Intel Unveils Meteor Lake Architecture: Intel 4 Heralds the Disaggregated Future of Mobile CPUs
by Gavin Bonshor on September 19, 2023 11:35 AM ESTSoC Tile, Part 2: NPU Adds a Physical AI Engine
The last major block on the SoC tile is a full-featured Neural Processing Unit (NPU), a first for Intel's client-focused processors. The NPU brings AI capabilities directly to the chip and is compatible with standardized program interfaces like OpenVINO. The architecture of the NPU itself is multi-engine in nature, which is comprised of two neural compute engines that can either collaborate on a single task or operate independently. This flexibility is crucial for diverse workloads and potentially benefits future workloads that haven't yet been optimized for AI situations or are in the process of being developed. Two primary components of these neural compute engines stand out: the Inference Pipeline and the SHAVE DSP.

The Inference Pipeline is primarily responsible for executing workloads in neural network execution. It minimizes data movement and focuses on fixed-function operations for tasks that require high computational power. The pipeline comprises a sizable array of Multiply Accumulate (MAC) units, an activation function block, and a data conversion block. In essence, the inference pipeline is a dedicated block optimized for ultra-dense matrix math.
The SHAVE DSP, or Streaming Hybrid Architecture Vector Engine, is designed specifically for AI applications and workloads. It has the capability to be pipelined along with the Inference Pipeline and the Direct Memory Access (DMA) engine, thereby enabling parallel computing on the NPU to improve overall performance. The DMA Engine is designed to efficiently manage data movement, contributing to the system's overall performance.
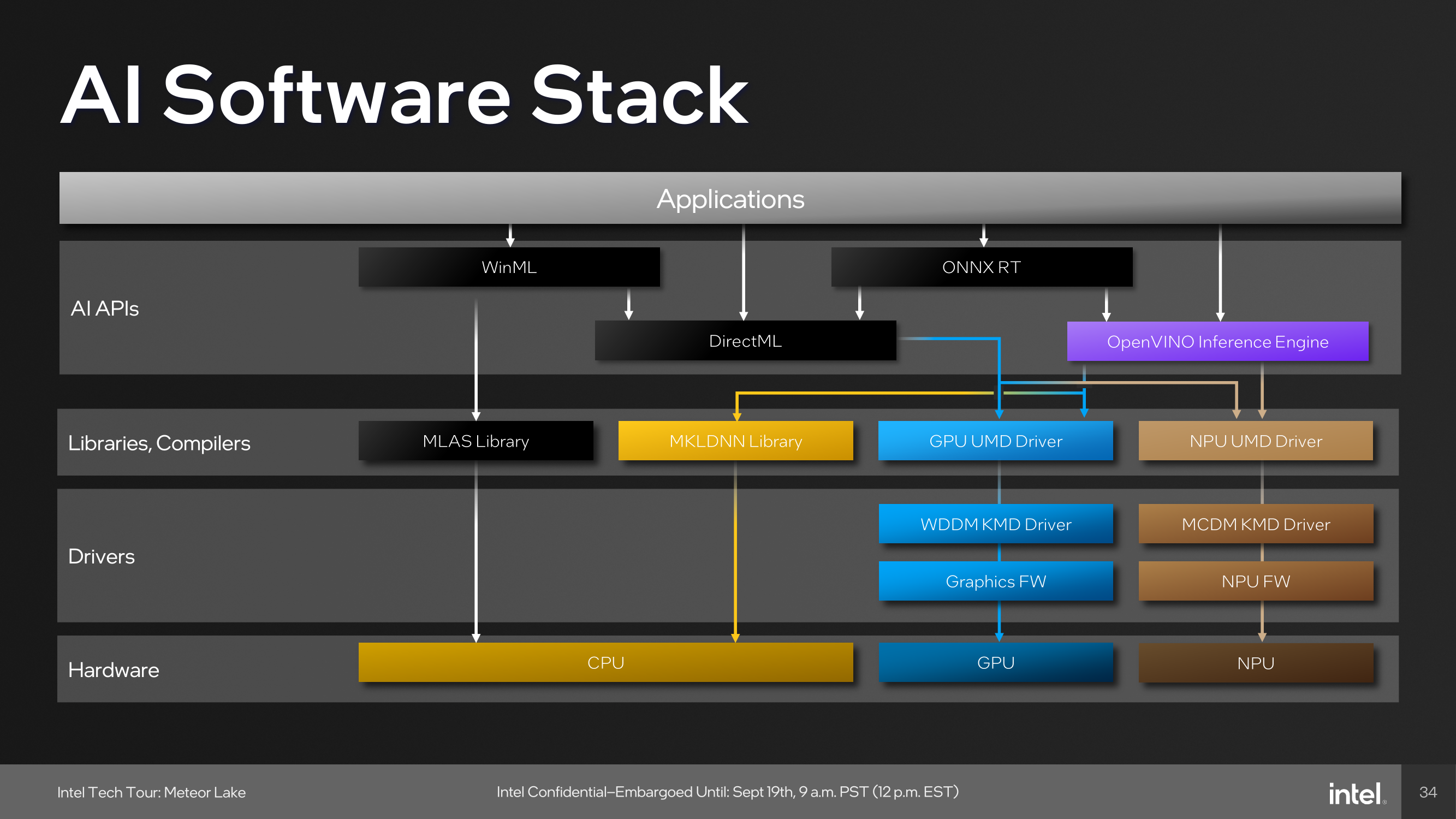
At the heart of device management, the NPU is designed to be fully compatible with Microsoft's new compute driver model, known as MCDM. This isn't merely a feature, but it's an optimized implementation with a strong emphasis on security. The Memory Management Unit (MMU) complements this by offering multi-context isolation and facilitates rapid and power-efficient transitions between different power states and workloads.

As part of building an ecosystem that can capitalize on Intel's NPU, they have been embracing developers with a number of tools. One of these is the open-source OpenVINO toolkit, which supports various models such as TensorFlow, PyTorch, and Caffe. Supported APIs include Windows Machine Learning (WinML), which also includes the DirectML component of the library, the ONNX Runtime accelerator, and OpenVINO.
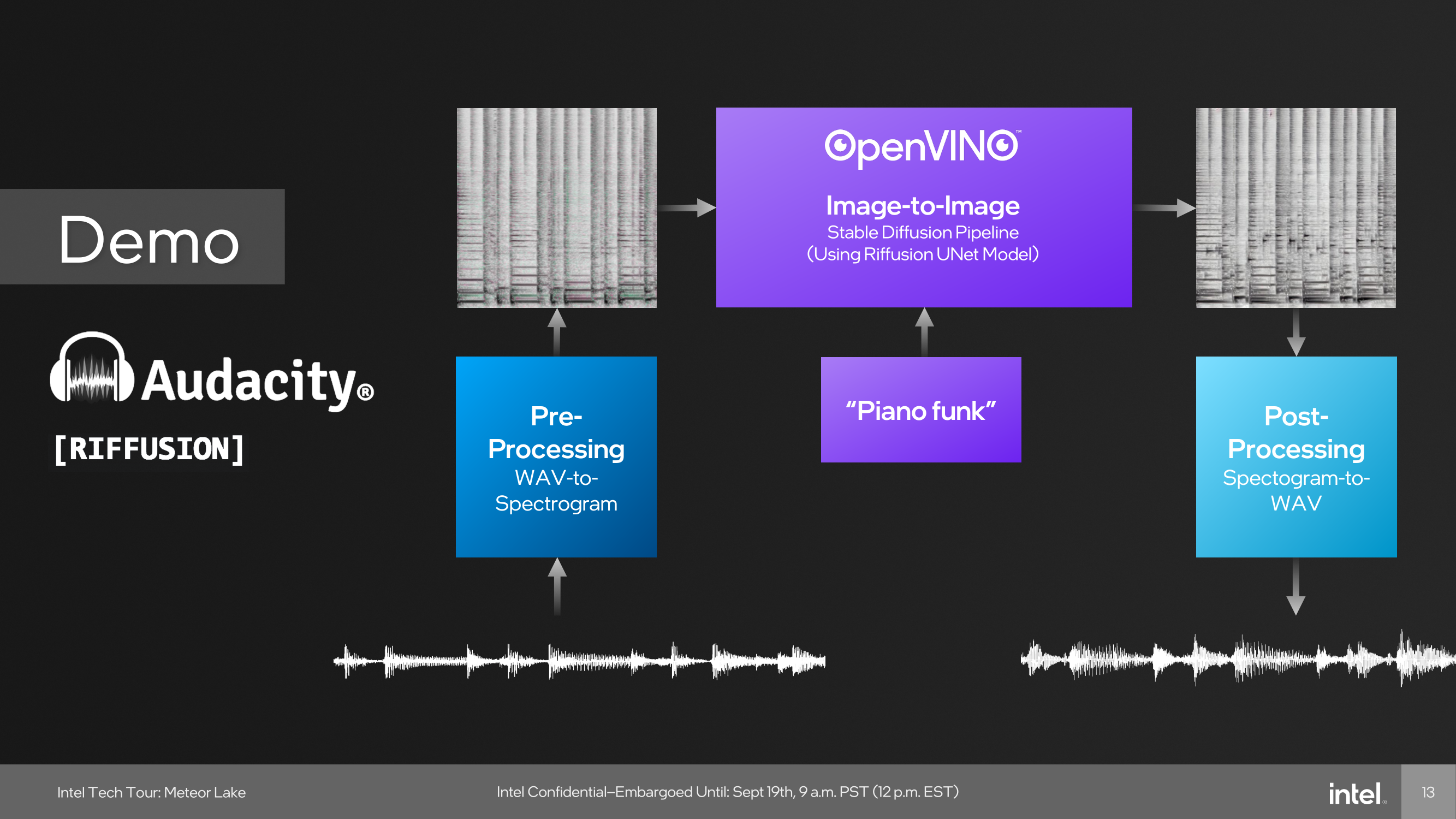
One example of the capabilities of the NPU was provided through a demo using Audacity during Intel's Tech Tour in Penang, Malaysia. During this live demo, Intel Fellow Tom Peterson, used Audacity to showcase a new plugin called Riffusion. This fed a funky audio track with vocals through Audacity and separated the audio tracks into two, vocals and music. Using the Riffusion plugin to separate the tracks, Tom Peterson was then able to change the style of the music audio track to a dance track.
The Riffusion plugin for Audacity uses Stable Diffusion, which is an open-source AI model that traditionally generates images from text. Riffusion goes one step further by generating images of spectrograms, which can then be converted into audio. We touch on Riffusion and Stable Diffusion because this was Intel's primary showcase of the NPU during Intel's Tech Tour 2023 in Penang, Malaysia.
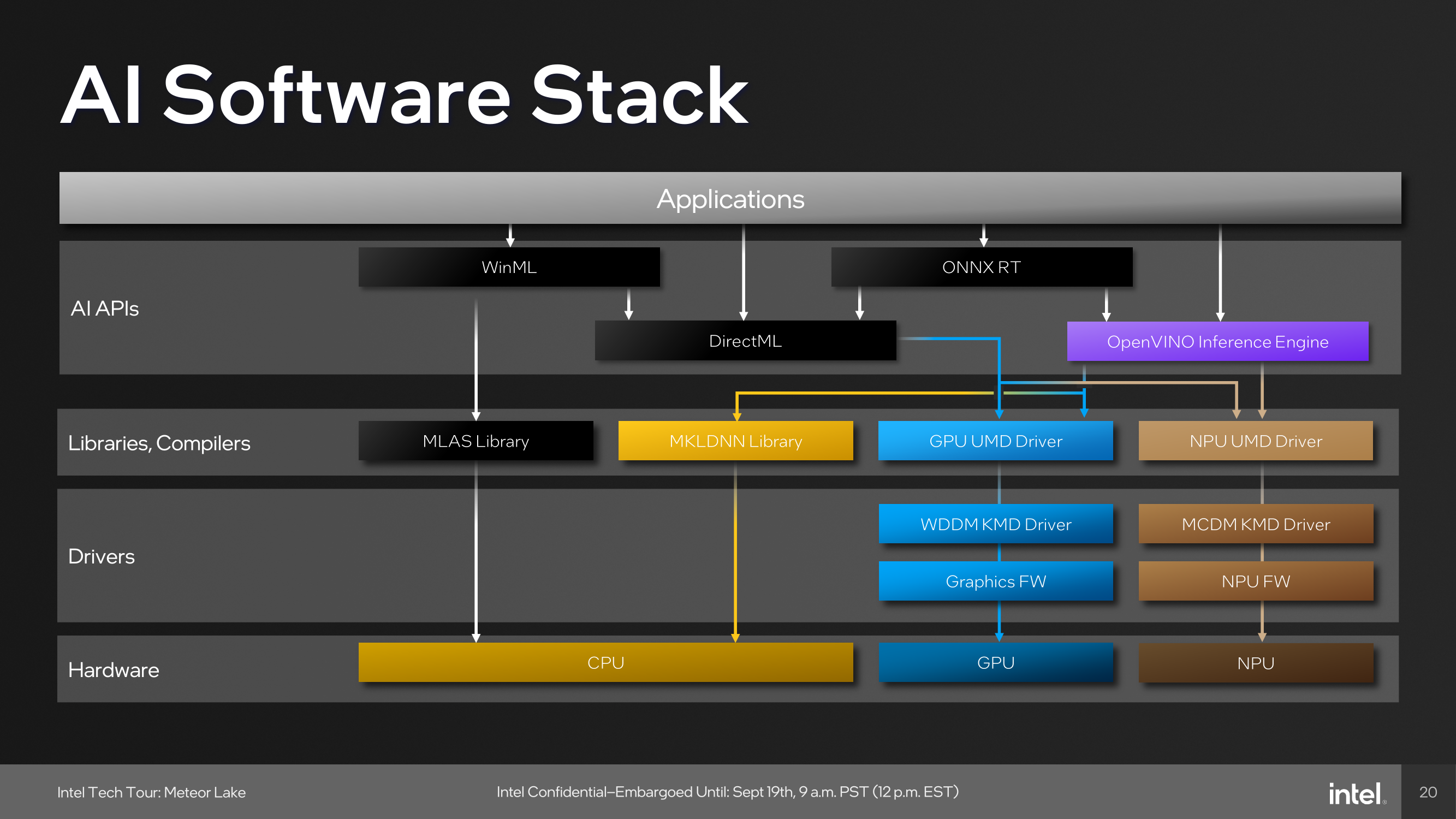
Although it did require resources from both the compute and graphics tile, everything was brought together by the NPU, which processes multiple elements to spit out an EDM-flavored track featuring the same vocals. An example of how applications pool together the various tiles include those through WinML, which has been part of Microsoft's operating systems since Windows 10, typically runs workloads with the MLAS library through the CPU, while those going through DirectML are utilized by both the CPU and GPU.
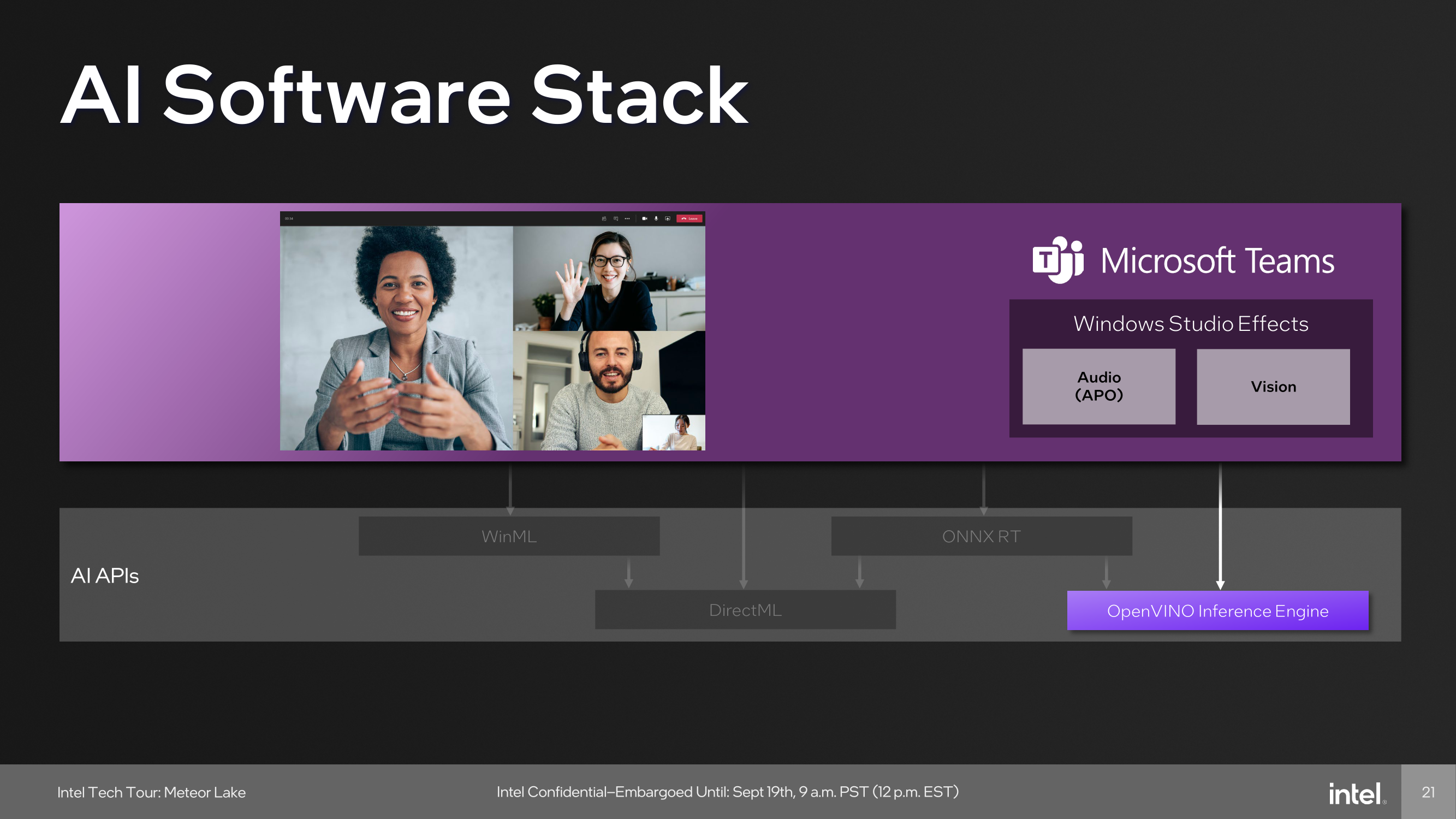
Other developers include Microsoft, which uses the capability of the NPU in tandem with the OpenVINO inferencing engine to provide cool features like speech-to-text transcripts of meetings, audio improvements such as suppressing background noise, and even enhancing backgrounds and focusing capabilities. Another big gun using AI and is supported through the NPU is Adobe, which adds a host of features for adopters of Adobe Creative applications use. These features include generative AI capabilities, including photo manipulative techniques in Photoshop such as refining hair, editing elements, and neural filters; there's a lot going on.








107 Comments
View All Comments
PeachNCream - Thursday, September 21, 2023 - link
Nice trolling lemur! You landed like an entire page of nerd rage this time. You're a credit to your profession and if I could give you an award for whipping dead website readers into a frenzy (including regulars who have seen you do this for years now) I would. Congrats! 10/10 would enjoy again.IUU - Thursday, September 28, 2023 - link
Intel does not need to do anything about its architecture to to match or surpass m3. It just needs to build its cpus on a similar node. Which is not happening anytime soon, thus perpetuating the illusion of efficiency of apple cpus.Two things more. First it is hilarious to compare the prowess of Intel on designing cpus to that of Apple. Apple has long time "building" machines like a glorified Dell borrowing cpus from IBM or Intel and only recently understood the scale and effort needed to design your silicon by improving on ARM designs.
Secondly, it is misguided to say that if a cpu needs 10 times more wattage on the same node to achieve 2 or 3 times the performance is less efficient. This is not how physics works . If Intel built their cpus on N3 of tsmc they would be 2 or 3 times faster best case scenario. Wattage does not scale linearly with performance. This is the same as saying that a car that has 10 times the power would be 10 times faster. Lololol.
Apple designs good cpus recently , but all the hype about its efficiency is just hype. Even if we assume the design is totally coming from Apple , which it doe not, being a very good modification at best, it does not even build its nodes. By large its efficiency is TSMC efficiency. If it were not for TSMC Apple would be non existent on the performance charts.
Silma - Tuesday, September 19, 2023 - link
TLDR:- Intel 4 < TSMC N6
- To not be late, Intel 3 must arrive within 3 months,which is highly doubtful, since Intel 4 isn't even shipping yet
- I assume Intel 3 < TSMC N6, otherwise, why bother enriching the competition?
- Parts of the new tech stack looks promising, but Intel refrains from any real performance claims, or any comparison with offerings from AMD or Apple.
- Did Intel announce another architecture for desktop computers, probably more similar to that of AMD, e.g. perhaps many performance tiles plus one cache tile?
Drumsticks - Tuesday, September 19, 2023 - link
Maybe. Or maybe TSMC6 is cheaper, and Intel doesn't need the power savings or area savings of I4 over TSMC6 for what the non-compute tiles need to accomplish. It's not exactly uncommon to see the SoC / IO tile on a lower node, doesn't AMD do the same thing?Roy2002 - Tuesday, September 19, 2023 - link
Intel 4 and 3 are basically the same with the same device density as 3 is enhanced 4. I assume it has slightly higher density value than TSMC 5nm and performance is slightly better. Let's see.kwohlt - Tuesday, September 19, 2023 - link
Intel 4 is not library complete. It can't be used for the SoC tile.sutamatamasu - Tuesday, September 19, 2023 - link
I wonder if current processor have an dedicated NPU, then what the heck happen with GNA?It still in there or they're remove it?
Exotica - Tuesday, September 19, 2023 - link
Intel should've either implemented TB5 in Meteor Lake or waited until after Meteor Lake shipped to announce TB5. Because as cool and impressive as meteor lake seems, for some of us, it's already obsolete in that it makes no sense to buy a TB4 laptop/PC and instead wait on TB5 silicon to hit the market.FWhitTrampoline - Tuesday, September 19, 2023 - link
Why use TB4 or USB4/40Gbs and have to deal with the extra latency and bandwidth robbing overhead compared to PCI-SIG's OCuLink that's just pure PCIe signalling delivered over an external OCuLink Cable. OCuLink and PCIe requires no extra protocol encapsulation and encoding/decoding steps at the PCIe link stage so that's lower latency there compared to USB4/TB4 and later generations that have to have extra encoding/decoding of any PCIe protocol packets to send that out over TB4/USB4. And for external GPUs 4 lanes of PCIe 4.0 connectivity can provide up to 64Gbs of bandwidth over an OCuLink port/cable and OCuLonk ports can be 8 PCIe lanes and wider there.Once can obtain an M.2/NVMe slot to OCuLink adapter and get an external OCuLink connection of up to 64Gbs as long as the M.2 is 4, PCIe 4.0 lanes wide and no specialized controller chip required on the MB to drive that. And GPD on their Handhelds offers a dedicated OCuLiink port and an external portable eGPU that supports OCuLink or USB4/40Gbs-TB interfacing. TB5 and USB4-V2 will take years to be adopted whereas OCuLink is just PCIe 3.0/4.0 there delivered over an external cable.
Exotica - Tuesday, September 19, 2023 - link
Unlike thunderbolt, Occulink doesn't have hotplugging, meaning your device must be connected at cold boot. Not so good for external storage needs.