Intel 11th Generation Core Tiger Lake-H Performance Review: Fast and Power Hungry
by Brett Howse & Andrei Frumusanu on May 17, 2021 9:00 AM EST- Posted in
- CPUs
- Intel
- 10nm
- Willow Cove
- SuperFin
- 11th Gen
- Tiger Lake-H
SPEC CPU - Single-Threaded Performance
SPEC2017 and SPEC2006 is a series of standardized tests used to probe the overall performance between different systems, different architectures, different microarchitectures, and setups. The code has to be compiled, and then the results can be submitted to an online database for comparison. It covers a range of integer and floating point workloads, and can be very optimized for each CPU, so it is important to check how the benchmarks are being compiled and run.
We run the tests in a harness built through Windows Subsystem for Linux, developed by our own Andrei Frumusanu. WSL has some odd quirks, with one test not running due to a WSL fixed stack size, but for like-for-like testing is good enough. SPEC2006 is deprecated in favor of 2017, but remains an interesting comparison point in our data. Because our scores aren’t official submissions, as per SPEC guidelines we have to declare them as internal estimates from our part.
For compilers, we use LLVM both for C/C++ and Fortan tests, and for Fortran we’re using the Flang compiler. The rationale of using LLVM over GCC is better cross-platform comparisons to platforms that have only have LLVM support and future articles where we’ll investigate this aspect more. We’re not considering closed-sourced compilers such as MSVC or ICC.
clang version 10.0.0
clang version 7.0.1 (ssh://git@github.com/flang-compiler/flang-driver.git
24bd54da5c41af04838bbe7b68f830840d47fc03)
-Ofast -fomit-frame-pointer
-march=x86-64
-mtune=core-avx2
-mfma -mavx -mavx2
Our compiler flags are straightforward, with basic –Ofast and relevant ISA switches to allow for AVX2 instructions. We decided to build our SPEC binaries on AVX2, which puts a limit on Haswell as how old we can go before the testing will fall over. This also means we don’t have AVX512 binaries, primarily because in order to get the best performance, the AVX-512 intrinsic should be packed by a proper expert, as with our AVX-512 benchmark.
To note, the requirements for the SPEC licence state that any benchmark results from SPEC have to be labelled ‘estimated’ until they are verified on the SPEC website as a meaningful representation of the expected performance. This is most often done by the big companies and OEMs to showcase performance to customers, however is quite over the top for what we do as reviewers.
Single-threaded performance of TGL-H shouldn’t be drastically different from that of TGL-U, however there’s a few factors which can come into play and affect the results: The i9-11980HK TGL-H system has a 200MHz higher boost frequency compared to the i7-1185G7, and a single core now has access to up to 24MB of L3 instead of just 12MB.
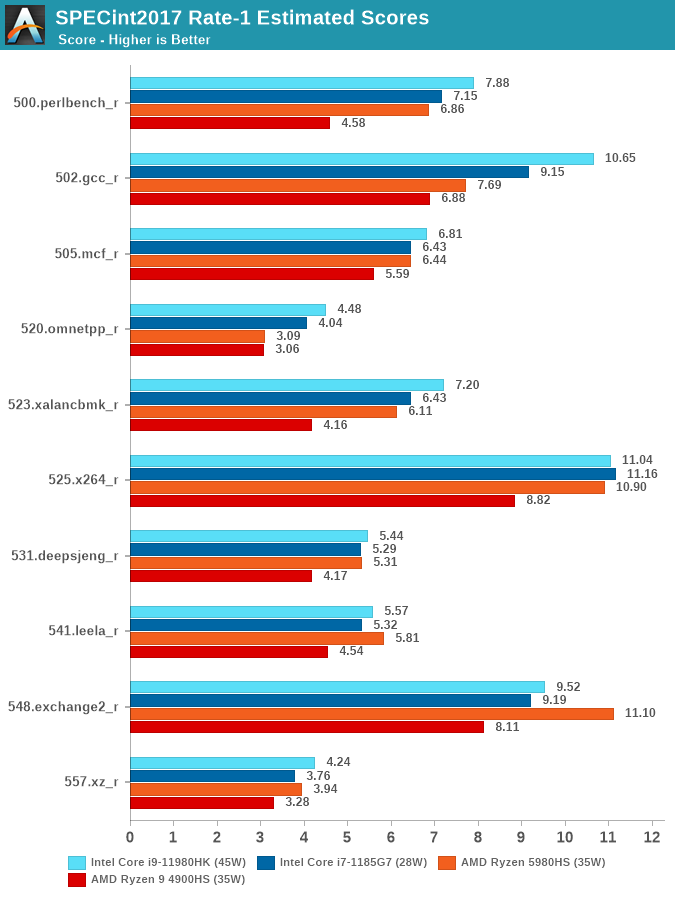
In SPECint2017, the one results which stands out the most if 502.gcc_r where the TGL-H processor lands in at +16% ahead of TGL-U, undoubtedly due to the increased L3 size of the new chip.
Generally speaking, the new TGL-H chip outperforms its brethren and AMD competitors in almost all tests.
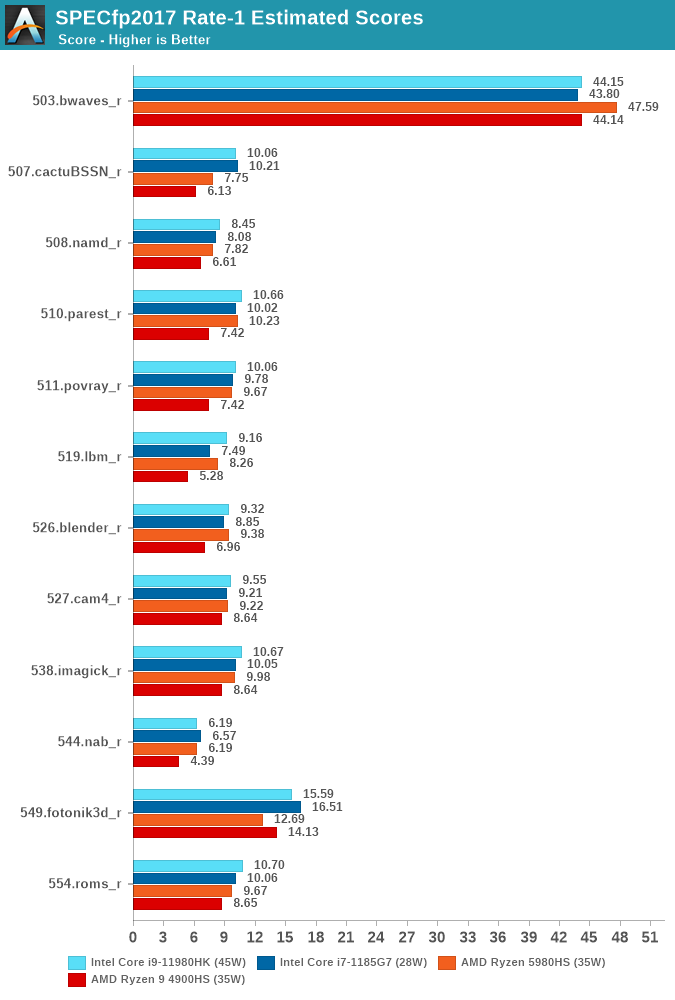
In the SPECfp2017 suite, we also see general small improvements across the board. The 549.fotonik3d_r test sees a regression which is a bit odd, but I think is related to the LPDDR4 vs DDR4 discrepancy in the systems which I’ll get back to in the next page where we’ll see more multi-threaded results related to this.
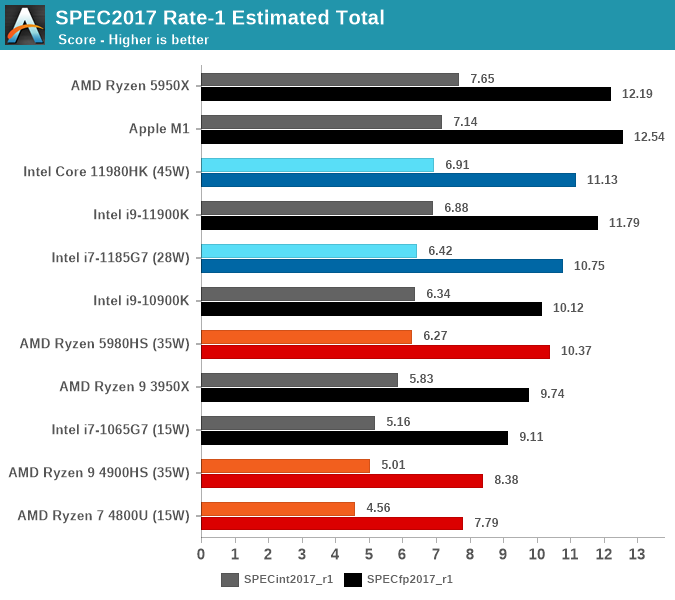
From an overall single-threaded performance standpoint, the TGL-H i9-11980HK adds in around +3.5-7% on top of what we saw on the i7-1185G7, which lands it amongst the best performing systems – not only amongst laptop CPUs, but all CPUs. The performance lead against AMD’s strongest mobile CPU, the 5980HS is even a little higher than against the i7-1185G7, but loses out against AMD’s best desktop CPU, and of course Apple M1 CPU and SoC used in the latest Macbooks. This latter comparison is apples-to-apples in terms of compiler settings, and is impressive given it does it at around 1/3rd of the package power under single-threaded scenarios.








229 Comments
View All Comments
SarahKerrigan - Monday, May 17, 2021 - link
Of course. It must be some kind of dark conspiracy to hide the real compiler settings. The truth is out there! Trust no one!Spunjji - Tuesday, May 18, 2021 - link
Counterpoint: You're full of it, and blowing hard.repoman27 - Monday, May 17, 2021 - link
Andrei, TGL-U (UP3/UP4/H35) LPDDR4/X is actually 8x16. Two memory controllers, each with four x16 channels.Andrei Frumusanu - Monday, May 17, 2021 - link
Yes, brainfart.mode_13h - Monday, May 17, 2021 - link
Wow!So, how are they mapped? How much interleaving, and at what granularity?
mode_13h - Monday, May 17, 2021 - link
Incidentally, I have a Phenom II motherboard that allows me to configure page-granularity interleaving. Not sure how common it is, but I don't think my Intel workstation board gives me that option!KarlKastor - Monday, May 17, 2021 - link
Doesn't sound like a good CPU benchmark to me.mode_13h - Monday, May 17, 2021 - link
So, you want a suite of benchmarks that all behave similarly and don't stress the platform in various and different ways?Suit yourself, but I think a good benchmark suite should have enough diversity to hit different edge cases, as long as it's not doing anything unrealistic. And, as far as I can tell, the SPEC 17 tests are entirely comprised of real-world programs.
Otritus - Monday, May 17, 2021 - link
Interesting how much power Tiger Lake H needs to draw to be competitive with Cezanne. At this point it's clear that Intel's big cores are bloated when AMD has higher IPC and frequency at lower power draw with a comparable node. Little cores in Alder Lake may help with efficiency, but they are taking power budget away from the big cores which hurts their frequency. Intel probably needs to redesign their big cores from the ground up rather than continuing to refine and improve Pentium-M.On a side note I'm conflicted on your decision to omit AVX-512 on NAMD. On one hand you are not testing AVX-512, but on the other hand you are omitting a possibly real world scenario for someone. Intel's marketing on AVX-512 and its inclusion in consumer processors are questionable choices, but that still is a valid, functional feature built into the chip. Perhaps a good compromise would be to add in the updated version for AVX-512 processors only.
zaza - Monday, May 17, 2021 - link
Most workloads that can run avx256 can easily be extended to AVX-512. In some cases, you need just to recompile with AVX-512 optimization floag on. Even Skylake-X and cascadelake-X there is a noticeable improvement in performance in AVX-512