Arm Announces Mobile Armv9 CPU Microarchitectures: Cortex-X2, Cortex-A710 & Cortex-A510
by Andrei Frumusanu on May 25, 2021 9:00 AM EST- Posted in
- SoCs
- CPUs
- Arm
- Smartphones
- Mobile
- Cortex
- ARMv9
- Cortex-X2
- Cortex-A710
- Cortex-A510
The Cortex-A510: Brand-new Little Design Comes in Pairs
Moving on from the larger cores, this year we also have the pleasure to cover Arm’s newest little core, the new Cortex-A510. The new design if a clean-sheet microarchitecture from Arm’s Cambridge team which the engineers had been working on the past 4 years, and marks a quite different approach when it comes to how the little cores are built into the SoC.

First of all, Arm made explicit note of the design’s continued use of an in-order execution flow, mentioning that in their view that this is still the most power-efficient way to design a core for such workloads. This remains a relatively controversial topic and point of discussion when put into context of Apple’s own out-of-order efficiency cores, a topic I’ll return on later.
Secondly, the Cortex-A510 introduces something called a “merged-core” microarchitecture, there’s some very high-level comparisons and similarities to what AMD had done with CMT in their Bulldozer cores a decade ago, but differs quite significantly in some important aspects in terms of the details and design.
Of course, like the X2 and A710, the A510 is an Armv9 design, and all three cores share the same architectural features with each other, allowing them to be integrated together into the same SoC. It’s to be noted that the A510, much like the X2, is a 64-bit only AArch64 core.

The most interesting aspect of the Cortex-A510 is the new merged-core approach. What Arm is doing here, is creating a new “complex” of up to two core pairs, which share the L2 cache system as well as the FP/NEON/SVE pipelines between them.
At first glance this will sound extremely similar to what AMD had done with Bulldozer and the CMT (Clustered Multithreading) approach, however Arm’s design is much more disaggregated in terms of what the actual cores are sharing. While AMD’s CMT module consisted essentially of a shared front-end between two integer back-ends and a single FP/SIMD back-end, Arm’s “merged cores” are actually full cores with their individual front-ends, mid-core, integer back-ends, and L1 cache hierarchies. The only thing being shared between the “cores” is the actual FP/SIMD back-end, as well as the L2 cache hierarchy.
Furthermore, while in the mobile market we expect vendors to use this new two merged cores per complex approach, it’s actually possible to simply just have a single core per complex. In which case the solo core would essentially have its own dedicated (non-shared) resources, but would be notably less area efficient than the intended merged core approach.
Generally, given the adoption of SVE2 and the relatively larger area footprint that the new execution backend requires, it makes sense to actually share these resources for these tiny new cores. Their typical workloads are also mostly only integer-bound background workloads which put less pressure on such units.
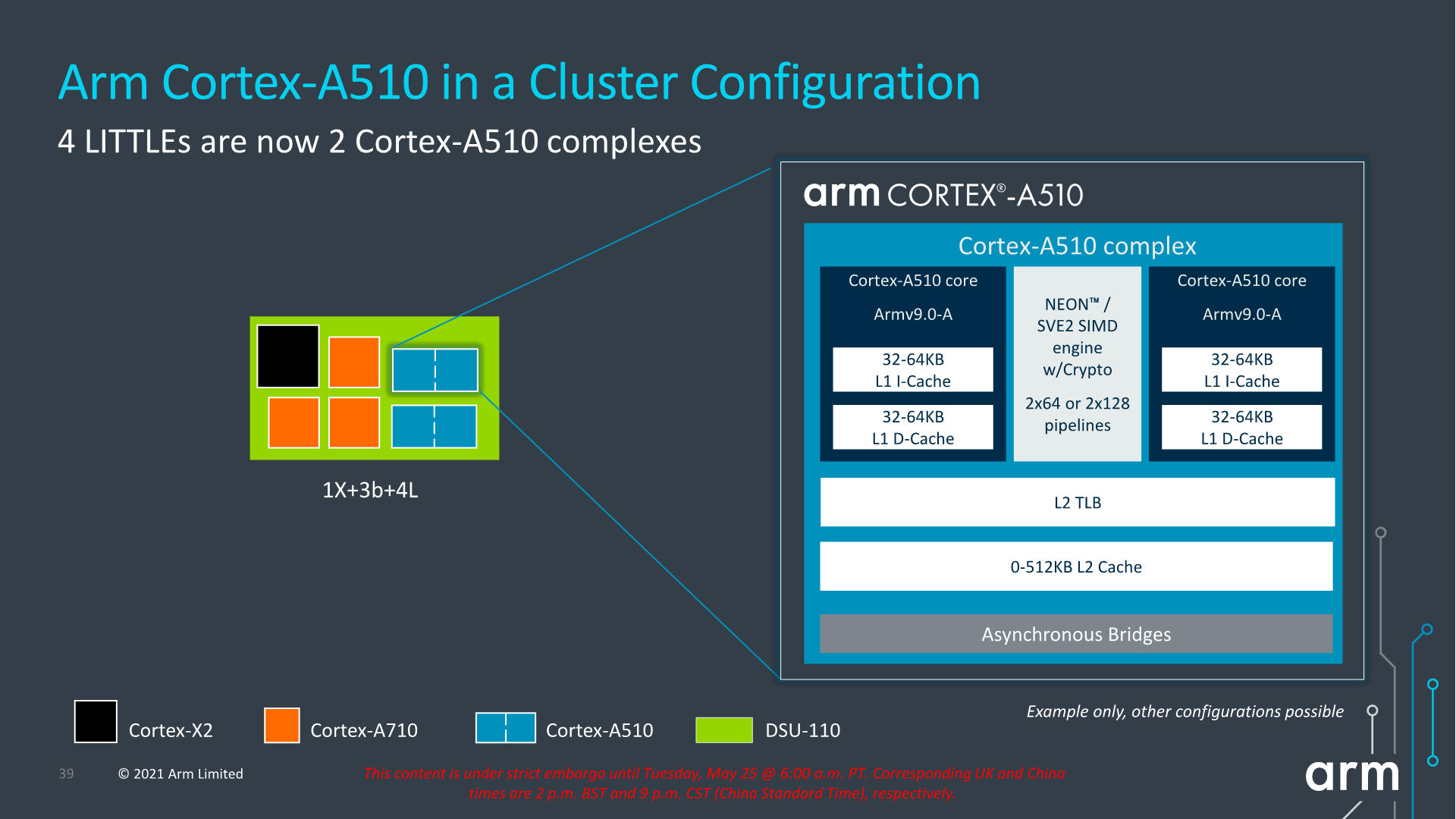
From a higher-level SoC standpoint, nothing really changes when it comes to the core-count, with the details being that we’ll be seeing two pairs or little cores now share a larger L2 cache between each other. This L2 can be configured up to 512KB, but as always, what we’ll actually see in products will very much depend on what vendors will want to implement into their designs. Because the new complex also only takes up a single interface on the DSU, it also opens up the possibility of designs larger than 8 “cores”, something I hope won’t happen, or hopefully only happens through more middle or big cores.

In terms of the front-end of the new A510, we’re seeing a 128-bit fetch pipeline which means it can fetch up to 4 instructions per cycle, giving the front-end a bit of leeway to close branch bubbles. The actual width of the decoder has increased from 2-wide to 3-wide.
In terms of branch prediction, as always Arm doesn’t disclose too many details, however the company did note that it used the same state-of-the-art approaches and techniques it uses on its larger cores. The L1 instruction cache can be either 32 or 64KB.

In terms of the shared vector execution back-end, it’s actually quite interesting here as Arm gives the option of either configuring the complex with smaller 2x64-bit pipelines or with 2x128b pipelines, the latter whose throughput would be 2x that of a Cortex-A55. I’m not too sure what mobile vendors will go with; we always hope for the larger configuration but as always, we’ll have to wait and see what will be employed in the actual products. In both configurations, the vector length is 128b as that’s the requirements for interoperability for the larger core microarchitectures.
Arm states that the shared pipelines are completely transparent to hardware, and that it’s also using fine-grained hardware scheduling. In actual multi-threaded workloads using both cores, the performance impact and deficit is said to only a few percent versus having a pipeline dedicated for each core. This is basically the cornerstone argument for why Arm has decided to use this more area-efficient merged-core approach.
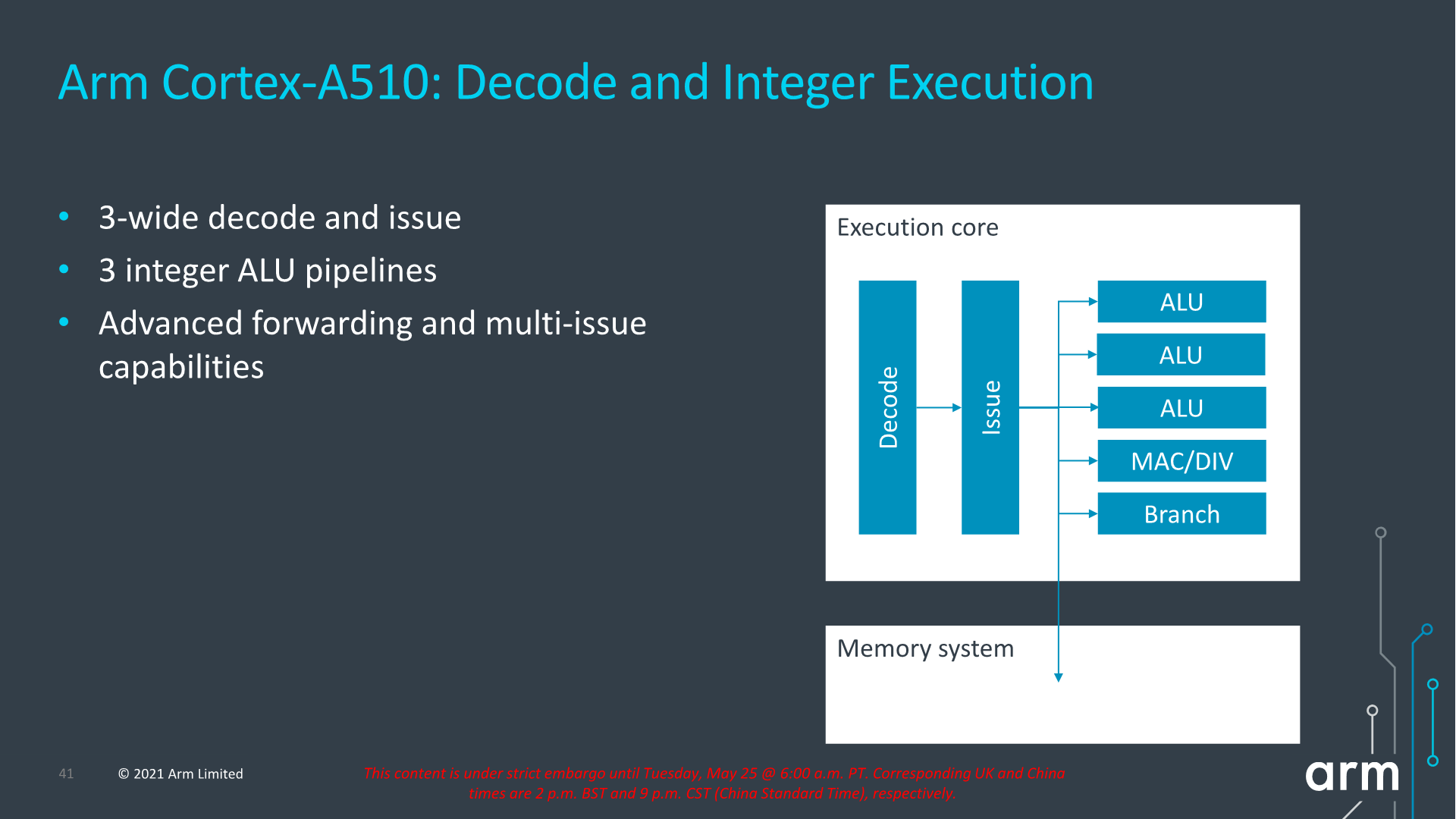
Although it’s an in-order architecture, Arm has still widened the back-end of the Cortex-A510 which now includes 3 ALUs, one complex MAC/DIV unit and a branch forwarding port. The explanation here is simply that there’s more opportunities to execute a wider variety of code blocks in fewer cycles when there’s a fitting sequence of instructions coming in to be executed.
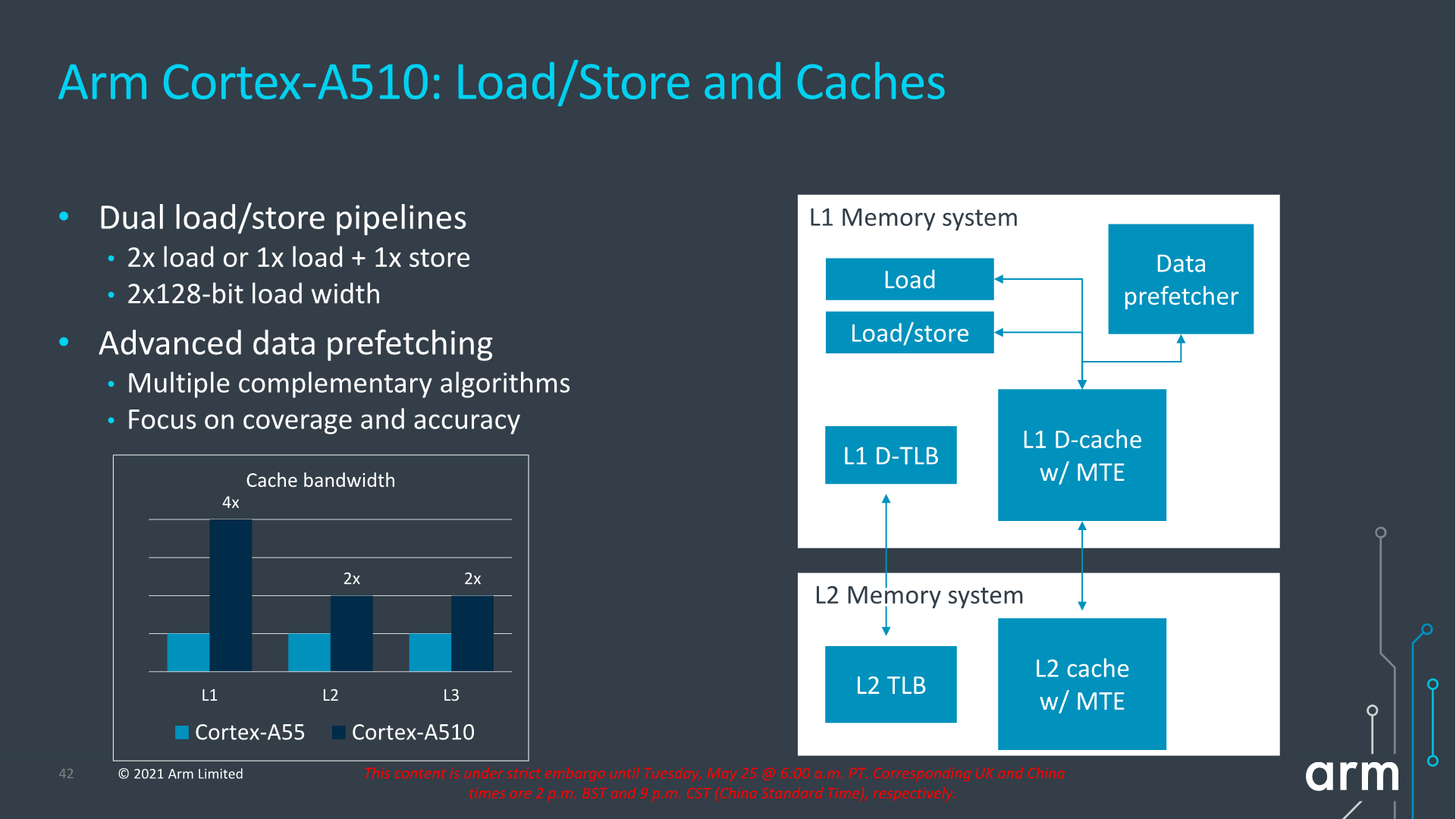
Finally, in the load-store system, the new structure is massively improved in comparison to the Cortex-A55 as we’re seeing a move from a load and store pipeline towards a load and a load/store pipeline, effectively doubling up on the number of loads executed per cycle. The width of the pipelines has also been increased with a doubling from 64b width to 128b width, so essentially load bandwidth compared to the Cortex-A55 is quadrupled.
The A510 also employs the similar very advanced prefetcher designs that we’ve seen in other recent big Arm cores, and adds to the large performance improvements that the core is able to achieve.
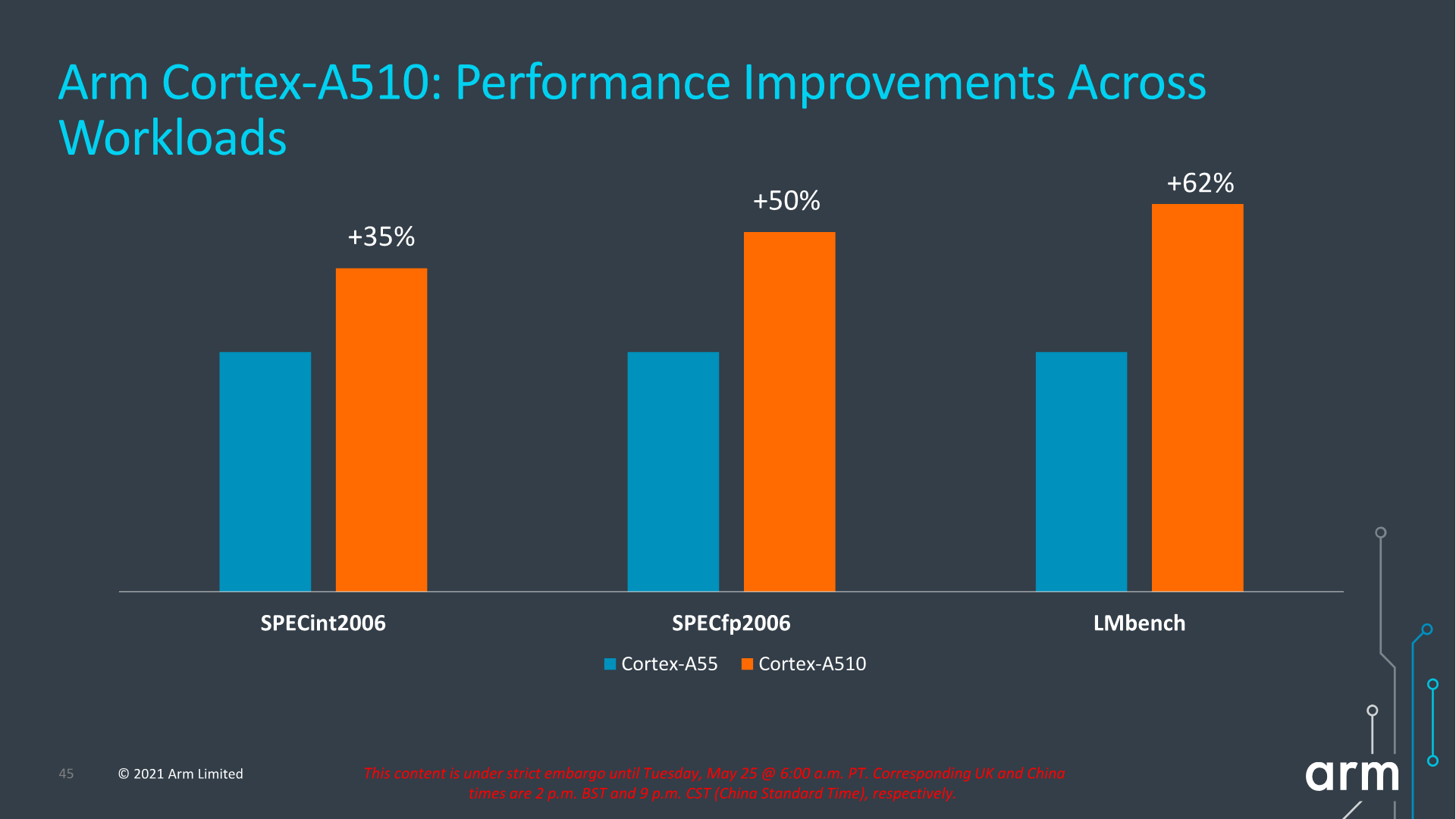
In terms of performance metrics, much like on the X2 and A710 presentation slides, the figures for the A510 aren’t very apples-to-apples as we’re comparing a Cortex-A55 with 32KB L1, 128KB L2 and 4MB L3 versus a Cortex-A510 with 32KB L1, 256KB L2 and 8MB L3. Frequency between the two cores is said to be the same. Under that scenario, we’re seeing +35% in SPECint2006 and +50% in SPECfp2006, which are seemingly very solid generational improvements, however given the cache hierarchy discrepancy as well as the fact that we’re comparing scores to a 4+ year old core, the actual improvements, especially from a compound annual growth rate (CAGR), doesn’t seem to be all that impressive.
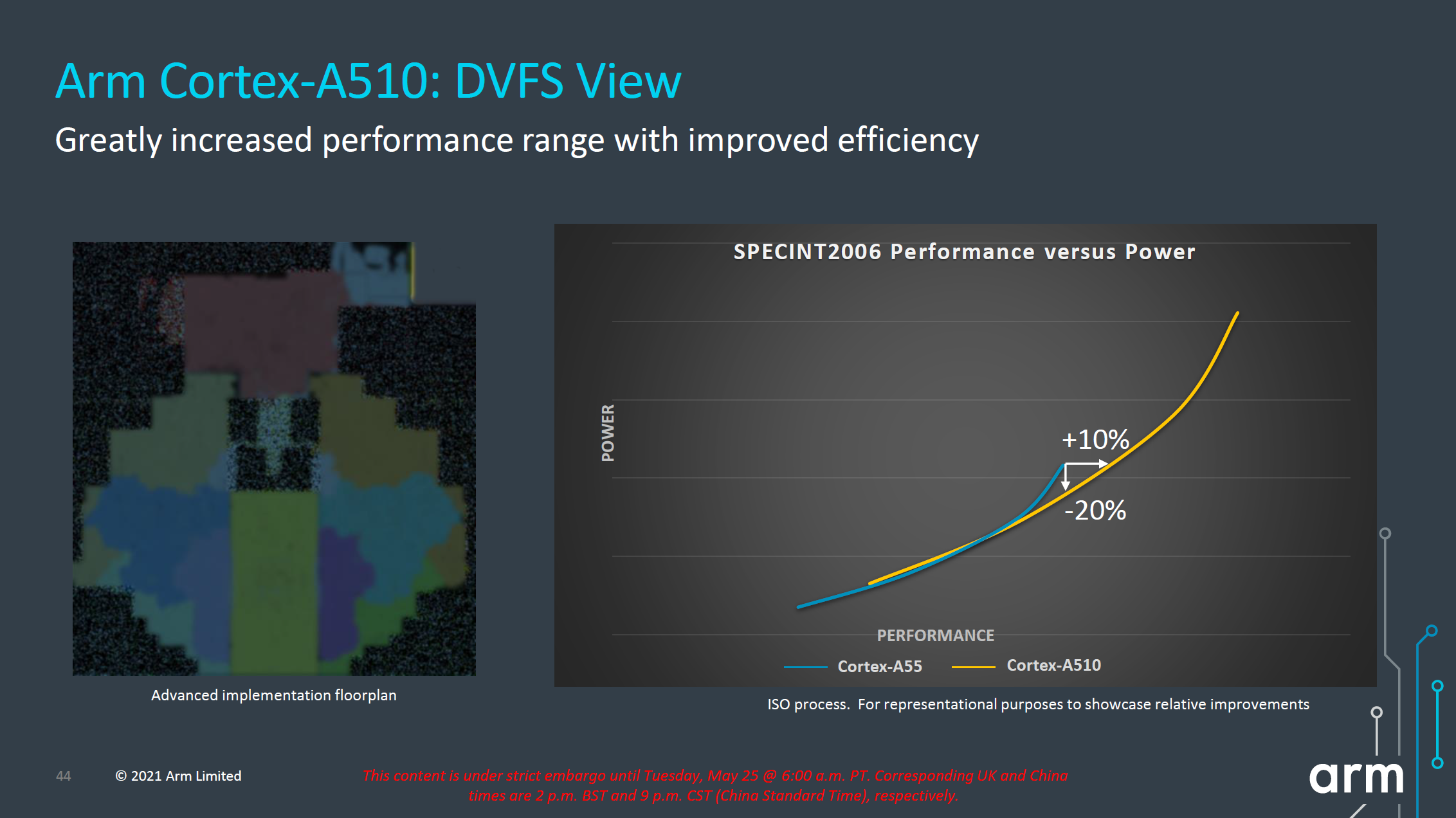
Looking at the projected performance and power curves on an ISO-process comparison, the new A510 seems rather lackluster from an efficiency standpoint. The ISO-power and ISO-performance gains are respectively +10% performance and -20% power, but the latter is really only valid for the high-end of the A55’s frequency curve, all the while the A510 pretty much overlaps the A55’s curve at lower operating points. While the A510 offers overall better performance, this seems to mostly be a product of extending the efficiency curve to higher power levels, and I was frankly disappointed to see this.
We’ll have to wait for the new generation SoCs to actually hit the market for us to test the new A510 cores, but if indeed they come with larger power consumption operating points to achieve higher performance, then Arm won't be much nearer in catching up to what Apple has been doing with their efficiency cores. As of the latest generation of SoCs, Apple’s efficiency cores were around 4x faster than any Cortex-A55 based SoC. Which, running at roughly the same system active power, also made them 3-4x more efficient in the traditional benchmarks. As presented, a theoretical A510 SoC won't be able to close that efficiency gap at all.
Arm is still adamant that for the kind of general use-cases in which the little cores are used in mobile phones – such as very light UI workloads – that their little core approach is still the most power-efficient way to achieve the best “DoU” or days of use figures. This is based in part on their internal projections as well as their partners', all of which indicate that the the triple issue in-order design they've developed is the most efficient option.
As the team explains it, it’s actually extremely hard to reproduce these more real-world workloads in any more structured benchmark (such as the typical test suites we tend to employ), but admitted there’s no real alternative that one could use to isolate performance and efficiency in such tasks. Generally, my counter-argument here is that iPhones still have outstanding battery life, so I’m still extremely skeptical on the whole lower-performance in-order core approach versus a more efficiency focused OOO core as demonstrated by Apple. Especially since we don’t really have an independent way to really test Arm’s claims, and the only data points we do have paint a very different picture.
Arm does note that this generation also had a lot of work done in regards to architectural features, and that the A510 is merely a starting point in a series of generations that are planned to be updated in a more regular fashion versus the large 4–5-year gap we’ve seen with the Cortex-A55 (just to be explicit, Arm doesn’t promise yearly updates, but we’ll be seeing successors in a much faster timeline). Those successors will see continued improvements in performance and power efficiency.
For this upcoming generation, the one benefit of the new little cores will come in more mixed-load workloads. Due to the DVFS nature of the various cores in an SoC, most core groups of a given core type share the same voltage rail and operate at the same frequencies. If there’s a primary thread workload that is resident on the middle cores at higher (less efficient) frequency operating points, any further medium-performance demand secondary threads that in the past couldn’t be serviced by A55 cores would have had to be migrated over to that much less efficient operating point on another middle core. On the A510 with its higher peak performance points, the workload would now be still be resident on the newer little cores, greatly increasing execution efficiency than if they were to be scheduled on the middle cores.
Overall, I’m still feeling a bit underwhelmed by the new A510 core, particularly given the 4 years it took to design it. Let’s hope that the upcoming mobile SoCs will have more apparent efficiency to them when we're testing them in 2022 devices.








181 Comments
View All Comments
Ppietra - Tuesday, May 25, 2021 - link
I believe that he was talking about the overall SPEC2006 score and not just SPECint. Still he would be wrong about the X1 score, which would be 50 and not 40 (probably a typo).Anyway a 16% improvement for X2 over X1 would mean a score of 58 which, like he said, would still be behind the A13 performance core and well behind the 72 score for the A14.
X1 is already being manufactured at 5nm, so it makes no sense to factor in a transition from 7nm.
Wilco1 - Tuesday, May 25, 2021 - link
Cortex-X1 can reach 3.2GHz in Samsung's 5nm process but the power is too high: https://images.anandtech.com/doci/16463/2100-volta...TSMC 5nm is faster and lower power, which allows for higher frequencies. At a conservative 3.3GHz X2 would have a combined score of ~66.7 (only 7% slower than A14).
Ppietra - Tuesday, May 25, 2021 - link
That is not how it works!First of all you have no idea what would be the advantage from using TSMC instead of Samsung, so you are just throwing numbers with no substance. Secondly, X1 energy consumption is already very high (it is less efficient than the A14 Firestorm core), so no, there doesn’t seem to be a lot of room to improve X2 clock speed to 3.3GHz. Thirdly even with your assumption you would still have X2 performing worse than a 1 year old core
Wilco1 - Tuesday, May 25, 2021 - link
We absolutely do know. TSMC 5nm is ~15% faster than 7nm at the same power (or 30% lower power at the same frequency). We know that SD865+ achieves 3.1GHz on 7nm and that the frequency gain from A13 on 7nm to A14 on 5nm was around 13%. So 3.3GHz should be feasible on 5nm without increasing power.The point is that TSMC 5nm will give a significant perf/power boost (that A14 already benefits from). And that means the gap has narrowed to only one generation rather than 2.
melgross - Tuesday, May 25, 2021 - link
It’s not that simple. The cores would require a bit of a redesign for the different process, and each design would fare differently. Some might get a good boost, and others may not.michael2k - Tuesday, May 25, 2021 - link
You're comparing the X2 to the A14? I mean, if we're lucky we will see the X2 in 2022 alongside the A16. The A15 will be released this year, in 2021. We already have some X1 baselines:https://www.anandtech.com/show/16463/snapdragon-88...
So in terms of generation:
2021 X1 not competitive with the 2019 A13 now
2021 X1 competitive with the 2019 A13 on TSMC 5nm
2021 X1 not competitive with the 2021 A15 (est 10% boost to hit 70 SPECint)
2022 X2 competitive with the 2020 A14 on TSMC 5nm
2022 X2 not competitive with the 2021 A15
That still sounds like a 2 generation gap to me. The real problem isn't fundamentally the core, but the OEM choosing not to use a 2x2 design (2 X1 and 2 A77) or (2 X2 and 2 A710), so even if the cores get faster each generation, overall performance is hobbled by using 3 medium cores instead of a pair of higher performance X1 or X2 cores.
Fulljack - Wednesday, May 26, 2021 - link
it's cat and mouse, really. Apple release their phones in late Q3, while Samsung S-series are released in late Q1. there's 5 to 6 month difference.Ppietra - Wednesday, May 26, 2021 - link
Nothing of what you said gives you any data to infer about a transition from Samsung to TSMC.SD865+ does not use a X1 core, as such you have no commonality to make that kind jump in analysis, secondly the X1 core already consumes significantly more than the SD865+ core, so clearly there is no much room to increase clock speed from that perspective. If you want to increase clock speed you need to keep power consumption under control.
Wilco1 - Wednesday, May 26, 2021 - link
These are different generations of the same microarchitecture from the same design team with the same frequency capability (as reported by AnandTech). So yes there is obvious commonality.We also know this microarchitecture is capable of higher frequencies, for example AnandTech reports Cortex-X1 can reach 3.2GHz. The main problem is power however, which is what limited Cortex-X1 on Samsung's process. TSMC 5nm reduces power by 30% which enables higher clock speeds.
Ppietra - Wednesday, May 26, 2021 - link
actually they aren’t different generations from the same microarchitecture. The next generation for the A77 is the A78. The X1 goes for a bigger core design, and as such consumes more.Being capable of higher frequencies doesn't mean that Qualcomm (, etc) finds it viable to use those higher frequencies in a smartphone SoC...
NODE power reduction is stated for same performance and microarchitecture (which X1 is not) and only as an internal TSMC comparison... The data you give tells you nothing about X1 (already at 5nm) transitioning to TSMC. You are making an analysis based on wrong assumptions.