The Snapdragon 888 vs The Exynos 2100: Cortex-X1 & 5nm - Who Does It Better?
by Andrei Frumusanu on February 8, 2021 3:00 AM EST- Posted in
- Mobile
- Samsung
- Qualcomm
- Smartphones
- SoCs
- Snapdragon 888
- Exynos 2100
SPEC - Single Threaded Performance & Power
Moving onto performance of the new CPU cores, something I’ve actually been quite excited about this generation, particularly because this year we hadn’t been able to do a proper in-depth performance preview of the Snapdragon 888 like we usually do on previous years.
Before we go into the results, I wanted to point out some discrepancies between the Exynos 2100 and Snapdragon 888 Galaxy S21 Ultra devices, particularly regarding clock frequencies under load: I’ve noted that the Exynos 2100 CPUs are extremely prone to throttling, in a quite drastic fashion compared my Snapdragon 888 unit. When tracking the average frequencies under SPEC, benchmarking the Exynos 2100 S21 Ultra under my typical peak performance conditions where I place the phone over a 140mm fan to keep it cool, the X1 cores were still throttling quite significantly even though the phone was only luke-warm.
The following are precise mean frequencies for the SPEC workloads, both under my usual fan-cooled conditions, as well as putting the S21 Ultra in my freezer:
| Cortex-X1 Average Workload Frequency | ||||
| S21 Ultra (Exynos 2100) Fan |
S21 Ultra (Exynos 2100) Freezer |
S21 Ultra (Snapdragon 888) Fan |
||
| 400.perlbench | 2613 | 2845 | 2826 | |
| 401.bzip2 | 2690 | 2904 | 2841 | |
| 403.gcc | 2688 | 2905 | 2839 | |
| 429.mcf | 2744 | 2912 | 2841 | |
| 445.gobmk | 2701 | 2908 | 2841 | |
| 456.hmmer | 2534 | 2752 | 2841 | |
| 458.sjeng | 2684 | 2912 | 2841 | |
| 462.libquantum | 2469 | 2857 | 2841 | |
| 464.h264ref | 2602 | 2901 | 2841 | |
| 471.omnetpp | 2756 | 2912 | 2842 | |
| 473.astar | 2667 | 2909 | 2841 | |
| 483.xalancbmk | 2668 | 2909 | 2841 | |
| 433.milc | 2369 | 2759 | 2842 | |
| 444.namd | 2603 | 2912 | 2841 | |
| 447.dealII | 2721 | 2889 | 2841 | |
| 450.soplex | 2573 | 2883 | 2841 | |
| 453.povray | 2544 | 2769 | 2841 | |
| 470.lbm | 2273 | 2628 | 2812 | |
| 482.sphinx3 | 2437 | 2709 | 2747 | |
The fan-cooled results are quite horrible, with the chip not sustaining the full 2.91GHz for any of the workloads. In this situation, in fact most of the tests barely run at 2912MHz, with most of the time the X1 cores being resident at 2600 or 2496MHz, with many tests going down to 2184MHz for periods of time.
Putting the device in the freezer (with a sock around the bottom part of the phone as to not damage the battery from it getting too cold), resulted in skin temperature hot-spots of around 6 to 10°C. Even under such unrealistic test conditions, the phone wasn’t able to sustain its peak frequency for many workloads, which is quite puzzling and worrying.
This Exynos S21 Ultra unit was quite unlucky in terms of its chip bin as the CPUs received ASV bins of 2, 2, 2 across the little, middle, and big cores. I’ve got another regular Galaxy S21 with another Exynos chip, which had slightly better bins of 4, 4, 3. While this device performed better and was slightly more efficient than the S21 Ultra, it was still significantly worse than the Snapdragon 888 Galaxy S21 Ultra, which had no issues to sustain near its 2841MHz peak frequency for the vast majority of workloads.
The following results are from the freezer-run Exynos S21 Ultra, as we’re attempting to analyse peak performance and the X1 cores themselves as well.
We use SPEC2006 for mobile devices still as it’s still relevant and we have a good understanding of the workloads. The benchmark is deprecated in favour of SPEC2017, which we hope to move to in the coming months. For the Android devices, this data-set is on a new NDK 22 compile as it resolves some performance discrepancies in our past data. We run simple and straightforward -Ofast flags.

In SPECint2006, we can see the new Cortex-X1 cores in both the Snapdragon 888 and Exynos 2100 perform a notch above the previous generation A77-cores, with particularly some larger jumps in tests such as 403.gcc and 464.h264ref.
The Snapdragon 888 in the majority of tests is able to take the lead, even though for the integer benchmarks the Exynos 2100 was mostly able to retain frequencies near 2.9GHz.
Qualcomm’s lower latency memory subsystem, as well as the advantage of the 1MB L2 cache are quite obvious here as it’s able to overcome, and outpace the clock frequency differences.
It’s to be noted that HiSilicon’s Kirin 9000 is still able to keep up with the new chips in quite a few of the workloads – the Kirin’s 3.13GHz clock frequency as well as an outstanding memory subsystem fall in its favour.
In terms of power and efficiency, it’s very obvious that the Exynos 2100 falls behind the Snapdragon 888. The chip uses more power, and it being slower, means it’s also taking up more energy to complete the tasks.
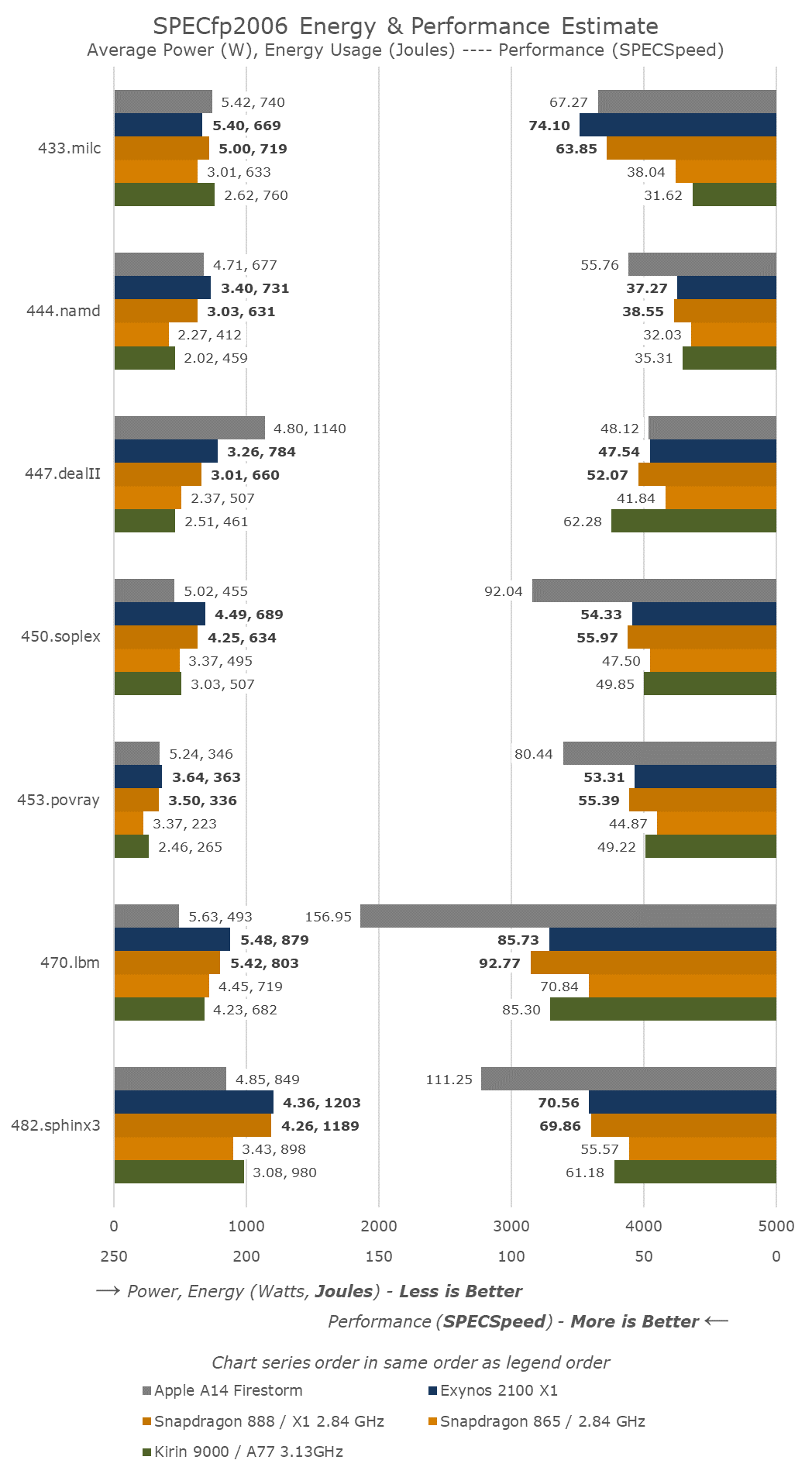
In SPECfp2006, the Exynos 2100 actually manages to score a few wins against the Snapdragon 888, but again falls behind in others as it has to throttle.
In 433.milc, the new X1 chips are posting gargantuan generational performance bumps, but which comes at a cost of power consumption in excess of 5W – whatever Arm did here this generation, it caught up and surpassed Apple in this one test.

For more extensive performance comparisons to past SoCs, such as the Exynos 990 I’ve updated our historical SPEC mobile data-set in the above large graph.
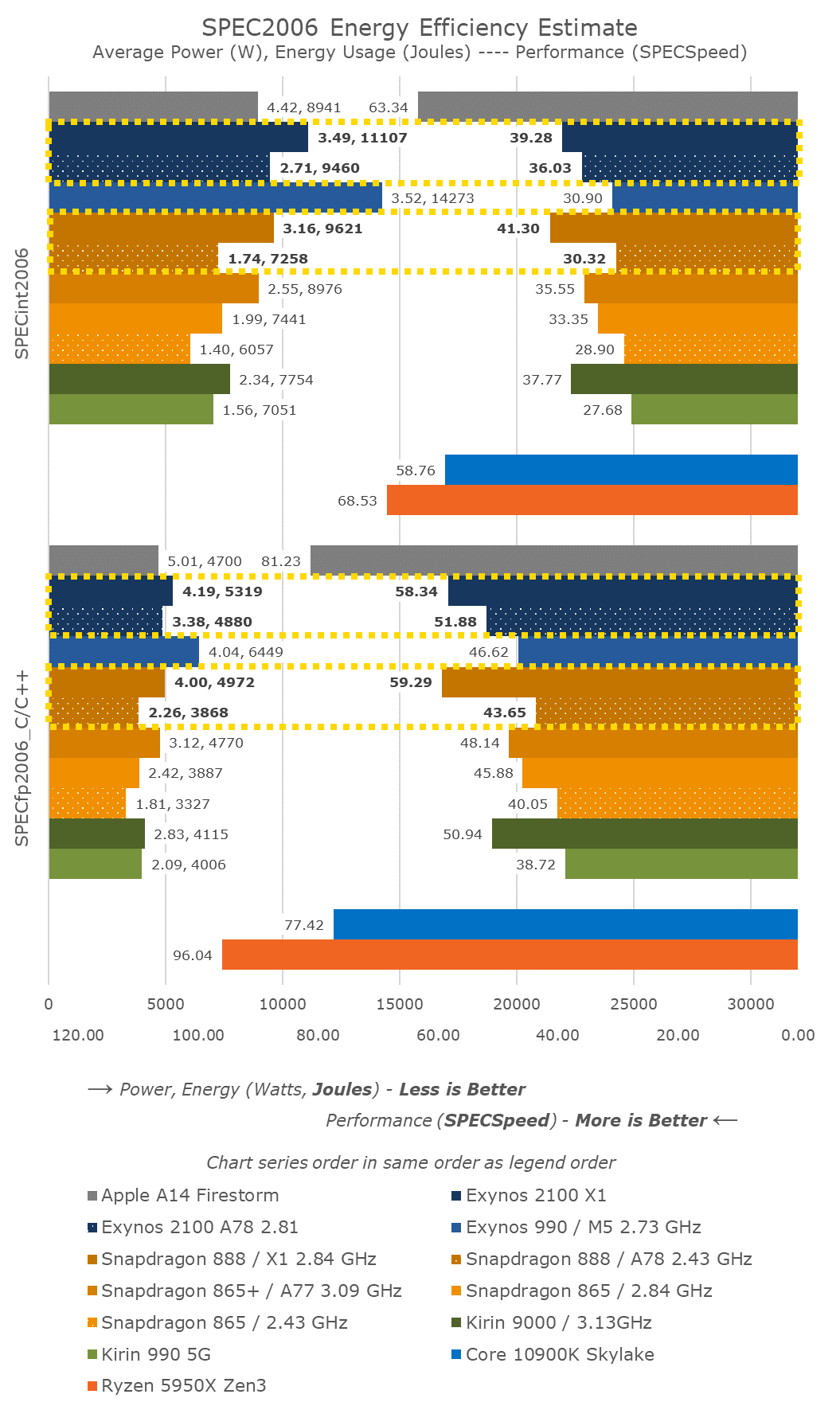
In the aggregate results scores, there’s a multitude of points we need to analyse.
Starting off with the Exynos 2100 – generationally, the new X1 cores and the Exynos 2100 are able to beat the Exynos 990 and the M5 cores by 27% and 25% in the integer and floating-point results. Samsung had officially stated the new SoC would be 19% faster in single-threaded scenarios – which I immediately throught of as suspect, as the improvements should be larger than that. I’m glad that the marketing was overly conservative and that my initial instinct was correct here. Although the X1 cores don’t use much different power consumption compared to the M5 cores, because of their increased performance, they are more energy efficient, using 23% and 18% less energy than the M5.
Looking at those figures though, they seem quite a bit odd, as they’re not that great as we had expected from the X1 cores, especially since this is also on a process node upgrade. Wouldn’t the cancelled M6 cores still have been competitive here?
The Snapdragon 888 results put things into context – it’s 5.1% and 1.6% faster than the Exynos 2100, however it’s also less power hungry, using 10% less power, resulting in being 14% more energy efficient. That’s not a large difference, but still sizeable given it’s the same CPU IP on the same process node.
Against the Snapdragon 865, the Snapdragon 888’s X1 cores are 23.8% and 29.2% faster. Because the cores are clocked at the same frequency, that’s also the generational IPC improvement that we’ve seen out of the new X1 cores. On the floating-point side, that essentially matches Arm’s 30% projection, however on the integer side it’s a few percentage points short – which is reasonable given that Arm’s figures had been projected with an 8MB L3 cache implementations which we didn’t see this generation.
Energy efficiency of the Snapdragon 888 is only slightly worse than that of the Snapdragon 865+, which means that battery life should still be good this generation.
The Cortex-A78 cores of the Snapdragon 888 are 4.9% and 8.9% faster than the Cortex-A77 middle cores of the Snapdragon 865. The power consumption comparison here isn’t apples-to-apples due to the new cores doubling up on the L2 cache. Arm states the A78 has an +7% IPC improvement and a -4% power reduction versus the A77. The Snapdragon 888’s middle cores however use +24% more power. Excluding the theory that that doubled L2 cache significantly raises power, we’re probably still seeing a notable process node power efficiency difference between Samsung’s 5LPE node and TSMC’s N7P node, with the Samsung node still falling behind.
This power efficiency difference can also be seen in the Cortex-A78 cores of the Exynos 2100. At 2.81GHz, they’re near the 2.84GHz A77 cores of the Snapdragon 865 – both having 512KB L2 caches. The Exynos’ middle cores here actually outperform the previous Snapdragon’s performance cores by 8 and 13%, they however use 35% more power to do so, which is a whole damn lot. In fact, the throttling behaviour on the Exynos wasn’t just limited to the X1 cores, as under normal conditions even these middle A78 cores had to ramp down from their peak frequencies.
This behaviour of these new designs using quite large amounts of power at these higher frequencies, however being seemingly similar power to TSMC’s process nodes at lower frequencies, points out to me that the 5LPE node has lower performance than TSMC’s N7P node. The fact that the Kirin 9000 here is still competitive in terms of performance, but at significant lower power and better energy efficiency, also points out that the N5 node is well superior to Samsung’s offering.
Generally, we can’t do much about the process – especially if TSMC isn’t able to produce enough volume to satisfy both Apple as well as Qualcomm at the same time. Today’s performance and efficiency figures also fell below our projected targets of the X1 cores. Lower frequencies and smaller caches are primary reasons as to why. I find it weird from both Qualcomm as well as SLSI to have employed 4MB L3 caches. SLSI has in the last few years wasted a ton of silicon on their custom cores, so them skimping out even on the L2 cache here on the X1 is a really weird change of philosophy. Qualcomm did a better job, but also not as aggressive as you’d expect from a company which wants to acquire Nuvia in order to strengthen their CPU portfolio.








123 Comments
View All Comments
serendip - Monday, February 8, 2021 - link
I'm interested in what this means for the SD8cx successor. A 30% increase from using one or two X1 cores would be great, I'm using the SQ2 chip and that's fast enough for typical office tasks. That's still not enough to get within striking range of the M1 or even A14. What the heck is in those Firestorms that makes them so fast?On memory subsystems, what are Qualcomm and Samsung doing wrong compared to Apple and HiSilicon? The M1's memory bandwidth is astonishingly high but that's from using custom parts. HiSilicon is doing a great job using standard ARM interconnects.
Agreed on the stupidly high GPU clocking. The SQ2 has a beefy GPU that performs well but it can get hot even in a large tablet form factor. It's time to stop the marketing departments from forcing engineers to chase pointless metrics.
ikjadoon - Monday, February 8, 2021 - link
>What the heck is in those Firestorms that makes them so fast?A trifecta that I share with people because this question comes up so often.
Technical Part 1: https://www.anandtech.com/show/16226/apple-silicon...
Technical Part 2: https://www.anandtech.com/show/16252/mac-mini-appl...
Consumer + Approachable: https://www.youtube.com/watch?v=3SG5e4z-Ygg
Technical Background + More Approachable: https://www.youtube.com/watch?v=cAjarAgf0nI
As Upscaled wrote, "It's not magic. It's good design." And why don't AMD / Intel have these same good designs? The videos above give thorough answers. For example, the last link explains why everyone cares Firestorm (A14) and Lightning (A13) have an 8-wide decode, which is one of many major "better designs" versus competing Arm & x86 CPUs.
ikjadoon - Monday, February 8, 2021 - link
Uh, wait. Delete. I definitely skipped too much of that one. What on Earth is he going on about 1T vs 1C?~~ Consumer + Approachable: https://www.youtube.com/watch?v=3SG5e4z-Ygg ~~
Wow, I'm a little stunned at how bad this Upscaled video is. The Dev Doc + AnandTech are much more reliable.
Nicon0s - Monday, February 8, 2021 - link
LoL, Engadget.He keeps saying multithreading when he means SMT or Hyperthreading(Intel's version of SMT).
ikjadoon - Monday, February 8, 2021 - link
Yes! Never mind 1T / 1C have shown negligence IPC differences in general computing. 1% at best. Please go test an i5-8600K vs an i7-8700K: one has SMT, one does not. Terrible to see the WCCFTech disinformation cycle reach a mainstream audience so quickly.https://www.anandtech.com/show/16261/investigating...
And then he, out of left field, throws up a Cinebench multi-core score: "See? Intel and Apple are actually very close to each other." But, his comparison was the 4+4 M1 vs an 8C Intel...
I wish I could edit comments. I give up on consumer YouTube videos; I saw his earlier interview with RISC's founders and it seemed halfway decent. I'm a fool.
Archer_Legend - Tuesday, February 9, 2021 - link
Don't be offended but I think that what you posted is completely bs.First of all you are comparing arm64 cpus and x86 cpus, second the arm 64 cores used by apple are very arguably faster than the x86 cores of for example a ryzen cpu.
The second thing which I would want to point out is that about the widht of the pipeline, it is not that apple is a genious or intel and amd are stupid: the x86 architecture was built to have a narrowish pipeline and do more cycles in fact the width of the pipeline in intel and amd cpus is as wide as it gets.
Arm arch on the other end lets you use a wider pipeline, however saying using a narrower or wider pipeline is better or not is pointless because performance comes down to how you organise the cpu around that specific pipeline so....
leledumbo - Monday, February 8, 2021 - link
> What the heck is in those Firestorms that makes them so fast?The same thing since A9 again (CMIIW): super wide decoder + super big cache. Apple isn't stingy when it comes to die size and Apple SoCs are always bigger than Snapdragon on the same generation and process node. 4mm^2 difference is huge when we're talking at nm level. What's weird, Exynos is even bigger but can't match these two. No idea what Samsung put there.
Santoval - Tuesday, February 9, 2021 - link
"What's weird, Exynos is even bigger but can't match these two. No idea what Samsung put there."This is probably due to TSMC having a *far* denser 5nm process node compared to Samsung's process 5nm node. Per the article below TSMC's 5nm node tops at 173 million transistors per mm^2 while Samsung's 5nm node reaches only 126.5 MTr/mm^2 (i.e. barely denser than TSMC's second gen 7nm+ node) due to much more, er, "conservative" design choices (Samsung basically just switched from DDB cells in 7nm to SDB cells; the article explains what that means).
What is often not clear is that the quoted transistor densities of each process node are always the *maximum* transistor densities, not the actual transistor densities used to fab a die. For instance Intel have three different 10nm node variants with three different densities, a low, mid and high density variant (ranging I believe from ~55 million to ~100 million transistors per mm^2). The last one is the only one that has been widely reported, the other two were intended for the tech savvy press and audience.
Each Intel 10nm die has a mix of all three libraries, but each design is (obviously) *fixed* with a precise mix of the three. The desktop parts always have a higher percentage of low density cells because these need to clock higher, and vice versa for the mobile parts. Mobile phones are efficiency focused, so their SoCs have the highest percentage of the highest density variant of each process node that is possible (without hindering performance too much).
That is an additional reason their clocks top at ~3 GHz. Since the two SoCs of the article are both mobile SoCs of an almost identical design we can assume a roughly equivalent percentage of the highest density cells each process node maxes out at. Thus, if all else was being equal (including the same iGPU) Samsung's SoC would have a roughly ~27% larger die than TSMC's SoC. That must be the main reason Samsung kept the cache sizes of the X1 and the A55 cores low.
Santoval - Tuesday, February 9, 2021 - link
p.s. Sorry, I forgot the link to the article :https://semiwiki.com/semiconductor-manufacturers/s...
Santoval - Tuesday, February 9, 2021 - link
p.s.2 I just noticed that the Snapdragon 888 is also fabbed with Samsung's 5nm node. While that rendered the comparison between the two SoCs in my above comment moot the other things I pointed out might have some "academic" value regarding process nodes (I have no away to delete the comment anyway..).