Intel 11th Generation Core Tiger Lake-H Performance Review: Fast and Power Hungry
by Brett Howse & Andrei Frumusanu on May 17, 2021 9:00 AM EST- Posted in
- CPUs
- Intel
- 10nm
- Willow Cove
- SuperFin
- 11th Gen
- Tiger Lake-H
CPU Tests: Rendering
Rendering tests, compared to others, are often a little more simple to digest and automate. All the tests put out some sort of score or time, usually in an obtainable way that makes it fairly easy to extract. These tests are some of the most strenuous in our list, due to the highly threaded nature of rendering and ray-tracing, and can draw a lot of power. If a system is not properly configured to deal with the thermal requirements of the processor, the rendering benchmarks is where it would show most easily as the frequency drops over a sustained period of time. Most benchmarks in this case are re-run several times, and the key to this is having an appropriate idle/wait time between benchmarks to allow for temperatures to normalize from the last test.
Blender 2.83 LTS: Link
One of the popular tools for rendering is Blender, with it being a public open source project that anyone in the animation industry can get involved in. This extends to conferences, use in films and VR, with a dedicated Blender Institute, and everything you might expect from a professional software package (except perhaps a professional grade support package). With it being open-source, studios can customize it in as many ways as they need to get the results they require. It ends up being a big optimization target for both Intel and AMD in this regard.
For benchmarking purposes, we fell back to one rendering a frame from a detailed project. Most reviews, as we have done in the past, focus on one of the classic Blender renders, known as BMW_27. It can take anywhere from a few minutes to almost an hour on a regular system. However now that Blender has moved onto a Long Term Support model (LTS) with the latest 2.83 release, we decided to go for something different.

We use this scene, called PartyTug at 6AM by Ian Hubert, which is the official image of Blender 2.83. It is 44.3 MB in size, and uses some of the more modern compute properties of Blender. As it is more complex than the BMW scene, but uses different aspects of the compute model, time to process is roughly similar to before. We loop the scene for at least 10 minutes, taking the average time of the completions taken. Blender offers a command-line tool for batch commands, and we redirect the output into a text file.

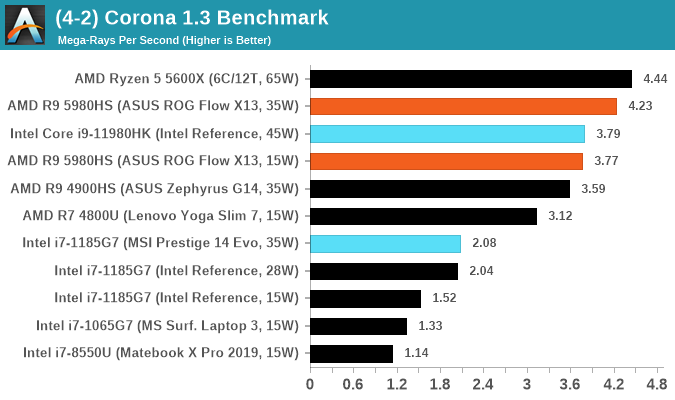
Corona 1.3: Link
Corona is billed as a popular high-performance photorealistic rendering engine for 3ds Max, with development for Cinema 4D support as well. In order to promote the software, the developers produced a downloadable benchmark on the 1.3 version of the software, with a ray-traced scene involving a military vehicle and a lot of foliage. The software does multiple passes, calculating the scene, geometry, preconditioning and rendering, with performance measured in the time to finish the benchmark (the official metric used on their website) or in rays per second (the metric we use to offer a more linear scale).

The standard benchmark provided by Corona is interface driven: the scene is calculated and displayed in front of the user, with the ability to upload the result to their online database. We got in contact with the developers, who provided us with a non-interface version that allowed for command-line entry and retrieval of the results very easily. We loop around the benchmark five times, waiting 60 seconds between each, and taking an overall average. The time to run this benchmark can be around 10 minutes on a Core i9, up to over an hour on a quad-core 2014 AMD processor or dual-core Pentium.
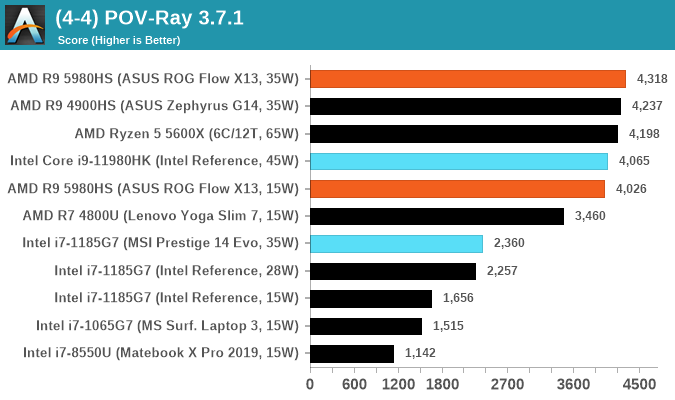
POV-Ray 3.7.1: Link
A long time benchmark staple, POV-Ray is another rendering program that is well known to load up every single thread in a system, regardless of cache and memory levels. After a long period of POV-Ray 3.7 being the latest official release, when AMD launched Ryzen the POV-Ray codebase suddenly saw a range of activity from both AMD and Intel, knowing that the software (with the built-in benchmark) would be an optimization tool for the hardware.
We had to stick a flag in the sand when it came to selecting the version that was fair to both AMD and Intel, and still relevant to end-users. Version 3.7.1 fixes a significant bug in the early 2017 code that was advised against in both Intel and AMD manuals regarding to write-after-read, leading to a nice performance boost.

The benchmark can take over 20 minutes on a slow system with few cores, or around a minute or two on a fast system, or seconds with a dual high-core count EPYC. Because POV-Ray draws a large amount of power and current, it is important to make sure the cooling is sufficient here and the system stays in its high-power state. Using a motherboard with a poor power-delivery and low airflow could create an issue that won’t be obvious in some CPU positioning if the power limit only causes a 100 MHz drop as it changes P-states.
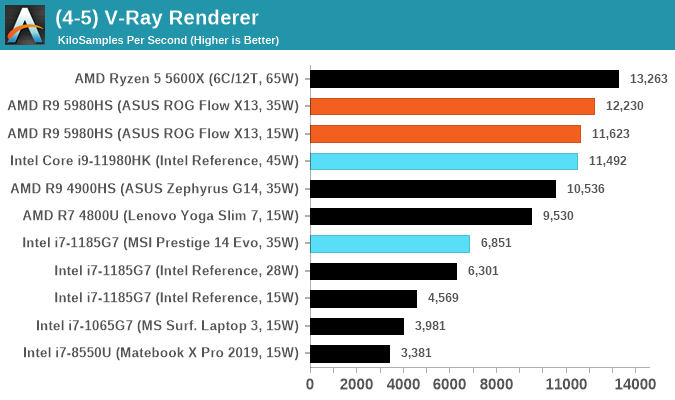
V-Ray: Link
We have a couple of renderers and ray tracers in our suite already, however V-Ray’s benchmark came through for a requested benchmark enough for us to roll it into our suite. Built by ChaosGroup, V-Ray is a 3D rendering package compatible with a number of popular commercial imaging applications, such as 3ds Max, Maya, Undreal, Cinema 4D, and Blender.

We run the standard standalone benchmark application, but in an automated fashion to pull out the result in the form of kilosamples/second. We run the test six times and take an average of the valid results.
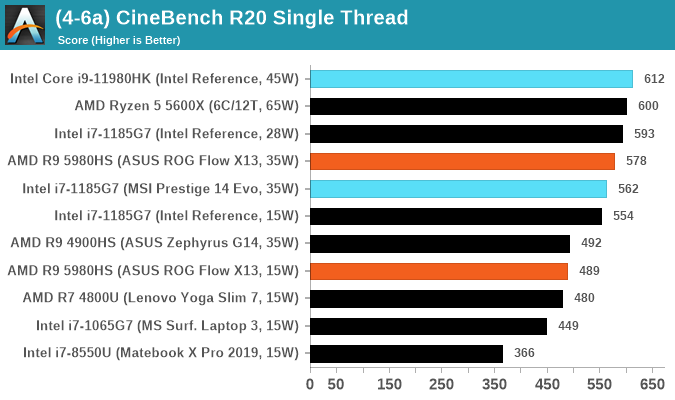
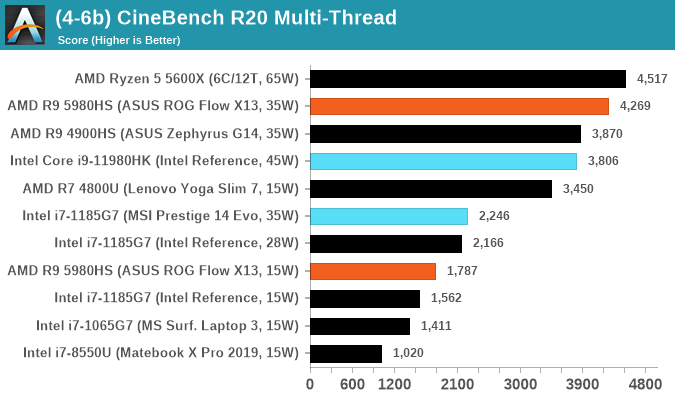
Cinebench R20: Link
Another common stable of a benchmark suite is Cinebench. Based on Cinema4D, Cinebench is a purpose built benchmark machine that renders a scene with both single and multi-threaded options. The scene is identical in both cases. The R20 version means that it targets Cinema 4D R20, a slightly older version of the software which is currently on version R21. Cinebench R20 was launched given that the R15 version had been out a long time, and despite the difference between the benchmark and the latest version of the software on which it is based, Cinebench results are often quoted a lot in marketing materials.
Results for Cinebench R20 are not comparable to R15 or older, because both the scene being used is different, but also the updates in the code bath. The results are output as a score from the software, which is directly proportional to the time taken. Using the benchmark flags for single CPU and multi-CPU workloads, we run the software from the command line which opens the test, runs it, and dumps the result into the console which is redirected to a text file. The test is repeated for a minimum of 10 minutes for both ST and MT, and then the runs averaged.








229 Comments
View All Comments
eastcoast_pete - Monday, May 17, 2021 - link
A key question is now if Intel can further improve its 10 nm superfin process in time for Alder Lake. This TL is at least getting somewhat close to AMD's monolithic Zen3, but Rembrandt is around the corner, and that'll be an even more capable competitor. Right now, Intel retains its market share mostly because AMD can't deliver as many CPUs as people would buy.hfm - Monday, May 17, 2021 - link
I'm looking forward to an i5 or i7 design with no dGPU and that sweet embedded TB4. Probably going to be a small subset of the offerings like the lower tier XPS 15/17. Interested to see what comes about later in summer.evilspoons - Monday, May 17, 2021 - link
It'd be helpful to see power-normalized graphs, some of these results are a bit of a double-edged sword.outsideloop - Monday, May 17, 2021 - link
I want to see a comparison of the 11980HK with the 5800X clocked down to 65W, apples to apples. Let's compare the thermals of the AMD 8-core desktop to this "desktop replacement" Intel 8-core.Hifihedgehog - Monday, May 17, 2021 - link
Core i9-11980HK:https://images.anandtech.com/doci/16680/P95-45W_57...
Ryzen 9 5980HK:
https://images.anandtech.com/doci/16446/Power-P95-...
Just to add some further insight on these two charts, here is some breakdown. What ultimately happens is under sustained heavy loads, Ryzen 5000 series can maintain 8 cores at higher sustained clock speeds (~3.7 GHz) with lower power draw (35W). Bear in mind also that Zen 3 has a slight IPC advantage over Tiger Lake, meaning at a lower clock speed, it performs the same or does the same amount of work as Tiger Lake at a higher clock speed. Yet here we are where Ryzen 5000 can clock higher, do even MORE work, and draw less power. Meanwhile, Intel is struggling to reach similar sustained clock speeds (~3.2 GHz) at 45W sustained and it has slightly lower IPC. That is, Ryzen 5000 is ~10% faster clock-for-clock (or in IPC) than Intel's Willow Cove (Tiger Lake 11th Gen), Cypress Cove (Rocket Lake 11th Gen) or Sunny Cove (Ice Lake 10th Gen) which all three share roughly the same IPC amongst the whole trio (link: https://www.guru3d.com/articles_pages/intel_core_i... ). Ryzen 5000's synergy (higher clocks, lower power, higher IPC) sounds like a recipe for disaster for Intel, no? Alder Lake needs to come sooner rather than later if you ask me. Let's just hope Intel is throwing the full weight of their massive workforce of software developers at the problem of Alder Lake's heterogenous architecture because they will certainly need it working smoothly for it to shine.
lmcd - Monday, May 17, 2021 - link
Can we pause to note that MSI delivering bad thermal performance is characteristic of every single one of their laptops, bar none?lmcd - Monday, May 17, 2021 - link
Like, obviously that doesn't solve all the problems here, but how on earth with all the delays TGL-H(45+) got is this the OEM Intel picked?Spunjji - Tuesday, May 18, 2021 - link
It's a very odd choice. But then, didn't they use MSI for the original TGL reference platform too? That one actually outperformed most shipping devices, although IIRC it did so by running the fans at 100% 🤷♂️lmcd - Tuesday, May 18, 2021 - link
I put it on twitter also but my opinion is that the Tiger Lake MSI design is actually about the cooling and size that MSI would use for an H series processor normally, such as the MSI Creator.This implies that the MSI's thermal overhead is pure luck on Intel's part in that MSI didn't have time to reduce the thermal performance accordingly.
Spunjji - Thursday, May 20, 2021 - link
That would make sense!