Arm Announces Mobile Armv9 CPU Microarchitectures: Cortex-X2, Cortex-A710 & Cortex-A510
by Andrei Frumusanu on May 25, 2021 9:00 AM EST- Posted in
- SoCs
- CPUs
- Arm
- Smartphones
- Mobile
- Cortex
- ARMv9
- Cortex-X2
- Cortex-A710
- Cortex-A510
New DSU-110 L3 & Cluster: Massively More Bandwidth
Alongside the new CPU microarchitectures, Arm today is also announcing a new L3 design in the form of the new DSU-110. The “DynamIQ Shared Unit” had been the company’s go-to cluster and “core complex” block ever since it was introduced in 2017 with the Cortex-A75 and Cortex-A55. While we’ve seen small iterative improvements, today’s DSU-110 marks a major change in how the DSU operates and how it promises to scale up in cache size and bandwidth.

The new DSU-110 is a ground-up redesign with an emphasis on more bandwidth and more power efficiency. It continues to be the core building block for all of Arm’s mobile and lower tier market segments.
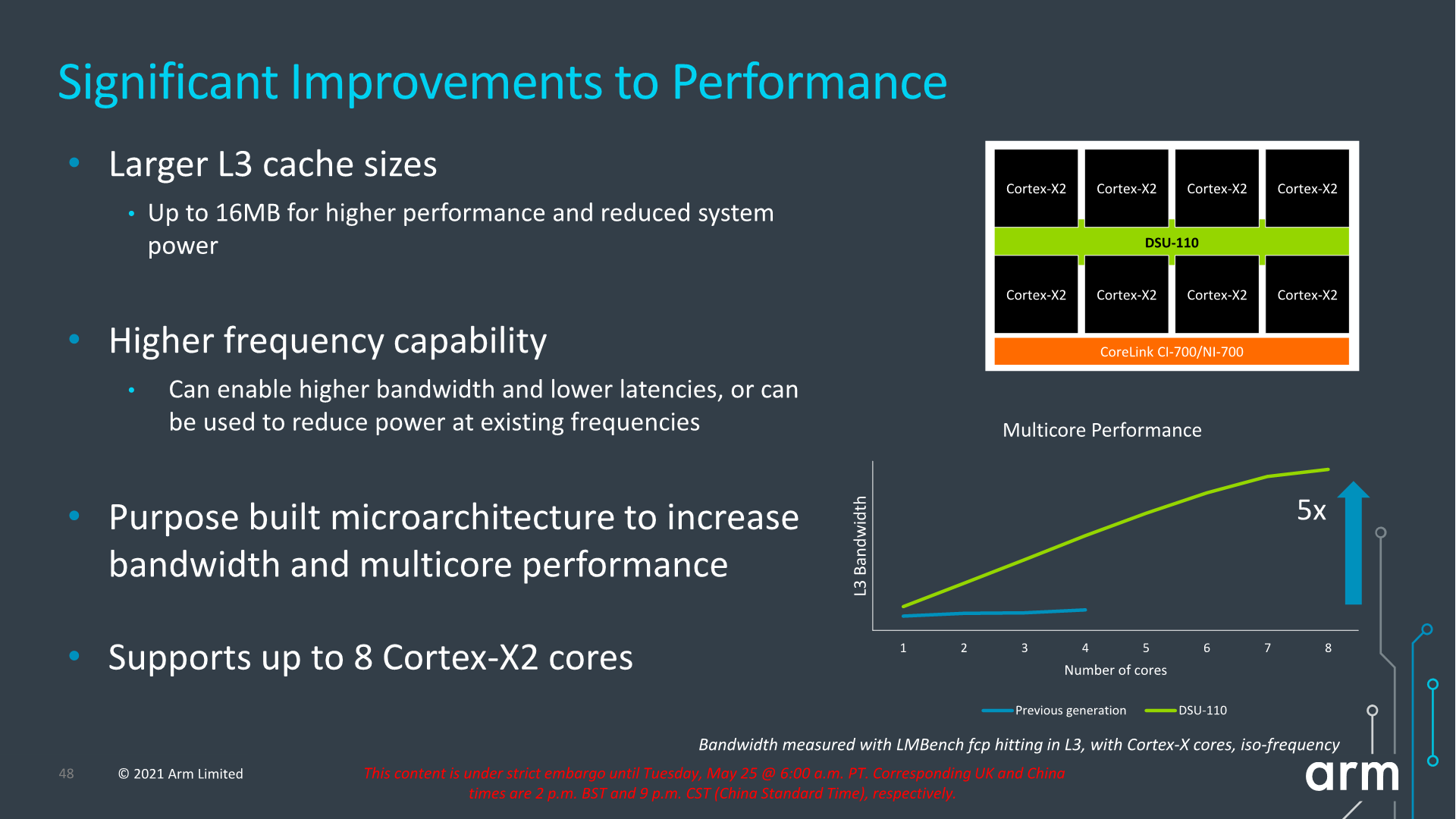
A key metric is of course the increase of L3 cache configuration which will now go up to 16MB this generation. This is of course the high-end of the spectrum and generally we shouldn’t expect such a configuration in a mobile SoC soon, but Arm has had several slides depicting larger form-factor implementations using such a larger design housing up to 8 Cortex-X2 cores. This is undoubtedly extremely interesting for a higher-performance laptop use-case.
The bandwidth increase of the new design is also significant, and applies from single-thread to multi-threaded scenarios. The new DSU-110 promises aggregate bandwidth increases of up to 5x compared to the contemporary design. More interesting is the fact that it also significantly boosts single-core bandwidth, and Arm here actually notes that the new DSU can actually support more bandwidth than what’s actually capable of the new core microarchitectures for the time being.

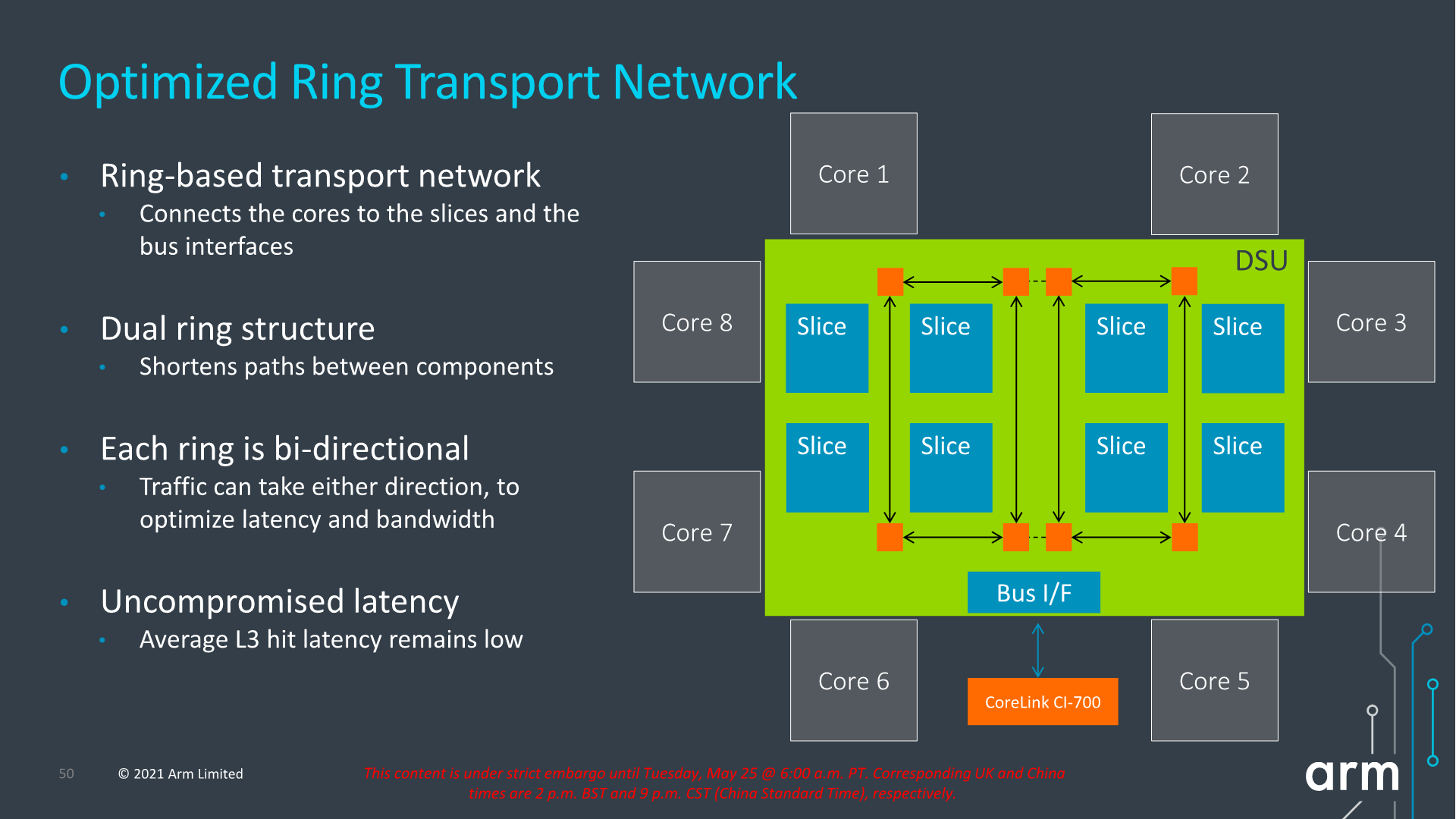
Arm never really disclosed the internal topology of the previous generation DSU, but remarks that with the DSU-110 the company has shifted over to a bi-directional dual-ring transport topology, each with four ring-stops, and now supporting up to 8 cache slices. The dual-ring structure is used to reduce the latencies and hops between ring-stops and in shorten the paths between the cache slices and cores. Arm notes that they’ve tried to retain the same lower access latencies as on the current generation DSU (cache size increases aside), so we should be seeing very similar average latencies between the two generations.
Parallel access increases for bandwidth as well as more outstanding transactions seem to have been also very important in order to improve performance, which seems very exciting for upcoming SoC designs, but also puts into more question the previously presented CPU IPC improvements and exactly how much the new DSU-110 contributes to those numbers.
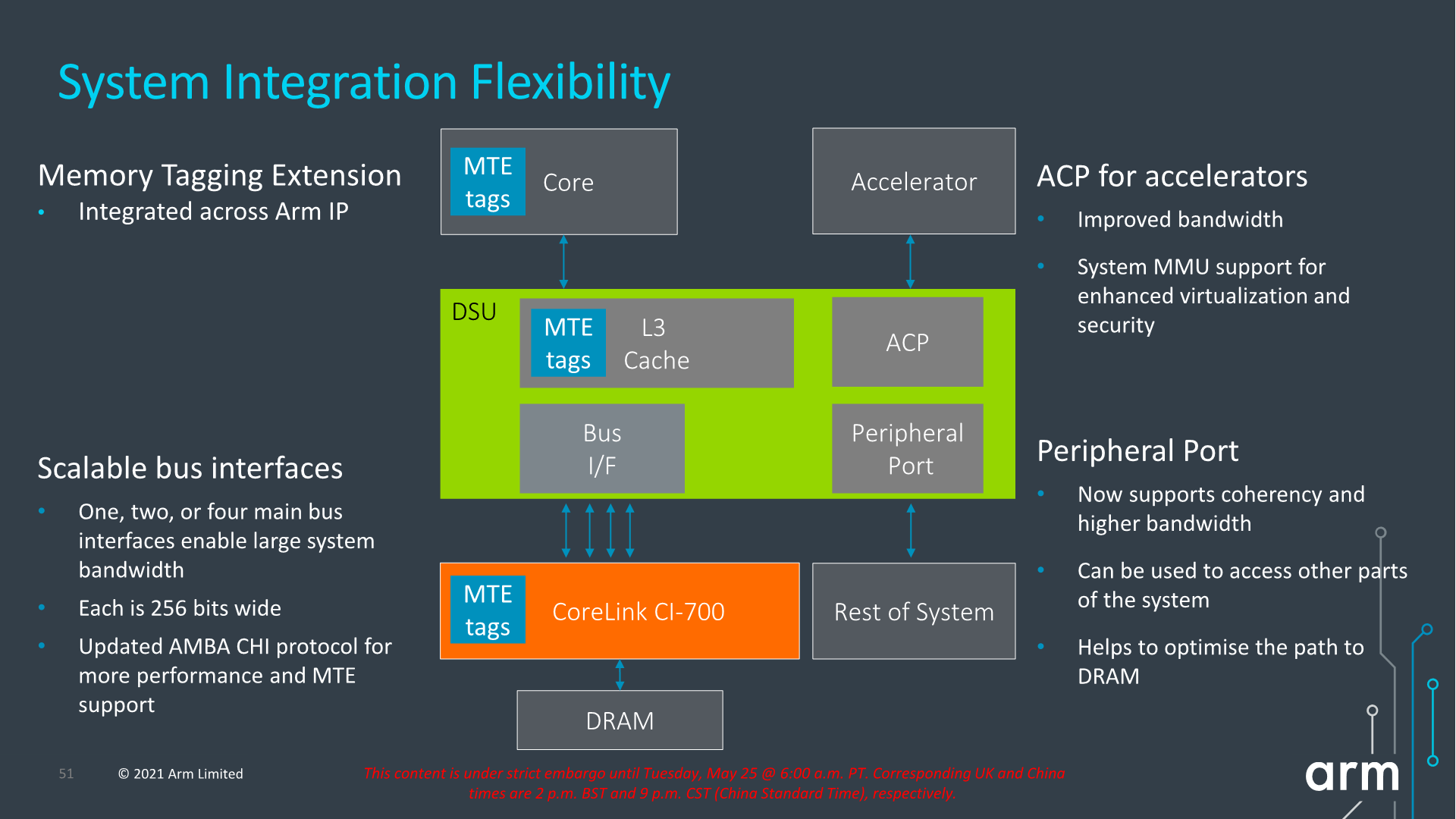
Architecturally, one important change to the capabilities of the DSU-110 is support for MTE tags, a upcoming security and debugging feature promising to greatly help with memory safety issues.
The new DSU can scale up to 4x AMBA CHI ports, meaning we’ll have up to 1024-bit total bi-directional bandwidth to the system memory. With a theoretical DSU clock of around 2GHz this would enable bandwidth of up to 256GB/s reads or writes, or double that when combined, plenty enough to be able to saturate also eventual high-end laptop configurations.

In terms of power efficiency, the new DSU offers more options for low-power operation when in idle situations, implementing partial L3 power-down, able to reduce leakage power of up to 75% compared to the current DSU.
In general idle situations but still having the full L3 powered on, the new design promises up to 25% reduction in leakage power all whilst offering 2x the bandwidth capabilities.
It’s important to note that we’re talking about leakage power here- active dynamic power is expected to generally scale linearly with the bandwidth increase of the new design, meaning 5x the bandwidth would also cost 5x the power. This would be an important factor to note into system power and in general the expected power behaviour of the next-gen SoCs when they’re put under heavy memory workloads.

Arm describes the DSU-110 as the backbone of the Armv9 cluster and that seemingly seems to be an apt description. The new bandwidth capabilities are sure to help out both with single-threaded, but also with multi-threaded performance of upcoming SoCs. Generally, the new 16MB L3 capability, while it’s possible somebody might do a high-end laptop SoC configuration, isn’t as exciting as the now finally expected move to a new 8MB L3 on mobile SoCs, hopefully also enabling higher power efficiency and more battery life for devices.








181 Comments
View All Comments
jeremyshaw - Tuesday, May 25, 2021 - link
Something I'm not quite catching with the DSU, does it allow for different configurations that we've already seen? Something like the 8xA78C we saw announced a while back?jeremyshaw - Tuesday, May 25, 2021 - link
*than, sorrySarahKerrigan - Tuesday, May 25, 2021 - link
They show 8x X2 configs, so I'd be shocked if 8xA710 was not also on the menu.igor velky - Tuesday, May 25, 2021 - link
first two slides on page 5 will give you answer,both slides show cpu cores inside one cpu cluster
first slide shows different cores,
second shows only one type of core in cpu cluster
on page 6 because of bad formatting there are two slides looking like one picture
so second slide, bottom half of first picture
shows you that you can put max 8 cpu clusters to one chip.
so you can have
max 8 cpu cores per cpu cluster
times
8 cpu clusters per one chip.
you choose cores, you choose how many cores, you choose which type of cores, you choose how many memory channels, you choose how many and what type of additional accelerators you put inside chip...
because youre apple, samsung, qualcomm...
and you choose this things and let someone to "etch it" into silicon.
and you then sell it.
melgross - Tuesday, May 25, 2021 - link
Well, Apple doesn’t “choose” cores, they design them from scratch.Linustechtips12#6900xt - Wednesday, May 26, 2021 - link
ehhh, they get the IP for cores like the x1 or a76 then they tweak them either a lot or a little and create their current "firestorm/Icestorm" coresmichael2k - Wednesday, May 26, 2021 - link
Sure, they tweak them a lot, just like I tweaked your post a lot to make my own. The A13 released in 2019 was an 8 wide CPU; in comparison the state of the art A76 at the time was only a 4 wide CPU. That’s a pretty big deal.The X1 has an 8 wide dispatch, meaning it can issue 8 Mops per cycle but only decode 5 instructions per cycle. This is 2 years after Apple released the A13 which was 8 wide dispatch and decode. If you look at Anandtech’s A14 article you see that Apple has made the Icestorm cores roughly equivalent to an A76 since it is a 3 wide out of order design.
You can read more here:
https://www.anandtech.com/show/16226/apple-silicon...
mattbe - Wednesday, May 26, 2021 - link
This is complete BS. They license the ISA from ARM. They DO NOT USE OR TWEAK cores like the X1 and A76 to create their firestorm/ice storm cores. These are information that can easily be verified so it's pretty ignorant for you to make those claims.FunBunny2 - Wednesday, May 26, 2021 - link
" They DO NOT USE OR TWEAK cores"near as I can tell, most 'innovation' in cpu design/engineering has been, for years, throwing ever expanding transistor budgets (can we expect that to continue?) at register width, path width, buffer/cache width and number, pulling off-chip function on-chip. and the like. if Apple should ever publish the full spec of one of these chips, will we see that they've done anything more 'innovative' than Bigger, Wider, More?
all of the 'innovation' cited by michael2k fits that bill.
mode_13h - Thursday, May 27, 2021 - link
> if Apple should ever publish the full spec of one of these chips,> will we see that they've done anything more 'innovative' than Bigger, Wider, More?
You don't get perf/W numbers like Apple's by simply doing "bigger, wider, more".
There's information out there about some of their tricks, if you're willing to look for it. But I understand that it takes work and why do that, when you're perfectly content in your belief that there's nothing new under the sun?