Intel Xeon E5 Version 3: Up to 18 Haswell EP Cores
by Johan De Gelas on September 8, 2014 12:30 PM ESTCapacity: the New Arms Race
Some of the hottest software trends of today are Big Data and In Memory Business Analytics. Both applications benefit from fast processors, but even more importantly they are virtually unsatiable when it comes to RAM capacity. Another important area that's much closer to the daily work of many IT professionals is virtualization. As heavier applications are being virtualized, the typical amount of memory allocated to virtual machines has increased rapidly. As announced on the latest VMworld, vSphere 6 will now support Virtual machines that allocate up to 4TB (!!) of memory. The days where virtual machines were limited to only a fraction of "native" operating systems are behind us.
With the above developments, support for and development of high capacity DIMMs is crucial. Intel has been steadily improving the support for LRDIMMs (here's some additional information on LRDIMMs). The first Xeon E5-2600 had support for LRDIMMs but it only delivered higher capacity at the expense of lower bandwidth and higher latency. The memory controller of the Xeon E5-2600 v2 had several improvements specifically for LRDIMMs and as a result the latency and throughput tax was greatly reduced.
The advent of DDR4 has given the engineers of IDT the opportunity to give LRDIMMs a performance advantage instead of a disadvantage. By introducing data buffers close to the DRAM chips, they managed to reduce the I/O trace lengths tremendously. See the figure below.
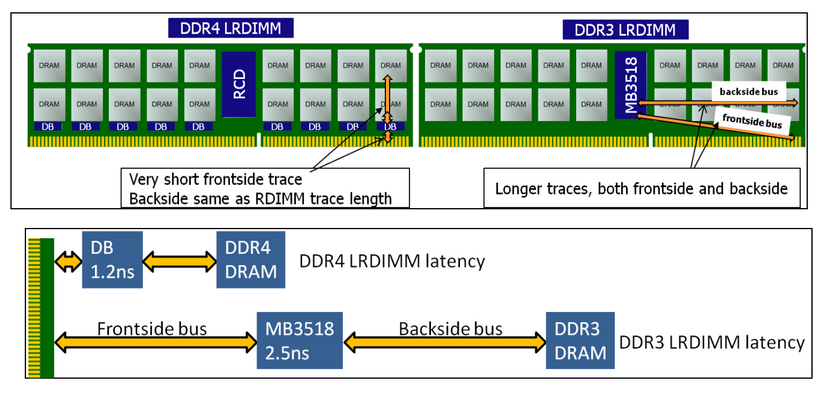
DDR4 and DDR3 LRDIMMs compared, image courtesy of IDT.
The latency overhead of the extra buffering is thus significantly lower on DDR4 LRDIMMs. In other words, compared to Registered DDR4 running at the same speed with 1 DPC (1 DIMM per channel), the latency overhead will be small. As soon as you start to use more DIMMs per channel, LRDIMMs actually offer lower latency as they can run at higher speeds.
Below you can see the evolution of LRDIMM support over the three generations of Xeon E5s. On the far right is the speed of DIMMs on Sandy Bridge EP, in the middle is Ivy Bridge EP, and on the left is the speed of DIMMs on the new Haswell EP Xeon.
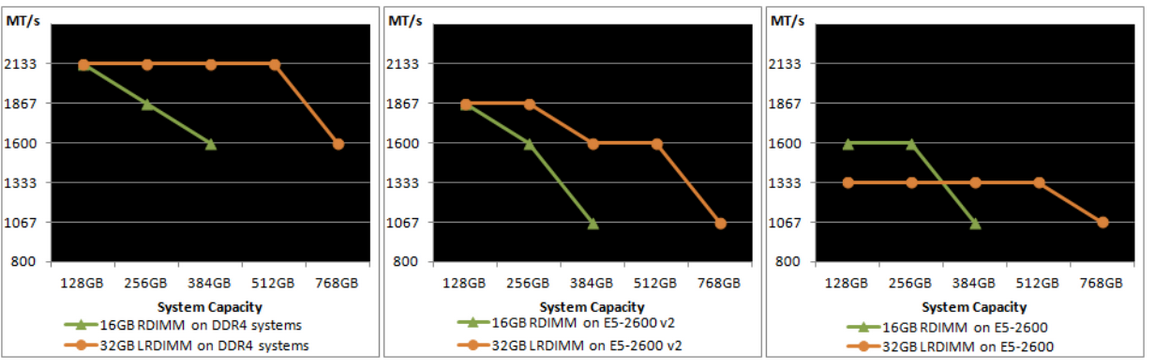
On Sandy Bridge EP (Xeon E5-2600), LRDIMMs were only clocked faster at three DPC. On Ivy Bridge EP (Xeon E5-2600 v2), the LRDIMMs were faster at two and three DPC. And on Haswell EP (Xeon E5-2600 v3), the bandwidth speed gap at two and three DPC has increased while the latency tax (not seen in the picture) has been reduced.

Samsung LRDIMM on top, RDIMM below. Notice the data buffers on the LRDIMM
Several sources tell us that LRDIMMs will be about 20%-25% more expensive. Our task then is to help you decide wether or not the investment is worth it. In this review, we will show some preliminary results.
The latency penalty has been reduced, but what about capacity? As you can see by the 4G marking in the photo above, the DIMMs used in our current servers are still using the mature 4Gbit DRAM chip technology. So currently, the Xeon E5-2600 v2 platform is limited to 384GB of registered DDR4 or 768GB of LRDIMMs. Quad-ranked RDIMMs, which were expensive, slow, and could only be used at 2DPC, are dead. The current 64GB LRDIMMs can be used at 3DPC, but they are Octal (!) ranks using quad-die-packages. As a result they are slow at 3DPC and power hungry.
But the future looks bright. At the end of this year, dual-ranked modules, such as the ones you can see above, will use 8Gb. This results in 64GB LRDIMMs and 32GB RDIMMs. That means the Xeon E5 platform will soon be able to address up to 1.5TB of physical RAM. In the second half of 2015, 128GB LRDIMMs should be available too, allowing up to 3TB of RAM.








85 Comments
View All Comments
cmikeh2 - Monday, September 8, 2014 - link
In the SKU comparison table you have the E5-2690V2 listed as a 12/24 part when it is in fact a 10/20 part. Just a tiny quibble. Overall a fantastic read.KAlmquist - Monday, September 8, 2014 - link
Also, the 2637 v2 is 4/8, not 6/12.isa - Monday, September 8, 2014 - link
Looking forward to a new supercomputer record using these behemoths.Bruce Allen - Monday, September 8, 2014 - link
Awesome article. I'd love to see Cinebench and other applications tests. We do a lot of rendering (currently with older dual Xeons) and would love to compare these new Xeons versus the new 5960X chips - software license costs per computer are so high that the 5960X setups will need much higher price/performance to be worth it. We actually use Cinema 4D in production so those scores are relevant. We use V-Ray, Mental Ray and Arnold for Maya too but in general those track with the Cinebench scores so they are a decent guide. Thank you!Ian Cutress - Monday, September 8, 2014 - link
I've got some E5 v3 Xeons in for a more workstation oriented review. Look out for that soon :)fastgeek - Monday, September 8, 2014 - link
From my notes a while back... two E5-2690 v3's (all cores + turbo enabled) under 2012 Server yielded 3,129 for multithreaded and 79 for single.While not Haswell, I can tell you that four E5-4657L V2's returned 4,722 / 94 respectively.
Hope that helps somewhat. :-)
fastgeek - Monday, September 8, 2014 - link
I don't see a way to edit my previous comment; but those scores were from Cinebench R15wireframed - Saturday, September 20, 2014 - link
You pay for licenses for render Nodes? Switch to 3DS, and you get 9999 nodes for free (unless they changed the licensing since I last checked). :)Lone Ranger - Monday, September 8, 2014 - link
You make mention that the large core count chips are pretty good about raising their clock rate when only a few cores are active. Under Linux, what is the best way to see actual turbo frequencies? cpuinfo doesn't show live/actual clock rate.JohanAnandtech - Monday, September 8, 2014 - link
The best way to do this is using Intel's PCM. However, this does not work right now (only on Sandy and Ivy, not Haswel) . I deduced it from the fact that performance was almost identical and previous profiling of some of our benchmarks.