Intel 11th Generation Core Tiger Lake-H Performance Review: Fast and Power Hungry
by Brett Howse & Andrei Frumusanu on May 17, 2021 9:00 AM EST- Posted in
- CPUs
- Intel
- 10nm
- Willow Cove
- SuperFin
- 11th Gen
- Tiger Lake-H
CPU Tests: Rendering
Rendering tests, compared to others, are often a little more simple to digest and automate. All the tests put out some sort of score or time, usually in an obtainable way that makes it fairly easy to extract. These tests are some of the most strenuous in our list, due to the highly threaded nature of rendering and ray-tracing, and can draw a lot of power. If a system is not properly configured to deal with the thermal requirements of the processor, the rendering benchmarks is where it would show most easily as the frequency drops over a sustained period of time. Most benchmarks in this case are re-run several times, and the key to this is having an appropriate idle/wait time between benchmarks to allow for temperatures to normalize from the last test.
Blender 2.83 LTS: Link
One of the popular tools for rendering is Blender, with it being a public open source project that anyone in the animation industry can get involved in. This extends to conferences, use in films and VR, with a dedicated Blender Institute, and everything you might expect from a professional software package (except perhaps a professional grade support package). With it being open-source, studios can customize it in as many ways as they need to get the results they require. It ends up being a big optimization target for both Intel and AMD in this regard.
For benchmarking purposes, we fell back to one rendering a frame from a detailed project. Most reviews, as we have done in the past, focus on one of the classic Blender renders, known as BMW_27. It can take anywhere from a few minutes to almost an hour on a regular system. However now that Blender has moved onto a Long Term Support model (LTS) with the latest 2.83 release, we decided to go for something different.

We use this scene, called PartyTug at 6AM by Ian Hubert, which is the official image of Blender 2.83. It is 44.3 MB in size, and uses some of the more modern compute properties of Blender. As it is more complex than the BMW scene, but uses different aspects of the compute model, time to process is roughly similar to before. We loop the scene for at least 10 minutes, taking the average time of the completions taken. Blender offers a command-line tool for batch commands, and we redirect the output into a text file.

Corona 1.3: Link
Corona is billed as a popular high-performance photorealistic rendering engine for 3ds Max, with development for Cinema 4D support as well. In order to promote the software, the developers produced a downloadable benchmark on the 1.3 version of the software, with a ray-traced scene involving a military vehicle and a lot of foliage. The software does multiple passes, calculating the scene, geometry, preconditioning and rendering, with performance measured in the time to finish the benchmark (the official metric used on their website) or in rays per second (the metric we use to offer a more linear scale).

The standard benchmark provided by Corona is interface driven: the scene is calculated and displayed in front of the user, with the ability to upload the result to their online database. We got in contact with the developers, who provided us with a non-interface version that allowed for command-line entry and retrieval of the results very easily. We loop around the benchmark five times, waiting 60 seconds between each, and taking an overall average. The time to run this benchmark can be around 10 minutes on a Core i9, up to over an hour on a quad-core 2014 AMD processor or dual-core Pentium.
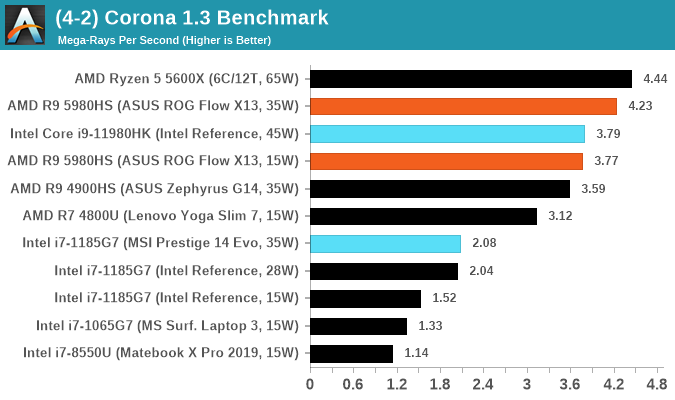
POV-Ray 3.7.1: Link
A long time benchmark staple, POV-Ray is another rendering program that is well known to load up every single thread in a system, regardless of cache and memory levels. After a long period of POV-Ray 3.7 being the latest official release, when AMD launched Ryzen the POV-Ray codebase suddenly saw a range of activity from both AMD and Intel, knowing that the software (with the built-in benchmark) would be an optimization tool for the hardware.
We had to stick a flag in the sand when it came to selecting the version that was fair to both AMD and Intel, and still relevant to end-users. Version 3.7.1 fixes a significant bug in the early 2017 code that was advised against in both Intel and AMD manuals regarding to write-after-read, leading to a nice performance boost.

The benchmark can take over 20 minutes on a slow system with few cores, or around a minute or two on a fast system, or seconds with a dual high-core count EPYC. Because POV-Ray draws a large amount of power and current, it is important to make sure the cooling is sufficient here and the system stays in its high-power state. Using a motherboard with a poor power-delivery and low airflow could create an issue that won’t be obvious in some CPU positioning if the power limit only causes a 100 MHz drop as it changes P-states.
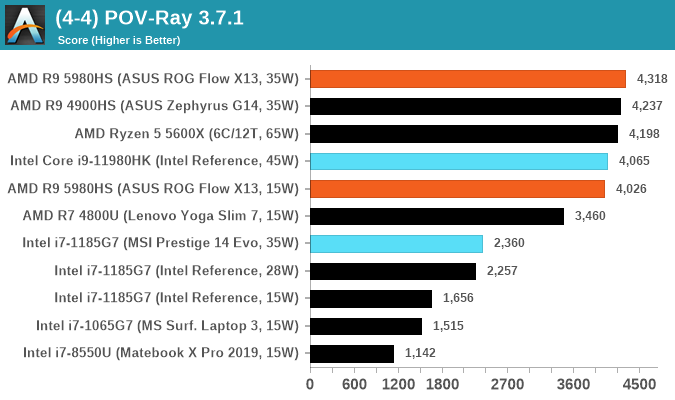
V-Ray: Link
We have a couple of renderers and ray tracers in our suite already, however V-Ray’s benchmark came through for a requested benchmark enough for us to roll it into our suite. Built by ChaosGroup, V-Ray is a 3D rendering package compatible with a number of popular commercial imaging applications, such as 3ds Max, Maya, Undreal, Cinema 4D, and Blender.

We run the standard standalone benchmark application, but in an automated fashion to pull out the result in the form of kilosamples/second. We run the test six times and take an average of the valid results.
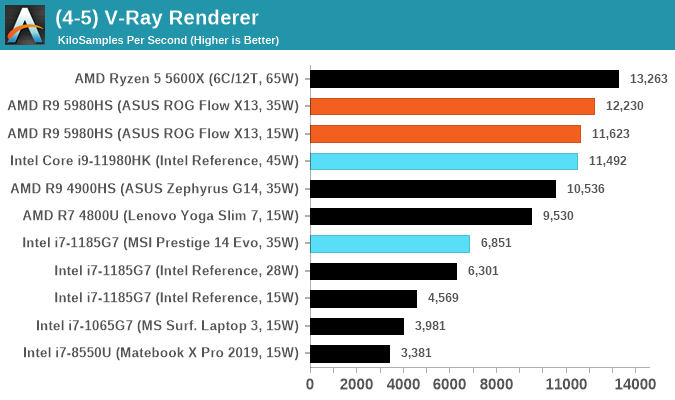
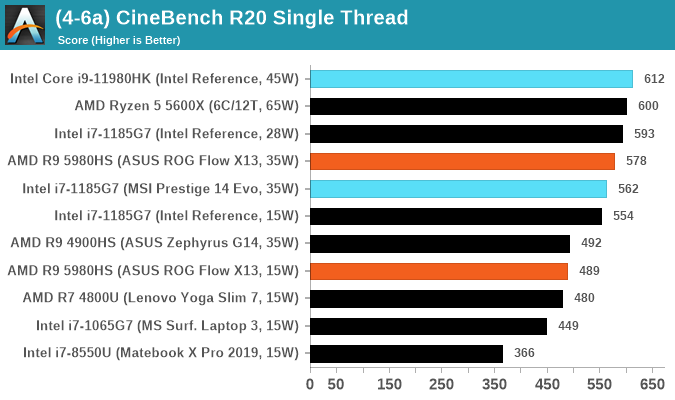
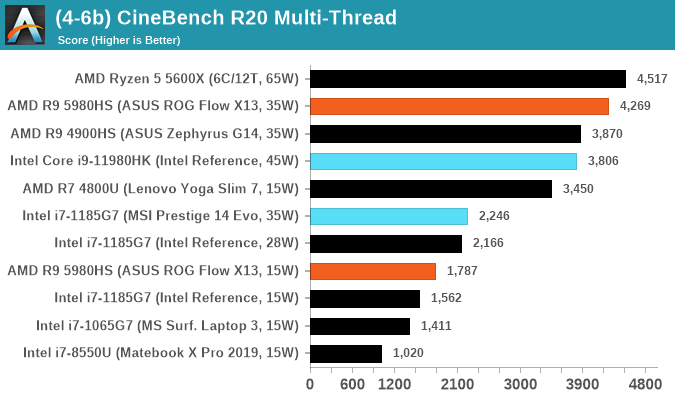
Cinebench R20: Link
Another common stable of a benchmark suite is Cinebench. Based on Cinema4D, Cinebench is a purpose built benchmark machine that renders a scene with both single and multi-threaded options. The scene is identical in both cases. The R20 version means that it targets Cinema 4D R20, a slightly older version of the software which is currently on version R21. Cinebench R20 was launched given that the R15 version had been out a long time, and despite the difference between the benchmark and the latest version of the software on which it is based, Cinebench results are often quoted a lot in marketing materials.
Results for Cinebench R20 are not comparable to R15 or older, because both the scene being used is different, but also the updates in the code bath. The results are output as a score from the software, which is directly proportional to the time taken. Using the benchmark flags for single CPU and multi-CPU workloads, we run the software from the command line which opens the test, runs it, and dumps the result into the console which is redirected to a text file. The test is repeated for a minimum of 10 minutes for both ST and MT, and then the runs averaged.








229 Comments
View All Comments
Spunjji - Thursday, May 20, 2021 - link
He measured the power consumption, you pillock. It's right there in the review. Nice work getting your FUD on the front page though, round of applause for gondaft.If Tiger Lake H will be better in "the right chassis", Intel really should have thought of that when they supplied this one. As things stand, it's clear that this chassis wasn't causing the CPU to throttle at 45W, so the only way it would perform better is in a chassis that allows for 65W - at which point you'd find AMD's CPUs performing better, too...
5j3rul3 - Monday, May 17, 2021 - link
It's a big step to intelM1 and Ryzen 5000 are powerful, Intel need more pros to getting the leading performance
mode_13h - Monday, May 17, 2021 - link
This is definitely what Rocket Lake should've been. If they just put this chip in a desktop package, so it could be run with a desktop power budget and cooling, it'd sure be a lot more interesting than it is inside a laptop.Exotica - Monday, May 17, 2021 - link
Yields may have been the primary concern.mode_13h - Monday, May 17, 2021 - link
I get why they didn't do it, but it's clear to me this chip really wants to be a desktop CPU.whatthe123 - Monday, May 17, 2021 - link
it's probably more that they've tweaked their 10nm to hit high boost at the cost of efficiency. I think they increased their gate pitch with "superfin" so you end up with more performance scaling but also more power use. considering how far behind their desktop chips are compared to 7nm chips from AMD they may just be crippling efficiency across the board to get performance parity while their fabs lag behind. they don't seem to have high hopes for 10nm considering their target for market leadership is 2024 with 7nm.laptop users generally stick with bursty operations or video games and in both cases raw throughput isn't as much of a concern. average user would probably not notice or even benefit from the high ST burst performance, but anyone planning on using it professionally would probably be better off with cezanne.
Spunjji - Tuesday, May 18, 2021 - link
It would certainly be able to stretch its legs better there. It would be interesting to see whether it could handle running those higher boost clocks across more cores with a higher TDP. Guess we'll find out with Alder Lake.Lucky Stripes 99 - Monday, May 17, 2021 - link
I thought the same. This chip in a mini-STX case with a desktop cooler would make a great portable system. However, if it is having thermal issues with a full-size workstation laptop, it'll likely struggle in the smallest of SFF cases like the NUC.Azix - Monday, May 17, 2021 - link
the laptop doesn't look that that big. A nuc would have more vertical space for the cooling for example. It would also be easier to throw that heat out.mode_13h - Monday, May 17, 2021 - link
Uh, the mini-STX NUCs don't really have much space. Everything is packed in pretty tightly. Furthermore, they usually top out at 28 W.For Coffee Lake, Intel made a larger system they called a "NUC", but I think they had actual Nvidia graphics cards in them and were bigger than a lot of mini-PCs.