Side ads for relevant products? Good. This BS thats always underneath every article? Absolutely unacceptable.
Gothmoth - Monday, September 25, 2017 - link
do you really think anandtech cares how they make money.. maybe when anad was still here.i see these ads too, a website who cares about it´s reputation would distance itself from such crap.. but not anandtech.
ddriver - Monday, September 25, 2017 - link
"maybe when anad was still here" LOL, if he didn't care about money, he'd not sell the site to money makers for money. That's the N1 business model, and the sole motivation for doing anything - get it to get popular, then sell it out, and all its users with it.