Arm Announces Neoverse V1, N2 Platforms & CPUs, CMN-700 Mesh: More Performance, More Cores, More Flexibility
by Andrei Frumusanu on April 27, 2021 9:00 AM EST- Posted in
- CPUs
- Arm
- Servers
- Infrastructure
- Neoverse N1
- Neoverse V1
- Neoverse N2
- CMN-700
The SVE Factor - More Than Just Vector Size
We’ve talked a lot about SVE (Scalable Vector Extensions) over the past few years, and the new Arm ISA feature has been most known as being employed for the first time in Fujitsu’s A64FX processor core, which now powers the world’s most performance supercomputer.
Traditionally, employing CPU microarchitectures with wider SIMD vector capabilities always came with the caveat that you needed to use a new instruction set to make use of these wider vectors. For example, in the x86 world, we’ve seen the move from 128b (SSE-SSE4.2 & AVX) to 256b (AVX & AVX2) to 512b (AVX512) vectors always be coupled with a need for software to be redesigned and recompiled to make use of newer wider execution capabilities.
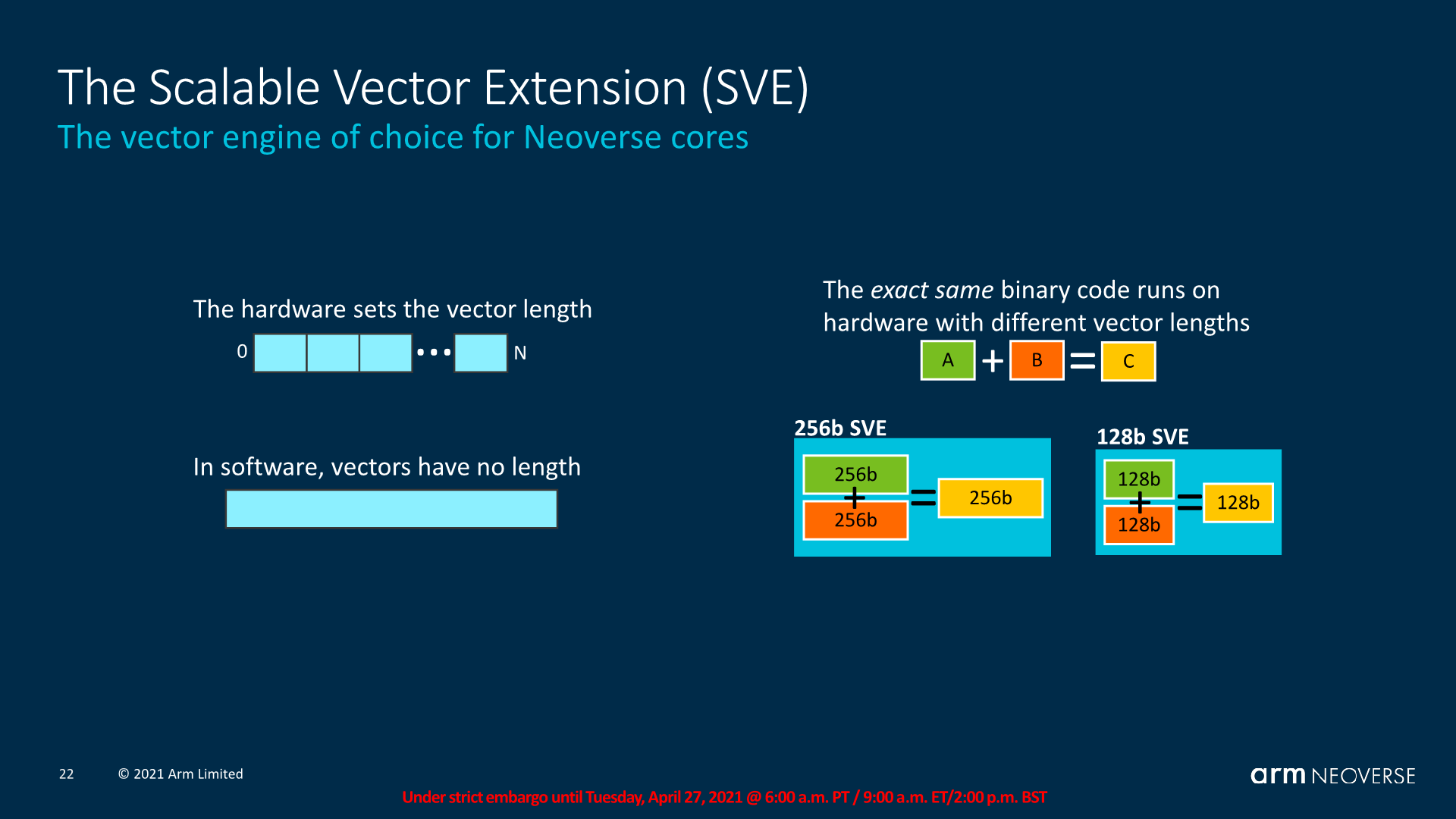
SVE on the other hand is hardware vector execution unit width agnostic, meaning that from a software perspective, the programmer doesn’t actually know the length of the vector that the software will end up running at. On the hardware side, CPU designers can implement execution units in 128b increments from 128b to 2048b in width. As noted earlier, the Neoverse N2 uses this smaller implementation of 128b units, while the Neoverse V1 uses 256b implementations.
Generally speaking, the actual execution width of the vector isn’t as important as the total execution width of a microarchitecture, 2x256b isn’t necessarily faster than 4x128b, however it does play a larger role on the software side of things where the same binary and code path can now be deployed to very different target products, which is also very important for Arm and their mobile processor designs.
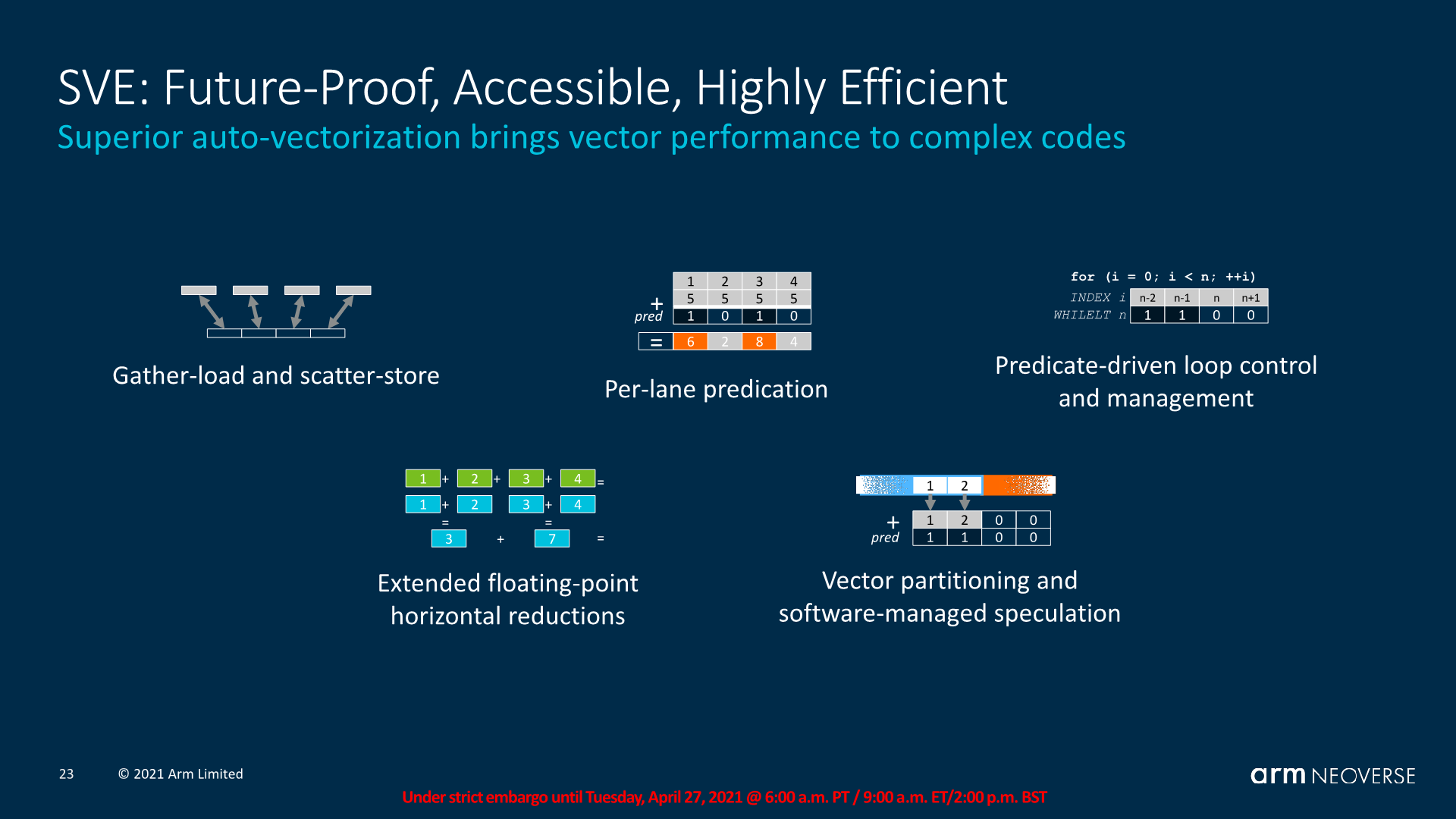
More important than the actual scalable nature of the vectors in SVE, is the new addition of helper instructions and features such as gather-loads, scatter-stores, per-lane predication, predicate-driven loop control (conditional execution depending on SIMD data), and many other features.
Where these things particularly come into play is for allowing compilers to generate better auto-vectorised code, meaning the compiler would now be capable of emitting SIMD instructions on SVE where previously it wasn’t possible with NEON – regardless of the vector length changes.

Arm here discloses that the performance advantages on auto-vectorizable code can be quite significant. In a 2x128b comparison between the N1 and the N2, we can see around 40th-percentile gains of at least 20% of performance, with some code reaching even much higher gains of up to +90%.
The V1 versus N1 increase being higher comes natural from the fact that the core has double the vector execution capabilities over the N1.

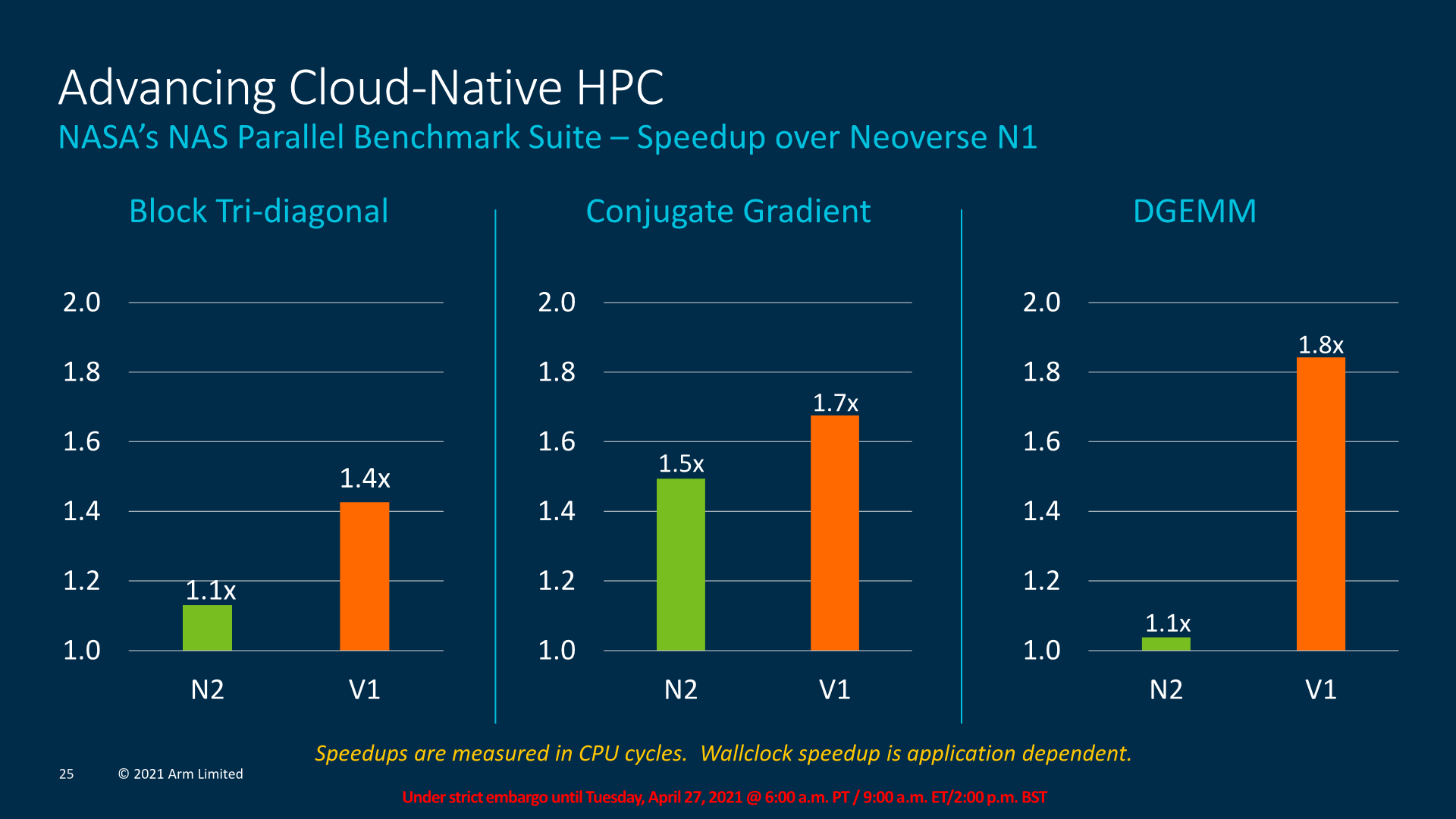
In general, both the N2, but particularly the V1, promise quite large increase in HPC workloads with vector heavy compute characteristics. It’ll definitely be interesting to see how these future designs play out and how SVE auto-vectorisation plays out in more general purpose workloads.








95 Comments
View All Comments
mode_13h - Tuesday, April 27, 2021 - link
> sample in the second half of 2022Uh, that means new machines won't be using them until at least the end of next year. And if we want more cores than an ultraportable, it's still no good.
Raqia - Wednesday, April 28, 2021 - link
I wouldn't put it past them to do a desktop or server sized SoC eventually if they have a great in house core design that isn't a commoditized IP block that anyone can license from ARM. It would give them an advantage at the higher tiers of performance that they will want piece of for sure.They also seem to be devoted to providing an open ARM computing platform in working with Linux developers and Windows when compared with Apple. That they added a hypervisor to the 888 should give you some indication to their future compute ambitions...
mode_13h - Wednesday, April 28, 2021 - link
> I wouldn't put it past them to do a desktop or server sized SoCThe already tried this, but their investors killed it. Lookup "Centriq". Building out a whole server infrastructure & ecosystem takes a lot of investment, and now they'd have established competitors with a multi-year lead.
Raqia - Wednesday, April 28, 2021 - link
I wasn't talking about servers (at least not right away), more consumer oriented and workstation scale compute. Amon did say that the designs they had in mind with Nuvia were "scalable" and that they were going to be addressing multiple markets.mode_13h - Wednesday, April 28, 2021 - link
I hope you're right. If anyone can compete with Apple right now, it's probably Nuvia/Qualcomm.name99 - Thursday, April 29, 2021 - link
You need three things to create a higher performance core than Apple- designers (check)
- an implementation team (hmm. maybe? this means *enough* good people and superb simulation/design tools)
- management willing to pay the costs [design costs, and willing to accept a substantially larger core] (hmmmmmmmm? will they chicken out and assume no-one is willing to pay for such a core, they way they always have for watch, phone, then centriq?)
And Apple won't stand still...
mode_13h - Tuesday, April 27, 2021 - link
> so far except the HPE's A64FXGigabyte makes Altra motherboards and servers that I'm sure you can buy for less than a HPE A64FX-based machine.
And, if you're counting A64FX as a "consumer machine", you ought to include Avantek's Altra-based workstations that I mentioned below.
mode_13h - Tuesday, April 27, 2021 - link
> if these CPUs outperform the EPYC Milan technically AWS should replace all of them right ?No, because a lot of people are still stuck on x86. Also, Amazon could be fab-limited, like just about everyone else. The sun might be setting on x86, but it's still a long time until dark.
Rudde - Tuesday, April 27, 2021 - link
An Avantek Ampere workstation might be available in a stand-alone system. Andrei expects Ampere to include N2 in their next gen systems instead of V1. Apple might also launch something in that segment in the coming years.mode_13h - Tuesday, April 27, 2021 - link
A UK-based company called Avantek makes Ampere-based workstations. Their eMAG-based version was reviewed on this site, a couple years ago, and they now have one with Altra. So, I'd say better than average chances we might see one with a V1-based CPU by maybe the end of the year or so.