Intel Unveils Meteor Lake Architecture: Intel 4 Heralds the Disaggregated Future of Mobile CPUs
by Gavin Bonshor on September 19, 2023 11:35 AM ESTSoC Tile, Part 2: NPU Adds a Physical AI Engine
The last major block on the SoC tile is a full-featured Neural Processing Unit (NPU), a first for Intel's client-focused processors. The NPU brings AI capabilities directly to the chip and is compatible with standardized program interfaces like OpenVINO. The architecture of the NPU itself is multi-engine in nature, which is comprised of two neural compute engines that can either collaborate on a single task or operate independently. This flexibility is crucial for diverse workloads and potentially benefits future workloads that haven't yet been optimized for AI situations or are in the process of being developed. Two primary components of these neural compute engines stand out: the Inference Pipeline and the SHAVE DSP.

The Inference Pipeline is primarily responsible for executing workloads in neural network execution. It minimizes data movement and focuses on fixed-function operations for tasks that require high computational power. The pipeline comprises a sizable array of Multiply Accumulate (MAC) units, an activation function block, and a data conversion block. In essence, the inference pipeline is a dedicated block optimized for ultra-dense matrix math.
The SHAVE DSP, or Streaming Hybrid Architecture Vector Engine, is designed specifically for AI applications and workloads. It has the capability to be pipelined along with the Inference Pipeline and the Direct Memory Access (DMA) engine, thereby enabling parallel computing on the NPU to improve overall performance. The DMA Engine is designed to efficiently manage data movement, contributing to the system's overall performance.
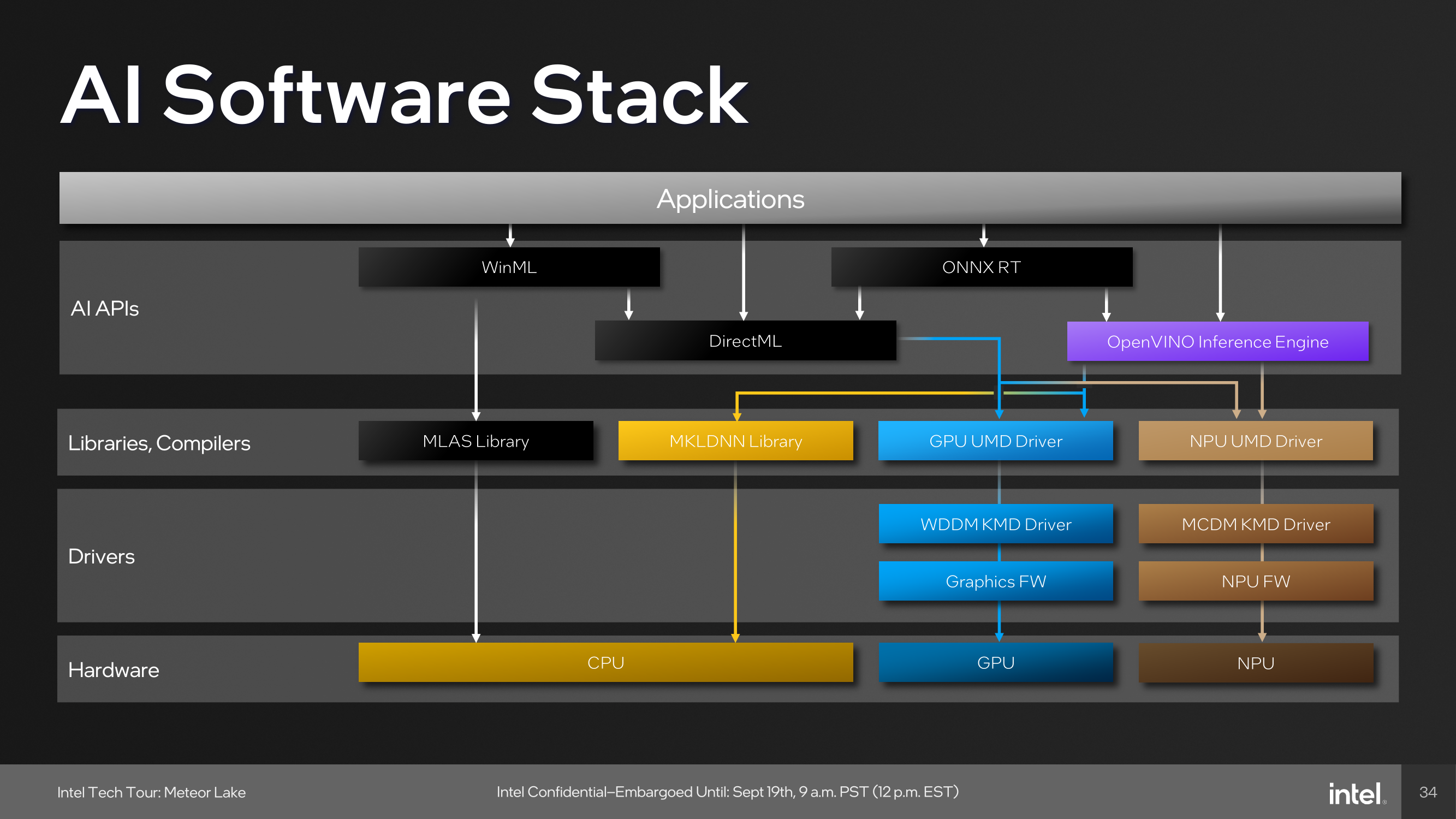
At the heart of device management, the NPU is designed to be fully compatible with Microsoft's new compute driver model, known as MCDM. This isn't merely a feature, but it's an optimized implementation with a strong emphasis on security. The Memory Management Unit (MMU) complements this by offering multi-context isolation and facilitates rapid and power-efficient transitions between different power states and workloads.

As part of building an ecosystem that can capitalize on Intel's NPU, they have been embracing developers with a number of tools. One of these is the open-source OpenVINO toolkit, which supports various models such as TensorFlow, PyTorch, and Caffe. Supported APIs include Windows Machine Learning (WinML), which also includes the DirectML component of the library, the ONNX Runtime accelerator, and OpenVINO.
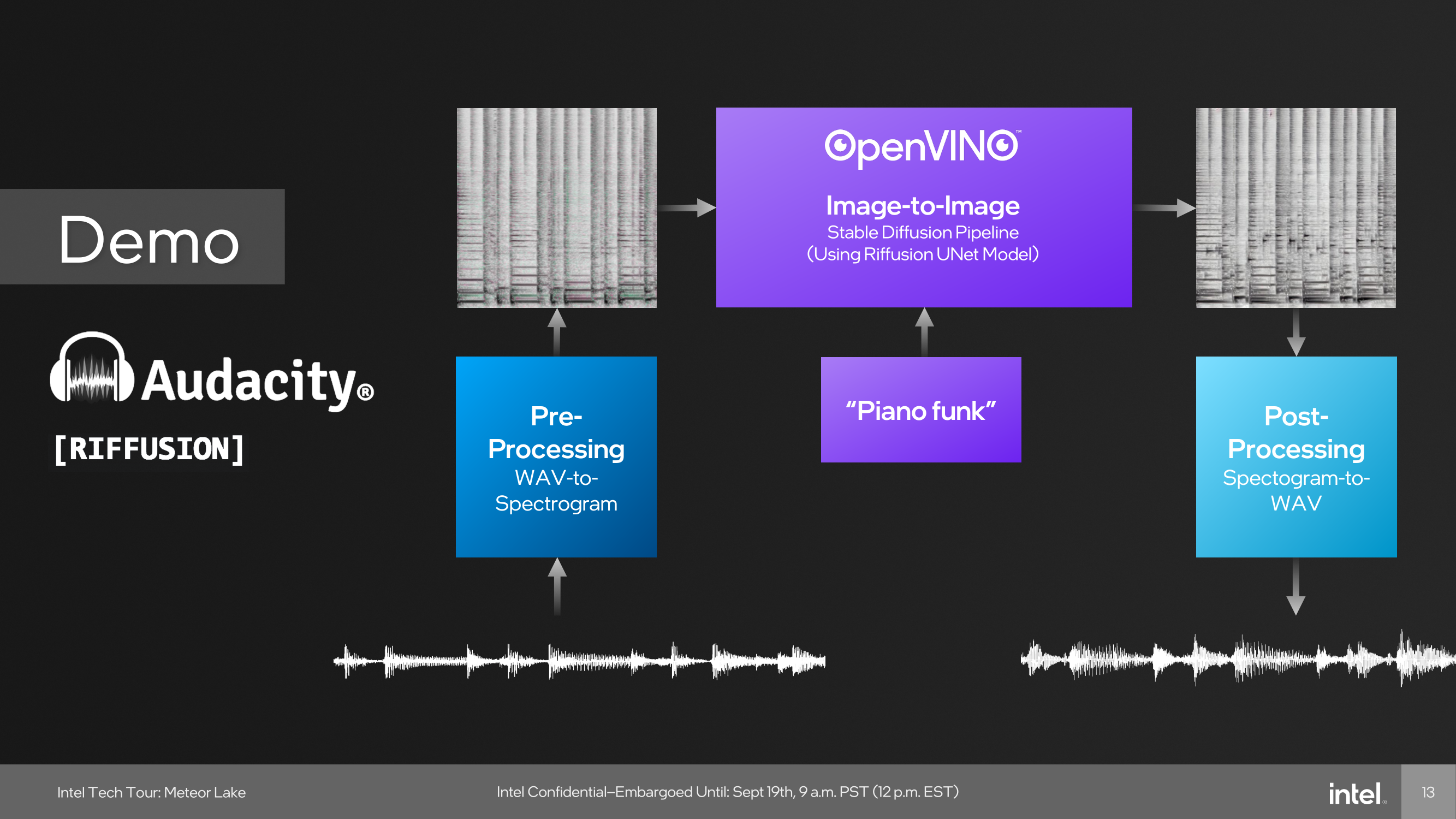
One example of the capabilities of the NPU was provided through a demo using Audacity during Intel's Tech Tour in Penang, Malaysia. During this live demo, Intel Fellow Tom Peterson, used Audacity to showcase a new plugin called Riffusion. This fed a funky audio track with vocals through Audacity and separated the audio tracks into two, vocals and music. Using the Riffusion plugin to separate the tracks, Tom Peterson was then able to change the style of the music audio track to a dance track.
The Riffusion plugin for Audacity uses Stable Diffusion, which is an open-source AI model that traditionally generates images from text. Riffusion goes one step further by generating images of spectrograms, which can then be converted into audio. We touch on Riffusion and Stable Diffusion because this was Intel's primary showcase of the NPU during Intel's Tech Tour 2023 in Penang, Malaysia.
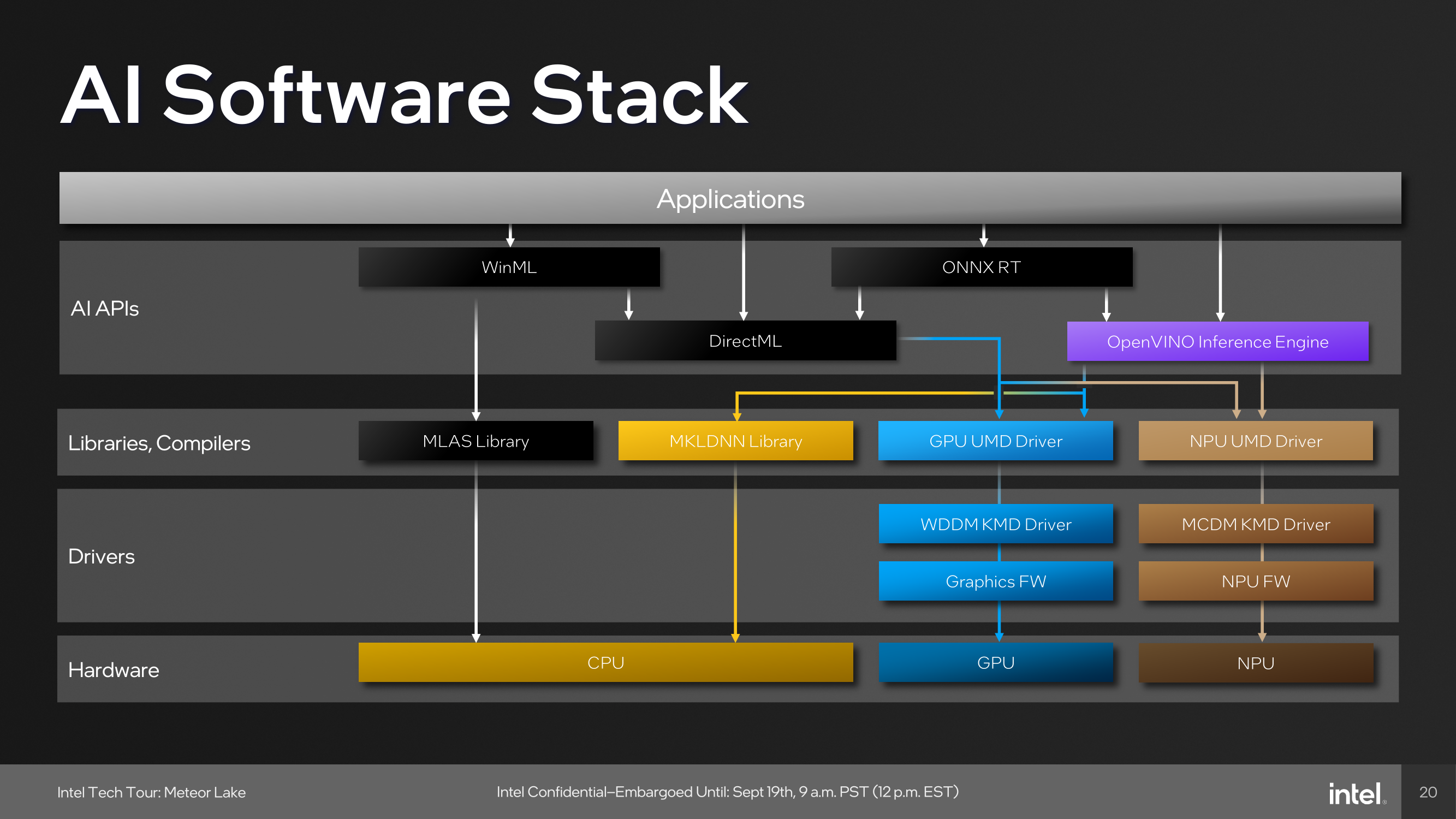
Although it did require resources from both the compute and graphics tile, everything was brought together by the NPU, which processes multiple elements to spit out an EDM-flavored track featuring the same vocals. An example of how applications pool together the various tiles include those through WinML, which has been part of Microsoft's operating systems since Windows 10, typically runs workloads with the MLAS library through the CPU, while those going through DirectML are utilized by both the CPU and GPU.
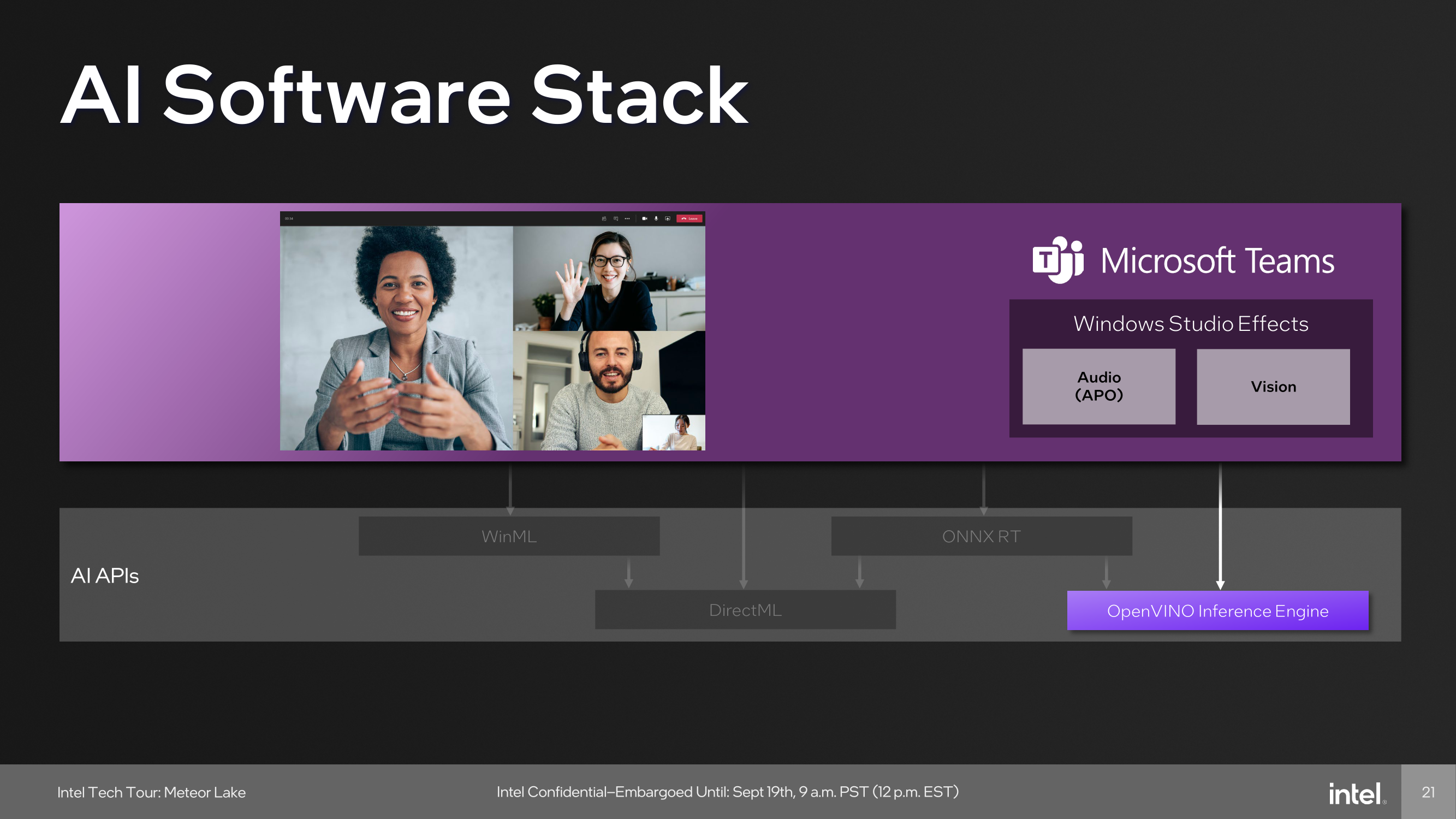
Other developers include Microsoft, which uses the capability of the NPU in tandem with the OpenVINO inferencing engine to provide cool features like speech-to-text transcripts of meetings, audio improvements such as suppressing background noise, and even enhancing backgrounds and focusing capabilities. Another big gun using AI and is supported through the NPU is Adobe, which adds a host of features for adopters of Adobe Creative applications use. These features include generative AI capabilities, including photo manipulative techniques in Photoshop such as refining hair, editing elements, and neural filters; there's a lot going on.








107 Comments
View All Comments
Orfosaurio - Saturday, September 23, 2023 - link
Please, answer why. I have detected at least some "bias", but why you said that he is a liar?KPOM - Tuesday, September 19, 2023 - link
It does seem that the N3B process isn’t yielding great efficiency improvements. Any chance Apple will be paying a visit to Intel Foundries in the near future? A19 or A20 on Intel 20A?tipoo - Tuesday, September 19, 2023 - link
I'd say there's a real chance as they expect a density crossover in 2025lemurbutton - Tuesday, September 19, 2023 - link
My M1 draws 0.2w - 5w during Geekbench ST. A17 Pro is going to draw considerably less.dontlistentome - Wednesday, September 20, 2023 - link
Good to see the RDF is still alive and strong. Guess we are getting closer to Halloween.tipoo - Wednesday, September 20, 2023 - link
That's weird because the lower power A17 draws up to 14W on app launch, and those numbers are not remotely true for M1. It's impressive compared to high power x86 CPUs, but those numbers just aren't right.lemurbutton - Thursday, September 21, 2023 - link
It's true. Anyone with an M1 can prove it. Run GB5 and open powermetrics in the terminal. It's easy to verify.Orfosaurio - Saturday, September 23, 2023 - link
Have multiple sources verified that peak power draw?bji - Tuesday, September 19, 2023 - link
Off-topic. Just go away please.danielzhang - Thursday, September 21, 2023 - link
You need to rethink.This is stupid comparion and hilarious conclusion.First of all, Geekbench cannot fully reflect x86 performance, you should compare R23 with m2 max and 13900H, the full load efficiency is actually similar.
Second, you exaggerate the efficiency gap by comparing a low powered designed mobile phone soc with desktop chip, intel has low power 15W chips like i7 1335u has great single thread performance as well.
At full load, there is efficiency gap but the gap is not big at full load but at light load, apple leads probably 1.5x.