AMD Radeon HD 7970 Review: 28nm And Graphics Core Next, Together As One
by Ryan Smith on December 22, 2011 12:00 AM EST- Posted in
- GPUs
- AMD
- Radeon
- ATI
- Radeon HD 7000
A Quick Refresher: Graphics Core Next
One of the things we’ve seen as a result of the shift from pure graphics GPUs to mixed graphics and compute GPUs is how NVIDIA and AMD go about making their announcements and courting developers. With graphics GPUs there was no great need to discuss products or architectures ahead of time; a few choice developers would get engineering sample hardware a few months early, and everyone else would wait for the actual product launch. With the inclusion of compute capabilities however comes the need to approach launches in a different manner, a more CPU-like manner.
As a result both NVIDIA and AMD have begun revealing their architectures to developers roughly six months before the first products launch. This is very similar to how CPU launches are handled, where the basic principles of an architecture are publically disclosed months in advance. All of this is necessary as the compute (and specifically, HPC) development pipeline is far more focused on optimizing code around a specific architecture in order to maximize performance; whereas graphics development is still fairly abstracted by APIs, compute developers want to get down and dirty, and to do that they need to know as much about new architectures as possible as soon as possible.
It’s for these reasons that AMD announced Graphics Core Next, the fundamental architecture behind AMD’s new GPUs, back in June of this year at the AMD Fusion Developers Summit. There are some implementation and product specific details that we haven’t known until now, and of course very little was revealed about GCN’s graphics capabilities, but otherwise on the compute side AMD is delivering on exactly what they promised 6 months ago.
Since we’ve already covered the fundamentals of GCN in our GCN preview and the Radeon HD 7970 is primarily a gaming product we’re not going to go over GCN in depth here, but I’d encourage you to read our preview to fully understand the intricacies of GCN. But if you’re not interested in that, here’s a quick refresher on GCN with details pertinent to the 7970.
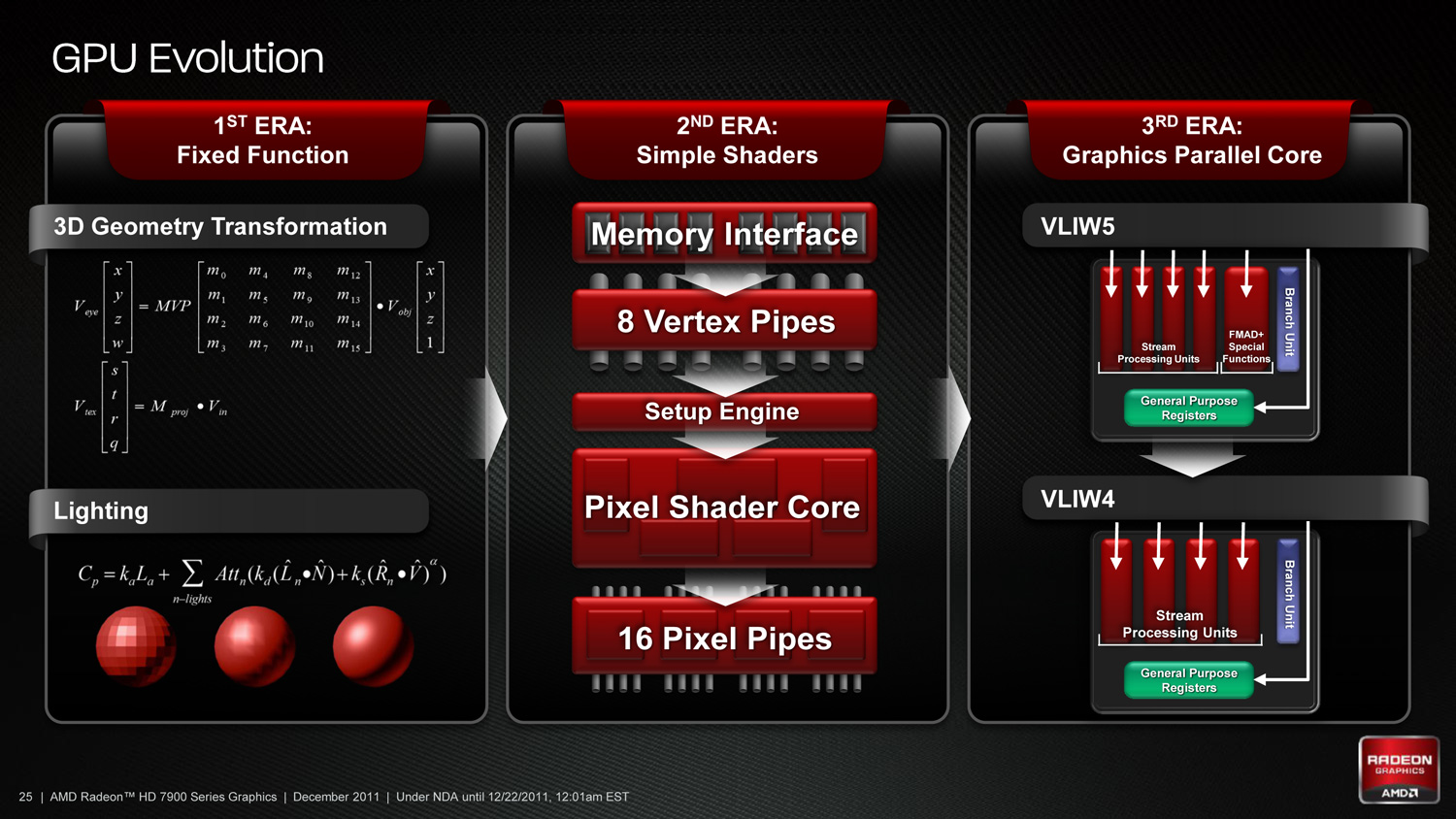
As we’ve already seen in some depth with the Radeon HD 6970, VLIW architectures are very good for graphics work, but they’re poor for compute work. VLIW designs excel in high instruction level parallelism (ILP) use cases, which graphics falls under quite nicely thanks to the fact that with most operations pixels and the color component channels of pixels are independently addressable datum. In fact at the time of the Cayman launch AMD found that the average slot utilization factor for shader programs on their VLIW5 architecture was 3.4 out of 5, reflecting the fact that most shader operations were operating on pixels or other data types that could be scheduled together
Meanwhile, at a hardware level VLIW is a unique design in that it’s the epitome of the “more is better” philosophy. AMD’s high steam processor counts with VLIW4 and VLIW5 are a result of VLIW being a very thin type of architecture that purposely uses many simple ALUs, as opposed to fewer complex units (e.g. Fermi). Furthermore all of the scheduling for VLIW is done in advance by the compiler, so VLIW designs are in effect very dense collections of simple ALUs and cache.
The hardware traits of VLIW mean that for a VLIW architecture to work, the workloads need to map well to the architecture. Complex operations that the simple ALUs can’t handle are bad for VLIW, as are instructions that aren’t trivial to schedule together due to dependencies or other conflicts. As we’ve seen graphics operations do map well to VLIW, which is why VLIW has been in use since the earliest pixel shader equipped GPUs. Yet even then graphics operations don’t achieve perfect utilization under VLIW, but that’s okay because VLIW designs are so dense that it’s not a big problem if they’re operating at under full efficiency.
When it comes to compute workloads however, the idiosyncrasies of VLIW start to become a problem. “Compute” covers a wide range of workloads and algorithms; graphics algorithms may be rigidly defined, but compute workloads can be virtually anything. On the one hand there are compute workloads such as password hashing that are every bit as embarrassingly parallel as graphics workloads are, meaning these map well to existing VLIW architectures. On the other hand there are tasks like texture decompression which are parallel but not embarrassingly so, which means they map poorly to VLIW architectures. At one extreme you have a highly parallel workload, and at the other you have an almost serial workload.
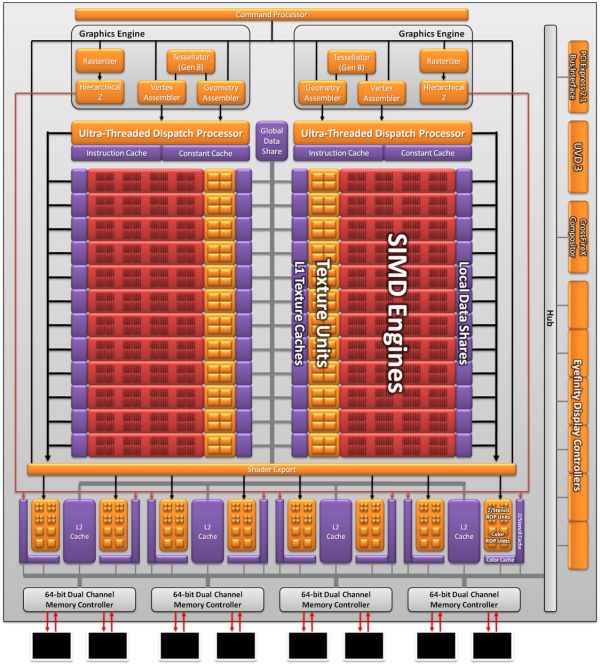
Cayman, A VLIW4 Design
So long as you only want to handle the highly parallel workloads VLIW is fine. But using VLIW as the basis of a compute architecture is going is limit what tasks your processor is sufficiently good at. If you want to handle a wider spectrum of compute workloads you need a more general purpose architecture, and this is the situation AMD faced.
But why does AMD want to chase compute in the first place when they already have a successful graphics GPU business? In the long term GCN plays a big part in AMD’s Fusion plans, but in the short term there’s a much simpler answer: because they have to.
In Q3’2011 NVIDIA’s Professional Solutions Business (Quadro + Tesla) had an operating income of 95M on 230M in revenue. Their (consumer) GPU business had an operating income of 146M, but on a much larger 644M in revenue. Professional products have much higher profit margins and it’s a growing business, particularly the GPU computing side. As it stands NVIDIA and AMD may have relatively equal shares of the discrete GPU market, but it’s NVIDIA that makes all the money. For AMD’s GPU business it’s no longer enough to focus only on graphics, they need a larger piece of the professional product market to survive and thrive in the future. And thus we have GCN.








292 Comments
View All Comments
B3an - Thursday, December 22, 2011 - link
Anyone with half a brain should have worked out that being as this was going to be AMD's Fermi that it would not of had a massive increase for gaming, simply because many of those extra transistors are there for computing purposes. NOT for gaming. Just as with Fermi.The performance of this card is pretty much exactly as i expected.
Peichen - Friday, December 23, 2011 - link
AMD has been saying for ages that GPU computing is useless and CPU is the only way to go. I guess they just have a better PR department than Nvidia.BTW, before suggesting I have suffered brain trauma, remember that Nvidia delivered on Fermi 2 and GK100 will be twice as powerful as GF110
CeriseCogburn - Thursday, March 8, 2012 - link
Well it was nice to see the amd fans with half a heart admit amd has accomplished something huge by abandoned gaming, as they couldn't get enough of screaming it against nvidia... even as the 580 smoked up the top line stretch so many times...It's so entertaining...
CeriseCogburn - Thursday, March 8, 2012 - link
AMD is the dumb company. Their dumb gpu shaders. Their x86 copying of intel. Now after a few years they've done enough stealing and corporate espionage to "clone" Nvidia architecture and come out with this 7k compute.If they're lucky Nvidia will continue doing all software groundbreaking and carry the massive load by a factor of ten or forty to one working with game developers, porting open gl and open cl to workable programs and as amd fans have demanded giving them PhysX ported out to open source "for free", at which point it will suddenly be something no gamer should live without.
"Years behind" is the real story that should be told about amd and it's graphics - and it's cpu's as well.
Instead we are fed worthless half truths and lies... a "tesselator" in the HD2900 (while pathetic dx11 perf is still the amd norm)... the ddr5 "groundbreaker" ( never mentioned was the sorry bit width that made cheap 128 and 256 the reason for ddr5 needs)...
Etc.
When you don't see the promised improvement, the radeonites see a red rocket shooting to the outer depths of the galaxy and beyond...
Just get ready to pay some more taxes for the amd bailout coming.
durinbug - Thursday, December 22, 2011 - link
I was intrigued by the comment about driver command lists, somehow I missed all of that when it happened. I went searching and finally found this forum post from Ryan:http://forums.anandtech.com/showpost.php?p=3152067...
It would be nice to link to that from the mention of DCL for those of us not familiar with it...
digitalzombie - Thursday, December 22, 2011 - link
I know I'm a minority, but I use Linux to crunch data and GPU would help a lot...I was wondering if you guys can try to use these cards on Debian/Ubuntu or Fedora? And maybe report if 3d acceleration actually works? My current amd card have bad driver for Linux, shearing and glitches, which sucks when I try to number crunch and map stuff out graphically in 3d. Hell I try compiling the driver's source code and it doesn't work.
Thank you!
WaltC - Thursday, December 22, 2011 - link
Somebody pinch me and tell me I didn't just read a review of a brand-new, high-end ATi card that apparently *forgot* Eyefinity is a feature the stock nVidia 580--the card the author singles out for direct comparison with the 7970--doesn't offer in any form. Please tell me it's my eyesight that is failing, because I missed the benchmark bar charts detailing the performance of the Eyefinity 6-monitor support in the 7970 (but I do recall seeing esoteric bar-chart benchmarks for *PCIe 3.0* performance comparisons, however. I tend to think that multi-monitor support, or the lack of it, is far more an important distinction than PCIe 3.0 support benchmarks at present.)Oh, wait--nVidia's stock 580 doesn't do nVidia's "NV Surround triple display" and so there was no point in mentioning that "trivial fact" anywhere in the article? Why compare two cards so closely but fail to mention a major feature one of them supports that the other doesn't? Eh? Is it the author's opinion that multi-monitor gaming is not worth having on either gpu platform? If so, it would be nice to know that by way of the author's admission. Personally, I think that knowing whether a product will support multi monitors and *playable* resolutions up to 5760x1200 ROOB is *somewhat* important in a product review. (sarcasm/massive understatement)
Aside from that glaring oversight, I thought this review was just fair, honestly--and if the author had been less interested in apologizing for nVidia--we might even have seen a better one. Reading his hastily written apologies was kind of funny and amusing, though. But leaving out Eyefinity performance comparisons by pretending the feature isn't relative to the 7970, or that it isn't a feature worth commenting on relative to nVidia's stock 580? Very odd. The author also states: "The purpose of MST hubs was so that users could use several monitors with a regular Radeon card, rather than needing an exotic all-DisplayPort “Eyefinity edition” card as they need now," as if this is an industry-standard component that only ATi customers are "asking for," when it sure seems like nVidia customers could benefit from MST even more at present.
I seem to recall reading the following statement more than once in this review but please pardon me if it was only stated once: "... but it’s NVIDIA that makes all the money." Sorry but even a dunce can see that nVidia doesn't now and never has "made all the money." Heh...;) If nVidia "made all the money," and AMD hadn't made any money at all (which would have to be the case if nVidia "made all the money") then we wouldn't see a 7970 at all, would we? It's possible, and likely, that the author meant "nVidia made more money," which is an independent declaration I'm not inclined to check, either way. But it's for certain that in saying "nVidia made all the money" the author was--obviously--wrong.
The 7970 is all the more impressive considering how much longer nVidia's had to shape up and polish its 580-ish driver sets. But I gather that simple observation was also too far fetched for the author to have seriously considered as pertinent. The 7970 is impressive, AFAIC, but this review is somewhat disappointing. Looks like it was thrown together in a big hurry.
Finally - Friday, December 23, 2011 - link
On AT you have to compensate for their over-steering while reading.Death666Angel - Thursday, December 22, 2011 - link
"Intel implemented Quick Sync as a CPU company, but does that mean hardware H.264 encoders are a CPU feature?" << Why is that even a question. I cannot use the feature unless I am using the iGPU or use the dGPU with Lucid Virtu. As such, it is not a feature of the CPU in my book.Roald - Thursday, December 22, 2011 - link
I don't agree with the conclusion. I think it's much more of a perspective thing. Comming from the 6970 to the 7970 it's not a great win in the gaming deparment. However the same can be said from the change from 4870 to 5870 to 6970. The only real benefit the 5870 had over the 4870 was DX11 support, which didn't mean so much for the games at the time.Now there is a new architechture that not only manages to increase FPS in current games, it also has growing potential and manages to excell in the compute field aswell at the same time.
The conclusion made in the Crysis warhead part of this review should therefore also have been highlighted as finals words.