Hot Chips: Google TPU Performance Analysis Live Blog (3pm PT, 10pm UTC)
by Ian Cutress on August 22, 2017 5:58 PM EST
06:00PM EDT - Another Hot Chips talk, now talking Google TPU.
06:00PM EDT - TPU first generation is inference only accelerator
06:00PM EDT - 'Batch Size is an easy way to gain perf and efficiency
06:02PM EDT - TPU was a future looking product: in 2013, if everyone wanted to speak to their phone 2-3 minutes a day, it would take 2-3x current total CPU performance
06:02PM EDT - 'TPU project is an investment for when the performance is needed'
06:04PM EDT - Develop machine learning in terms of Tensor Flow, the idea is to make TPU easy
06:05PM EDT - After deploying convolutional neural network, it's interesting how small of our total workload it is
06:05PM EDT - TPU is an accel card over PCIe, it works like a floating point unit

06:06PM EDT - The compute center is a 256x256 matrix unit at 700 MHz
06:06PM EDT - 8-bit MAC units
06:06PM EDT - Peak of 92 T ops/sec
06:06PM EDT - DDR3 interfaces happen to be a bandwidth limit for the original TPU
06:06PM EDT - Not an ideal balanced system, but lots of MACs
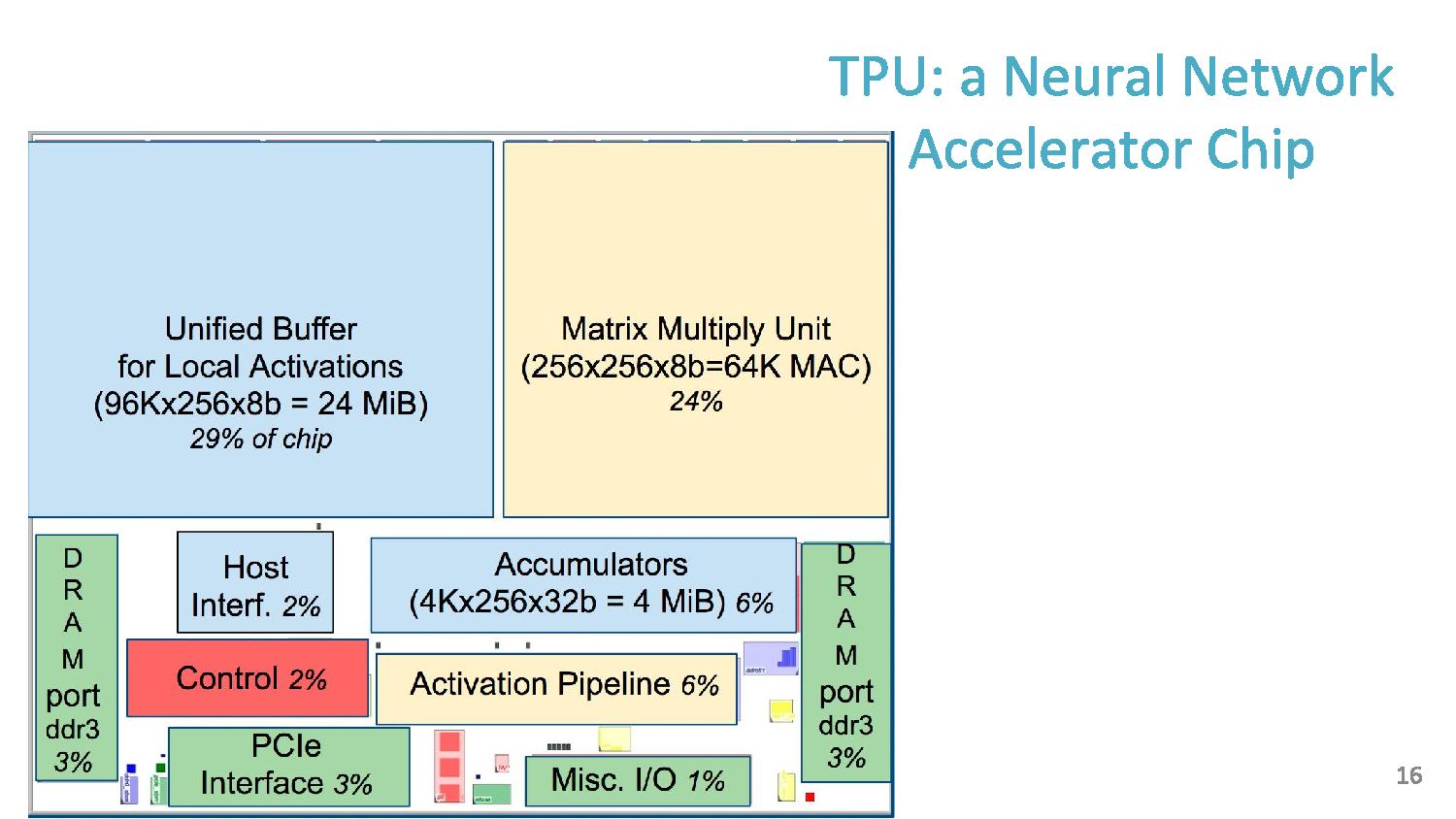
06:07PM EDT - Chip size, 30% for buffer, 24% for matrix unit

06:07PM EDT - Software instruction set has 11 commands, five of which are the ones mostly used
06:07PM EDT - Average 10 clock cycles per instruction
06:08PM EDT - Dispatch 2000 cycles of work in one instruction
06:08PM EDT - In order, no branching
06:08PM EDT - SW controlled buffers
06:08PM EDT - Hardware was developed quickly, difficulty shifted to software to compensate
06:09PM EDT - Problem: energy/time for repeated SRAM accesses of Mat mul

06:09PM EDT - As each input moves across the array, it gets multiplied, then added as it move down the array
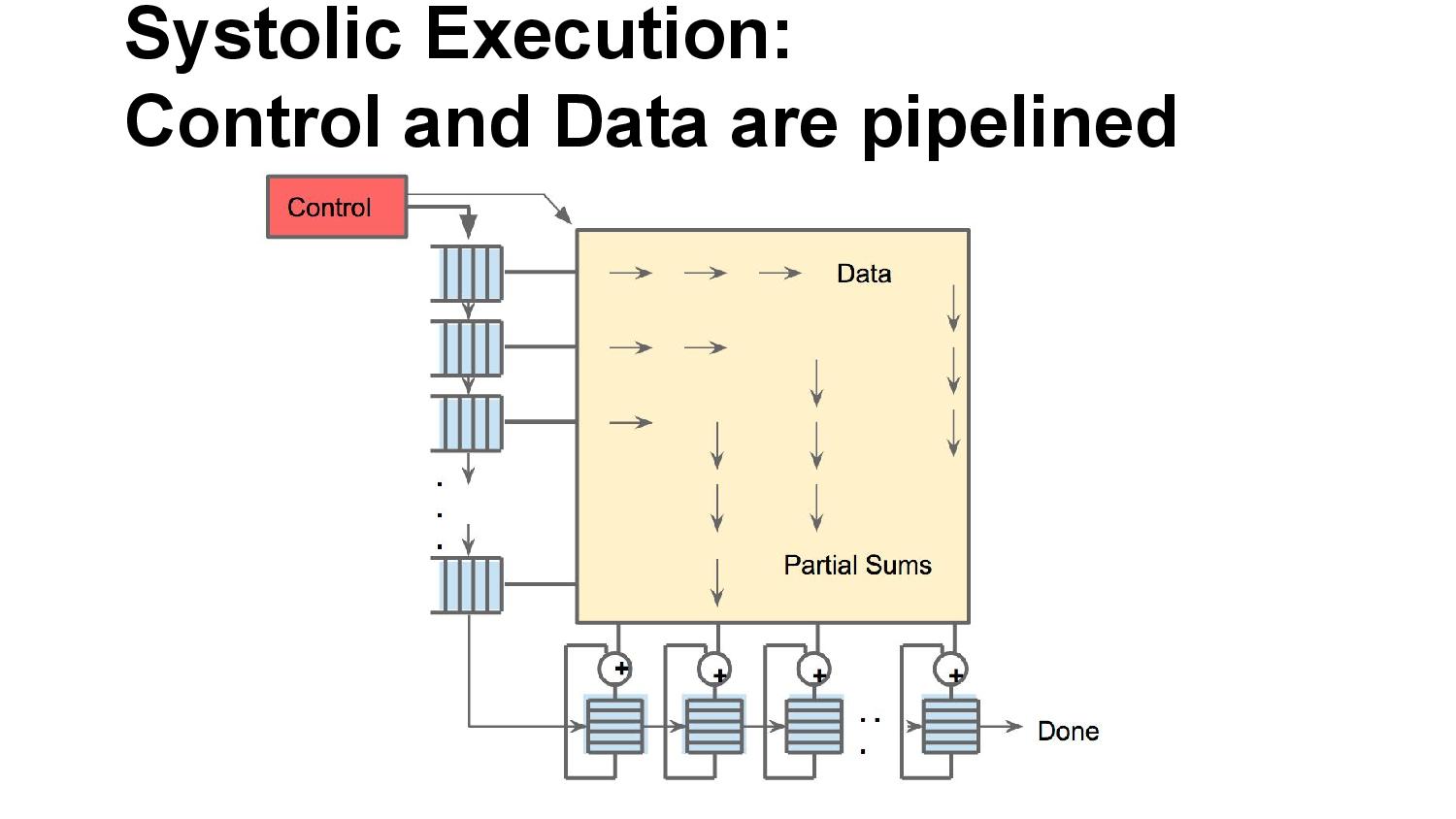
06:09PM EDT - Jagged timings, so systolic
06:10PM EDT - Can ignore pipeline delays by design
06:10PM EDT - First chips in datacenter in 2015, compared to Haswell and K80s
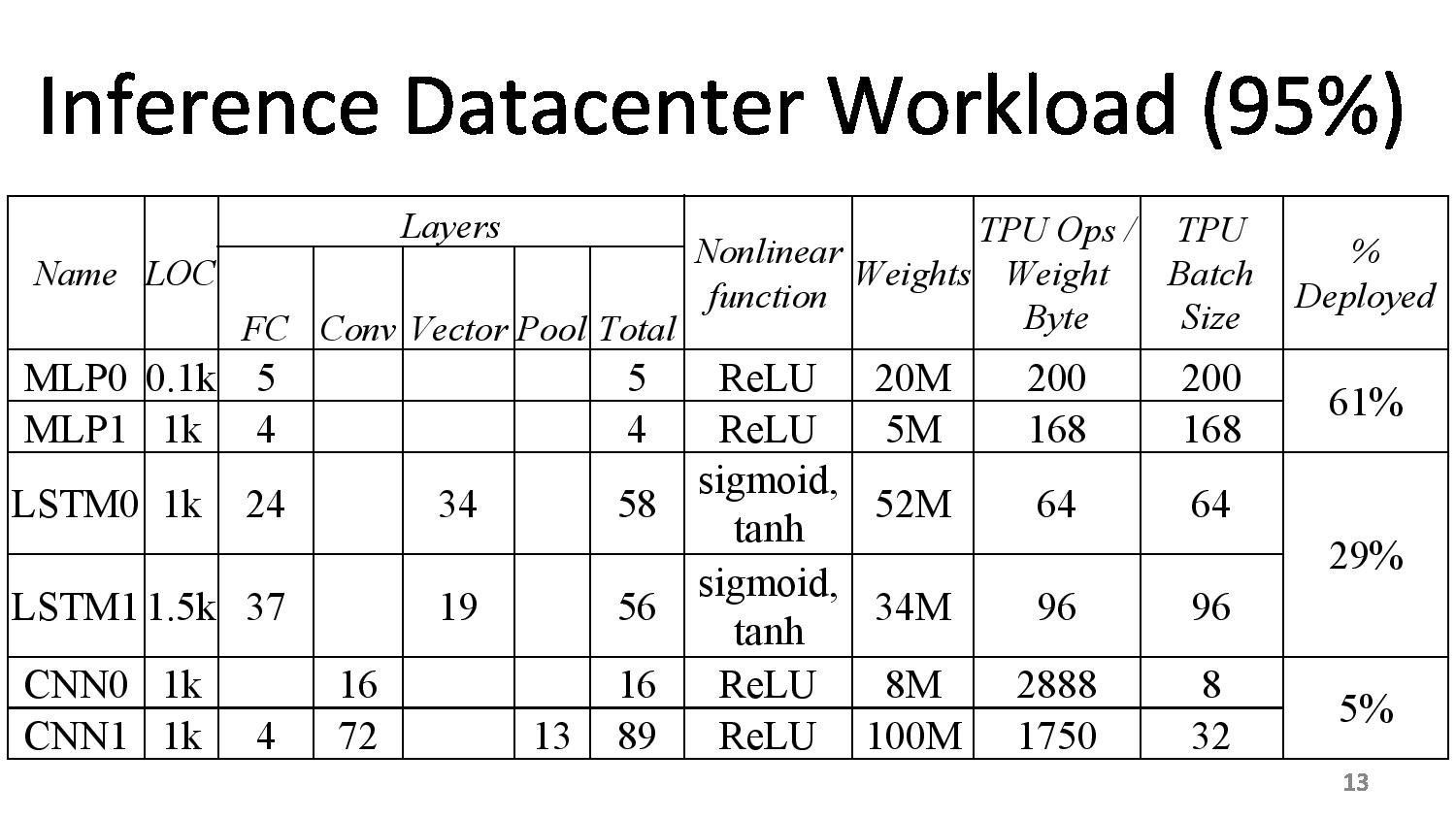
06:10PM EDT - Die size of TPU was smaller, TDP was smaller
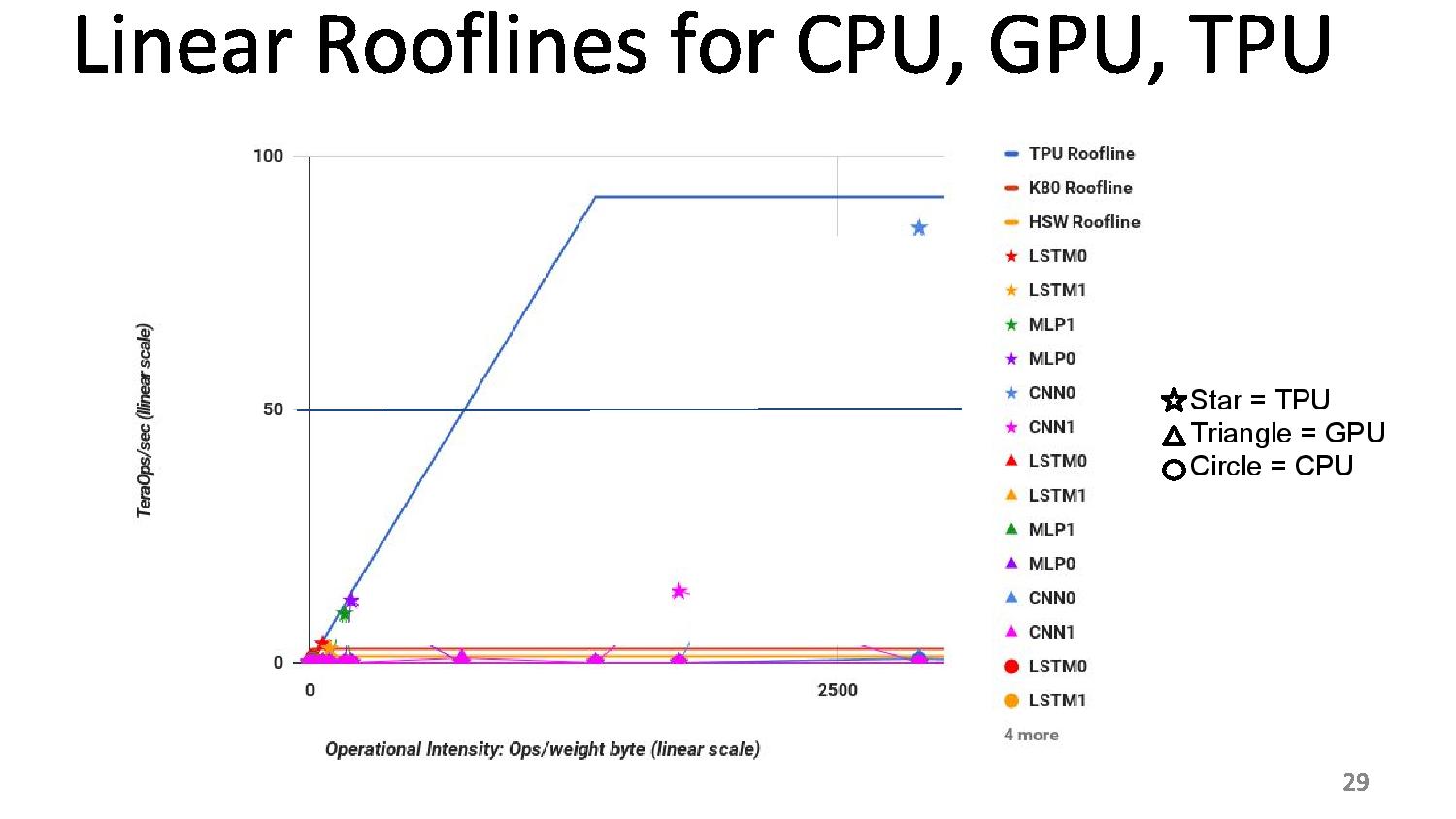
06:10PM EDT - 2 limits to performance: peak computation and peak memory (roof-line model)
06:11PM EDT - Arithmetic intensity (FLOPs per byte) determines which limit you hit
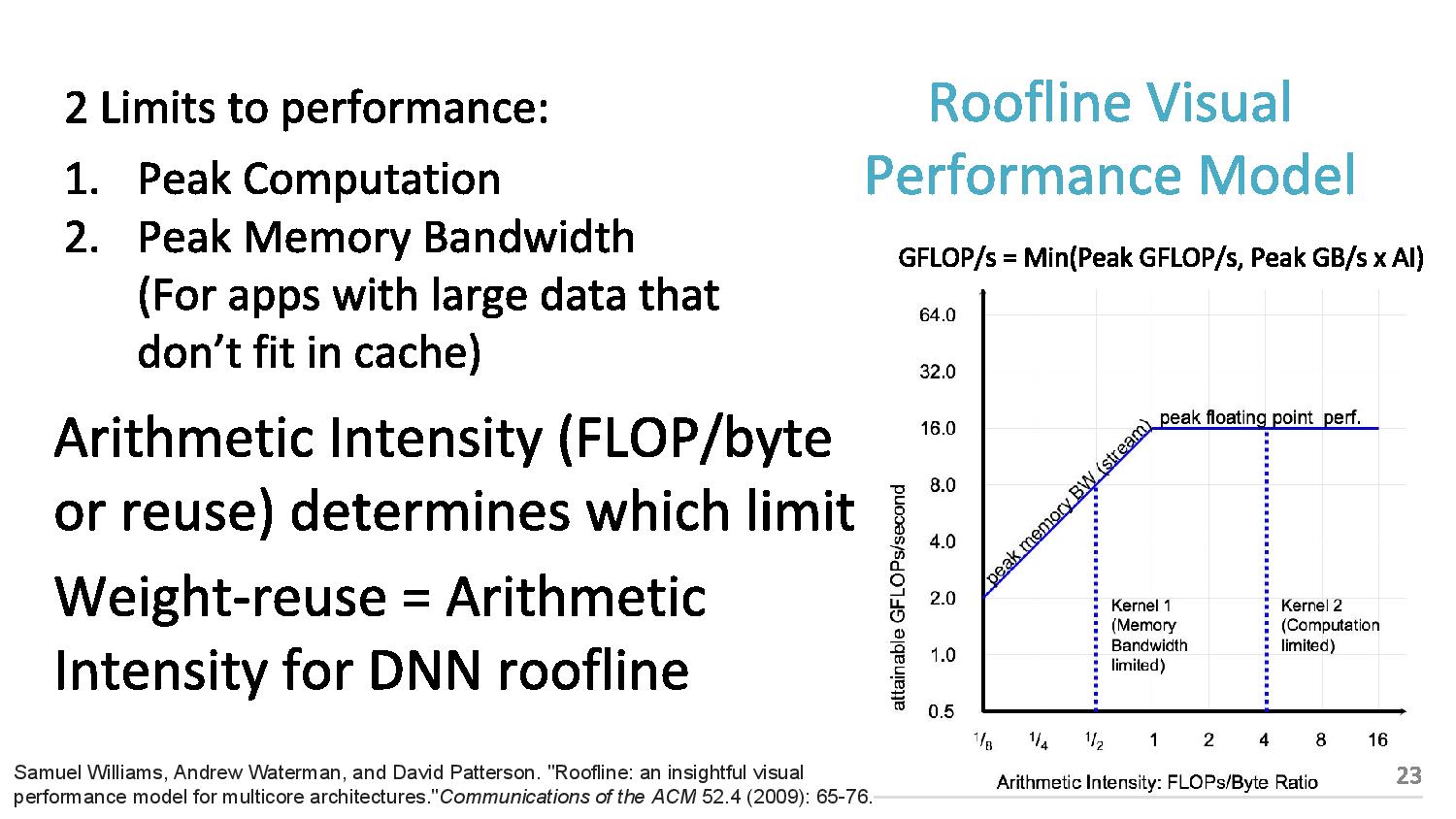
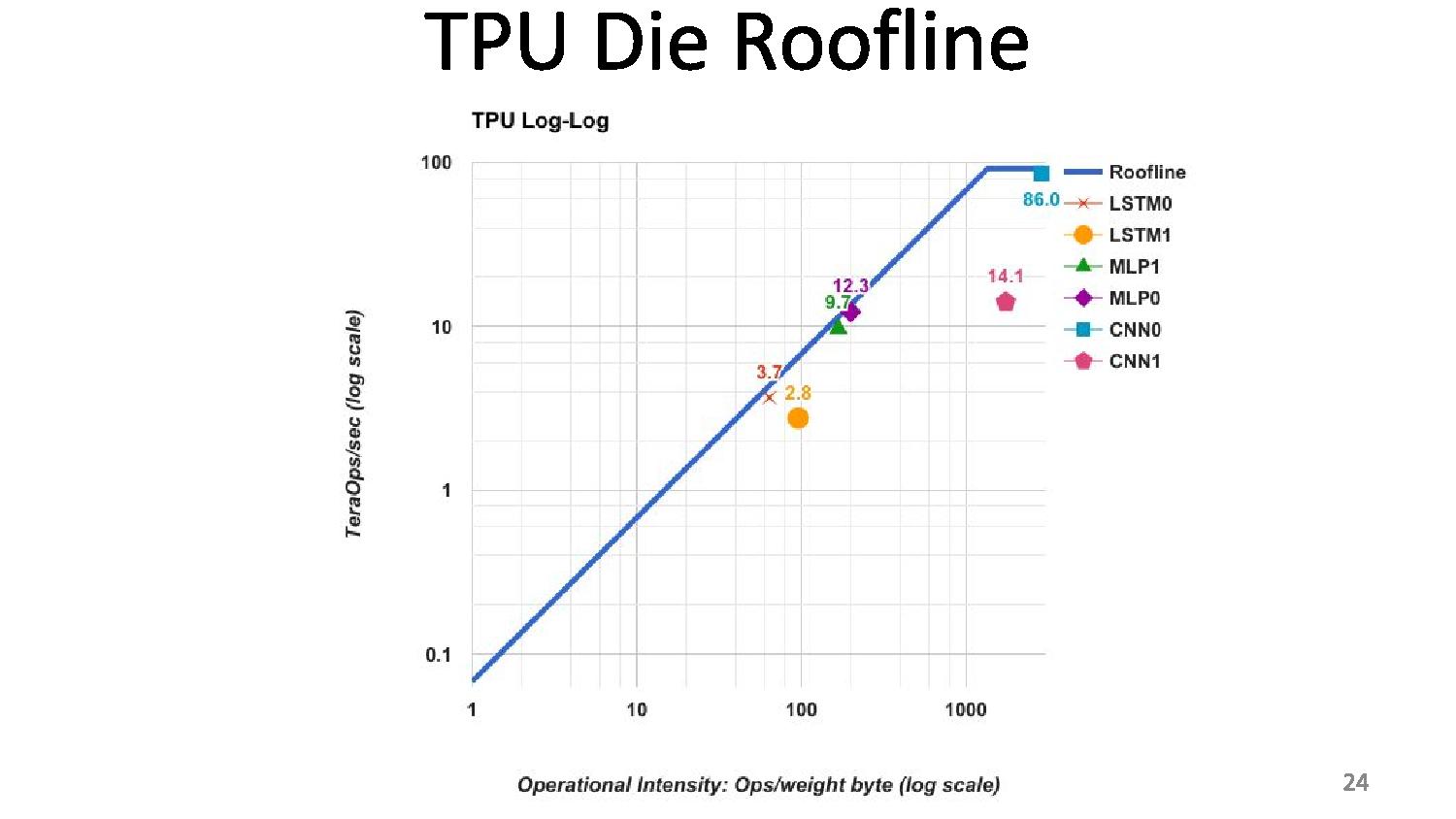
06:12PM EDT - TPU is near peak use in roofline, but only two tests hit the roofline. Other tests hit the memory limit
06:12PM EDT - We thought users would be in the inference cycle limit when first gen was developed
06:12PM EDT - CPUs and GPUs are better balanced, but performance are a lot lower
06:12PM EDT - We built a throughput machine, but it's being used in a latency driven manner

06:15PM EDT - Perf/watt 80x compared to Haswell, 30x compared to K80
06:15PM EDT - Roofline plot says memory limited
06:15PM EDT - So improving TPU: moving the ridge point
06:15PM EDT - Change 2x DDR3 memory to GDDR5 for example, due to memory limit. Improves performance for certain tests
06:15PM EDT - Ends up 200x perf/W over Haswell, 70x over K80
06:17PM EDT - At a top level, the TPU succeeds due to the exercise in application specific design
06:18PM EDT - At a top level, the TPU succeeds due to the exercise in application specific design
06:18PM EDT - As TPUs go forward, we will also get to do backwards compatibility to see how a machine ages
06:18PM EDT - Flexibility to match NNs in 2017 vs 2013
06:18PM EDT - Single threaded deterministic execturion model good match to 99th percentile response time
06:18PM EDT - Apps in Tensor Flow, so easy to port at speed
06:18PM EDT - When you have a large 92 TOPs hammer, everything looks like a NN nail
06:18PM EDT - Run the whole inference model on the TPU
06:18PM EDT - Easy to program due to single thread control, whereas 18-core CPU is difficult to think about
06:19PM EDT - Makes it easy to mentally map problem to single threaded environment, e.g. AlphaGo

06:20PM EDT - In retrospect, inference prefer latency over throughput - K80 poor at inference vs capability in training
06:21PM EDT - In the DRAM, a small redesign improves the TPU a lot (solved in TPUv2
06:21PM EDT - 65546 TPU MACs are cheaper than CPU/GPU MACs

06:21PM EDT - Time for Q&A
06:22PM EDT - Q: What is the minimum size problem to get good efficiency on the TPU - what is the right way to think about that
06:23PM EDT - A: I don't have a complete answer, but colleagues have mapped single layer matmuls and got a good payoff, but the goal is neural networks with lots of weights
06:23PM EDT - Q: Does the system dynamically decide to run on TPU over CPU
06:23PM EDT - A: Not at this time
06:24PM EDT - Q: Precision of matmul?
06:24PM EDT - A: 8-bit by 8-bit integer, unsigned and unsigned
06:24PM EDT - A: 8-bit by 8-bit integer, unsigned and signed
06:24PM EDT - A: 8-bit by 8-bit integer, unsigned and signed*
06:26PM EDT - Q: Does google view sparseness and ever lower precision
06:27PM EDT - A: 1st gen does not do much for sparse-ness. Future products not disclosed in this. Reduced precision is fundamental. We'd love to know where the limit for training and inference is in lower precision
06:27PM EDT - Q: TPU 1 had DDR3, and GDDR5 study got a lot performance, did you build a GDDR5 version?
06:28PM EDT - A: No, but the new TPU uses HBM
06:30PM EDT - Q: How do you port convolution to GEMM? A: Discussed in papers and patents! There's two layers of hardware to improve efficiency
06:32PM EDT - That's all for Q&A. There was a TPU2 talk earlier that I missed that I need to look through the slides of and write up later.
06:32PM EDT - .








30 Comments
View All Comments
serendip - Tuesday, August 22, 2017 - link
Waaaaay over my head, I couldn't understand most of what was written. How exactly does Google use these for neural networks? What aspects of Google Search lend themselves to neural network processing? And how would these cards compare to neuron-like chips being developed by IBM?Threska - Tuesday, August 22, 2017 - link
Something, something, alien math, something. :-pAmeliaPerry - Monday, August 28, 2017 - link
I basically mak℮ about $9,000-$12,000 a month online. It's ℮nough to comfortably replace my old jobs income, especially considering I only work about 10-13 hours a week from home. Go this website and click to "Tech" tab to start your work... http://cutt.us/4DDiGYojimbo - Tuesday, August 22, 2017 - link
Google does a lot more than perform searches. Google uses neural networks for image recognition, translation services, speech recognition, recommendations, ad targeting, self-driving cars, YouTube censorship, beating the world's top go players, and probably other things. As far as search, they are possibly used in interpreting inputted search strings and judging the relevance of search results.IBM's TrueNorth chip, part of a class called neuromorphic computers, is very different from a TPU. Traditional computers have processing units together in one place (such as a CPU), the memory together in another (a RAM chip), and the communication function together. The TPU works this way, even if they are optimizing the data flow by trying to store relevant data close to the processing units. Neuromorphic devices are instead broken up into units with each unit having processing, memory, and communications functionality. The units, which are modeled after neurons, are formed together in a network so that one of the inputs of a unit might be the output of several others. When an input goes into a unit, the neuron "spikes" and sends an output based on the inputs and I believe whatever internal state the unit had. The neurons are event driven instead of running on a clock like a traditional processor.
So, put another way, neural networks are abstract structures modeled after the way the brain works. TPUs are processors designed to take these neural networks and perform manipulations on them, but they do so by using traditional computing architecture, and not by following the model of our brain. Neuromorphic devices like IBM's True North are trying to operate closer to how the neurons in the brain actually operate (they generally don't try to replicate the way the brain works, they just take inspiration from key facets of its operation). Obviously, in theory, neuromorphic devices should be very good candidates to use to operate neural networks, providing you can make an effective one and you can program it effectively.
The advantage of a neuromorphic device is that it avoids the bottleneck associated with moving data between storage and processing units, which uses a whole lot of power. However, programming for them is very different and so I think we don't really know how to get them to do what we want, yet.
Yojimbo - Wednesday, August 23, 2017 - link
BTW, I am no expert on neuromorphic devices, this is just my rudimentary understanding of them. It's possible I've made some errors or left out some key points.WatcherCK - Wednesday, August 23, 2017 - link
Dont sell yourself short, that explanation really helped with understanding what TPU is about, and if i can find the time I am encouraged to go and look for more information about this. Its why my first read of the day is still Anandtech after all these years, partly for the articles and partly for the comments, trolls, gnomes and goblins included. Authors and commentors keep up the hard work :)Xajel - Wednesday, August 23, 2017 - link
Damn, that card looks sexy, although I can't use it in any of my works and needs :Dedzieba - Wednesday, August 23, 2017 - link
Lots of comparison to GK210 rather than GP100/GV100. I understand Google want to say "those were 2015 era and we made the TPU in 2015", but things have changed quite a bit in the GPU realm since then.Yojimbo - Wednesday, August 23, 2017 - link
It certainly made sense when they did the tests in 2015. It was iffy when they released the paper publicly in 2016. But I find it disappointing that they are still seemingly presenting the data as if its currently relevant in 2017.The K80 is a dinosaur in terms of machine learning. The problem is they compare their "TPU" to "GPU" and "CPU" in their 2017 presentation. "GPU" has continued on and changed massively for machine learning workloads since their tests, but their labeling gives an impression that their presented results somehow extrapolate to the GPU lineage and so are still relevant. By now they should not be trying to make such generalizations from their results with 3 generations old hardware.
In my opinion, either they should cast their talk as a historic background of the development and introduction of their TPU, and probably change their charts to say K80 instead of "GPU", or if they are going to give the talk as if its currently relevant they should update their tests with current comparisons.
jospoortvliet - Tuesday, August 29, 2017 - link
They had a 10x diff to CPU and GPU, that won't have been wiped out by the 3%/year improvements in CPU or 50%/year in GPU... I don't disagree a more current comparison would have been nice but this is far from irrelevant.