AMD Discloses Bobcat & Bulldozer Architectures at Hot Chips 2010
by Anand Lal Shimpi on August 24, 2010 1:33 AM ESTA Real Redesign
When we first met Phenom we were disappointed that it didn’t introduce the major architectural changes AMD needed to keep up with Intel. The front end and execution hardware remained largely unchanged from the K8, and as a result Intel pulled ahead significantly in performance per clock over the past few years. With Bulldozer, we finally got the redesign that we’ve been asking for.
If we look at Westmere, Intel has a 4-issue architecture that’s shared among two threads. At the front end, a single Bulldozer module is essentially the same. The fetch logic in Bulldozer can grab instructions from two threads and send it to the decoder. Note that either thread can occupy the full width of the front end if necessary.
The instruction fetcher pulls from a 64KB 2-way instruction cache, unchanged from the Phenom II.
The decoder is now 4-wide an increase from the 3-wide front end that AMD has had since the K7 all the way up to Phenom II. AMD can now fuse x86 branch instructions, similar to Intel’s macro-ops fusion to increase the effective width of the machine as well. At a high level, AMD’s front end has finally caught up to Intel, but here’s where AMD moves into the passing lane.
The 4-wide decode engine feeds three independent schedulers: two for the integer cores and one for the shared floating point hardware.
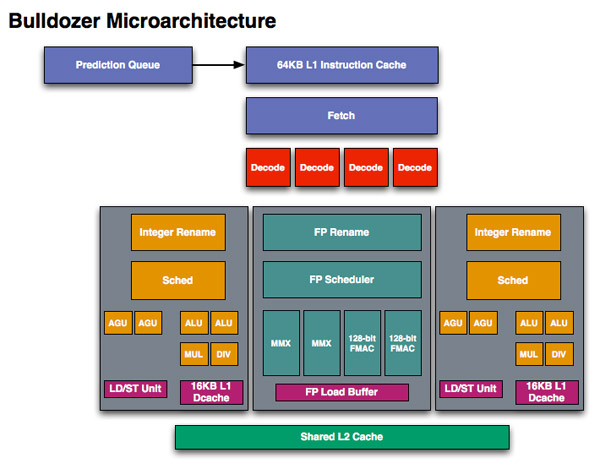
Bullddozer, 2 threads per module
Each integer scheduler is now unified. In the Phenom II and previous architectures AMD had individual schedulers for math and address operations, but with Bulldozer it’s all treated as one.
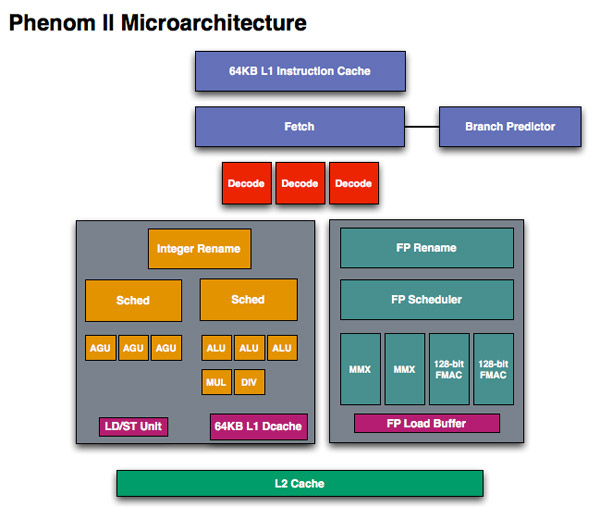
Phenom II, 1 thread per core
Each scheduler has four ports that feed a pair of ALUs and a pair of AGUs. This is down one ALU/AGU from Phenom II (it had 3 ALUs and 3 AGUs respectively and could do any mix of 3). AMD insists that the 3rd address generation unit wasn’t necessary in Phenom II and was only kept around for symmetry with the ALUs and to avoid redesigning that part of the chip - the integer execution core is something AMD has kept around since the K8. The 3rd ALU does have some performance benefits, and AMD canned it to reduce die size, but AMD mentioned that the 4-wide front end, fusion and other enhancements more than make up for this reduction. In other words, while there’s fewer single thread integer execution resources in Bulldozer than Phenom II, single threaded integer performance should still be higher.
Each integer core has its own 16KB L1 data cache. The L1 caches are segmented by thread so the shared FP core chooses which L1 cache to pull from depending on what thread it’s working on.
I asked AMD if the small L1 data cache was going to be a problem for performance, but it mentioned that in modern out of order machines it’s quite easy to hide the latency to L2 and thus this isn’t as big of an issue as you’d think. Given how aggressive AMD has been in the past with ramping up L1 cache sizes, this is a definite change of pace which further indicates how significant of a departure Bulldozer is from the norm at AMD.

While there are two integer schedulers in a single Bulldozer module (one for each thread), there’s only one FP scheduler. There’s some hardware duplication at the FP scheduler to allow two threads to share the execution resources behind it. While each integer core behaves like an independent core, the FP resources work as they would in a SMT (Hyper Threading) system.
The FP scheduler has four ports to its FPUs. There are two 128-bit FMAC pipes and two 128-bit packed integer pipes. Like Sandy Bridge, AMD’s Bulldozer will support SSE all the way up to 4.2 as well as Intel’s new AVX instructions. The 256-bit AVX ops will be handled by the two 128-bit FMAC units in each Bulldozer module.
Each Bulldozer module has its own private L2 cache shared by both integer cores and the FP execution hardware.








76 Comments
View All Comments
ROad86 - Thursday, August 26, 2010 - link
I think without being a pc expert that amd was trying to maximaze the multi-thread perfomance in less die size and being more efficient at power consumption. But i believe that they are still developing Bulldozer in order to maximaze single thread perfomance too. In desktop not much applications are threaded well in enough so they have to be competive in single thread perfomance too. Thats why I believe they dont announce release date yet. Among side the new manufactaring procces at 32 nm and I think the waiting for the release of sandy-bridge in order to see how better are intel new processors, the release date will be probably Q4 2011. But these are just speculations.Vallwesture - Thursday, August 26, 2010 - link
It has been over two years...ROad86 - Thursday, August 26, 2010 - link
New architecture, completly new design, maybe softaware too needs too be optimazed(windows 7 for example), in the end lets hope to bring something truly amazing. On paper it does but lets wait for reviews!KonradK - Thursday, August 26, 2010 - link
"The basic building block is the Bulldozer module. AMD calls this a dual-core module because it has two independent integer cores and a single shared floating point core that can service instructions from two independent threads"I'm curious whether CPU shedulers can distinguish between cores located in the same module from cores located in other modules of Bulldozer .
Because two cores located in the same module share one FPU unit , running two FPU heavy threads on two cores located in the same module and leaving cores in other modules idle would be at least unoptimal.
Simen1 - Tuesday, August 31, 2010 - link
From page 6: "Aggressive prefetching usually means there’s a good amount of memory bandwidth available so I’m wondering if we’ll see Bulldozer adopt a 3 - 4 channel DDR3 memory controller in high end configurations similar to what we have today with Gulftown."AMD already have a 4 channel DDR3 design. Its in the Opteron 6100-line of processors on the G34 socket (LGA1974). AMD have promised it will be compatible with future bulldozer-based processors.
liem107 - Monday, September 6, 2010 - link
I wonder how bobcat would fare against the VIA Nano. Considering VIA s portfolio, it would be a good aquisition for Nvidia for example to get their hands on a fairly good x86 core and license.