Arm Announces Neoverse V1, N2 Platforms & CPUs, CMN-700 Mesh: More Performance, More Cores, More Flexibility
by Andrei Frumusanu on April 27, 2021 9:00 AM EST- Posted in
- CPUs
- Arm
- Servers
- Infrastructure
- Neoverse N1
- Neoverse V1
- Neoverse N2
- CMN-700
The Neoverse N2 µArch: First Armv9 For Enterprise
Moving from the performance oriented Neoverse V1 to the more balanced Neoverse N2 core, we’re seeing a different approach to performance, more akin to the Cortex-A78’s PPA focus versus the X1’s performance focus.
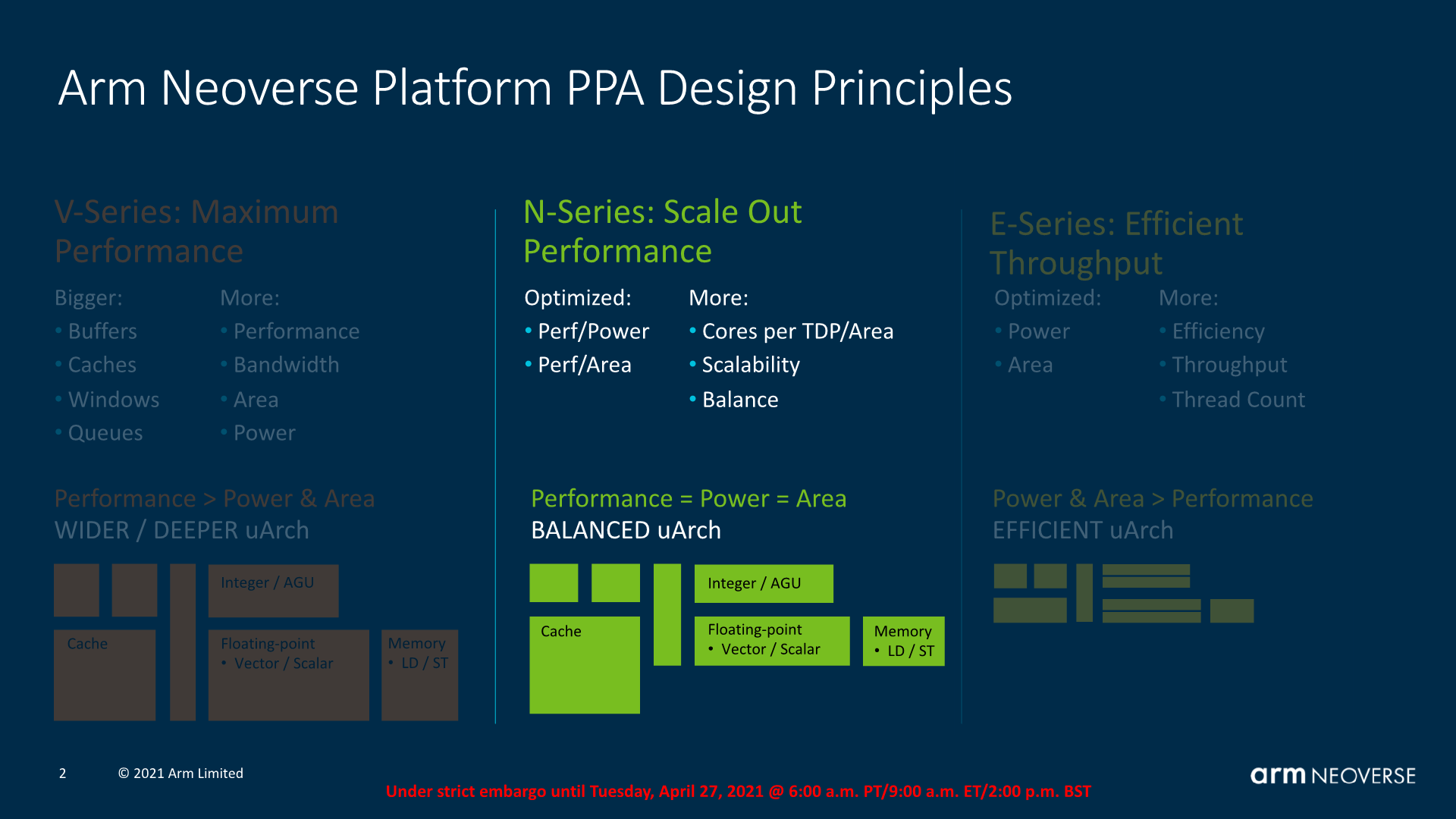

Arm makes note of the “balance” keyword here – the microarchitecture only adopts features and design changes if those changes actually contribute to an increase of the PPA (Performance, Power, Area) equation of the IP. In contrast, the V1 would opt for performance increasing features even if that meant a disproportionate increase in power and area, reducing the total PPA of the design.
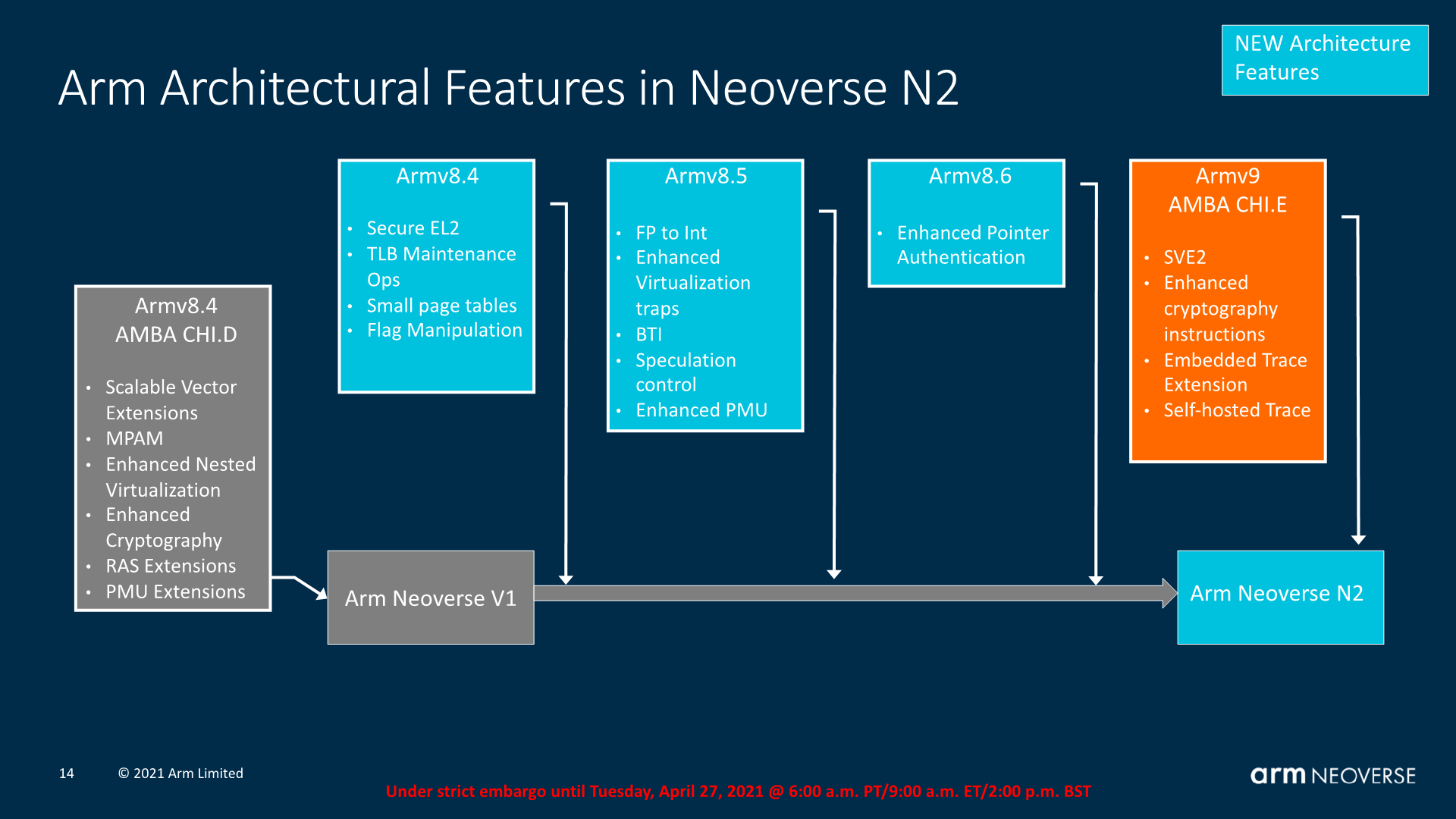
Architecturally, the N2 is a newer core than the V1 and takes a higher architectural baseline as the foundation of its capabilities. It’s Arm’s first disclosed Armv9 capable core, including important new features such as SVE2. It’s to be noted that although Arm talked a lot about Armv9 CCA (Confidential Compute Architecture) last month, the Neoverse N2 core does not feature this capability, which is an extension we’re told to expect in future microarchitecture designs.

Arm’s microarchitectural disclosures on the N2 were rather limited compared to the details we’ve seen on the V1. This being a sibling core to the yet undisclosed next generation Cortex-A78 successor, we’ll have to wait a few more months to see exactly what differentiates this newer iteration compared to the Cortex-A78, besides the notable Armv9 features and new SVE2 pipelines.

Arm at least confirms that it’s a narrower microarchitecture in the sense that there’s only a 5-wide dispatch (compared to 8-wide in the V1), and the design features 2x128b native SVE2 and NEON pipelines.
The company states that the new design should still achieve an impressive +40% increase in IPC compared to the Neoverse N1, which is actually substantial given the fact that we’re promised only a linear increase in power and area.

In terms of “smarts”, or better said, microarchitectural innovations, the N2 is a super-set of the V1, just with a more conservative approach to block and structure sizes.

System side features, on top of MPMM and DT, PDP, or Performance Defined Power Management is a feature newer to the N2 that promises to vary the CPU’s microarchitectural features depending on workloads, in order to reduce power consumption without impacting performance. I imagine here that we’re talking about smarter workload dependent clock-gating of microarchitectural features, for example narrowing of the execution resources in low-IPC workloads.








95 Comments
View All Comments
mode_13h - Wednesday, April 28, 2021 - link
Ah, yes! wikichip says of Zen 1:> Accordingly the peak throughput is four SSE/AVX-128 instructions
> or two AVX-256 instructions per cycle.
And Zen 2:
> This improvement doubles the peak throughput of AVX-256 instructions to four per cycle
Wow!
mode_13h - Tuesday, April 27, 2021 - link
What's SLC? I figured it was Second-Level Cache, until I saw the slide referencing "SLC -> L2 traffic"."System Level Cache", maybe? Could it be the term they use instead of L3 or LLC?
Thala - Tuesday, April 27, 2021 - link
I think you are totally right - SLC == LLC.Thala - Tuesday, April 27, 2021 - link
Quick addition. The term SLC is more popular lately, as it emphasize that the cache is not only shared among the cores but also with the system (GPU, DMAs etc).mode_13h - Wednesday, April 28, 2021 - link
Thanks. I guess I should've just waited until I'd finished reading it, because the interconnect slide made it abundantly clear.Now, I'm wondering about this "snoop filter" and why so much RAM is needed for it, when Graviton 2 & Altra have so little SLC. So, I gather it's not like tag RAM, then? Does it index the L2 of the adjacent cores, or something like that?
mode_13h - Tuesday, April 27, 2021 - link
Question and corrections on Page 6: PPA & ISO Performance ProjectionsWhat do the colors on the chip plots mean?
> Only losing out 10% IPC versus the N1
I'm sure that's meant to say "V1".
> In terms of absolute IPC improvements
Huh? These are definitely "relative IPC improvements" or just "IPC improvements".
Calin - Wednesday, April 28, 2021 - link
AWS share by vendor type: It should have been "Vendor A" and "Vendor I"mode_13h - Wednesday, April 28, 2021 - link
That slide was provided by ARM and I think they're trying to have at least the *appearance* of maintaining anonymity, even if the identities are abundantly clear.Also, you realize that their Vendor A is your Vendor I, right?
serendip - Wednesday, April 28, 2021 - link
How does the narrower front end and shallower pipeline of the N2 compare to Apple's M1? I'm thinking about how this could translate to the A78 successor, if that uses an evolution of the X1 core with improvements from N2 brought in.mode_13h - Thursday, April 29, 2021 - link
Good point. It suggests the A78+1 will perform < N2.Although, a derivative X-core would likely be > N2.