Intel Rocket Lake (14nm) Review: Core i9-11900K, Core i7-11700K, and Core i5-11600K
by Dr. Ian Cutress on March 30, 2021 10:03 AM EST- Posted in
- CPUs
- Intel
- LGA1200
- 11th Gen
- Rocket Lake
- Z590
- B560
- Core i9-11900K
CPU Tests: Microbenchmarks
Core-to-Core Latency
As the core count of modern CPUs is growing, we are reaching a time when the time to access each core from a different core is no longer a constant. Even before the advent of heterogeneous SoC designs, processors built on large rings or meshes can have different latencies to access the nearest core compared to the furthest core. This rings true especially in multi-socket server environments.
But modern CPUs, even desktop and consumer CPUs, can have variable access latency to get to another core. For example, in the first generation Threadripper CPUs, we had four chips on the package, each with 8 threads, and each with a different core-to-core latency depending on if it was on-die or off-die. This gets more complex with products like Lakefield, which has two different communication buses depending on which core is talking to which.
If you are a regular reader of AnandTech’s CPU reviews, you will recognize our Core-to-Core latency test. It’s a great way to show exactly how groups of cores are laid out on the silicon. This is a custom in-house test built by Andrei, and we know there are competing tests out there, but we feel ours is the most accurate to how quick an access between two cores can happen.
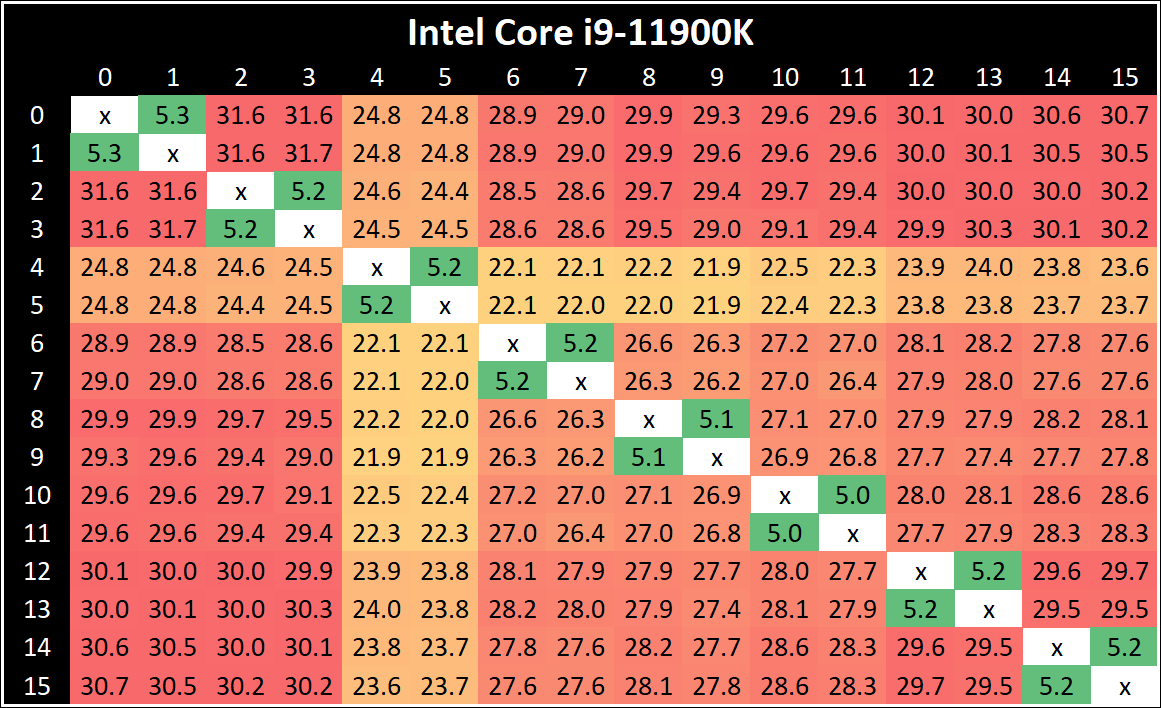
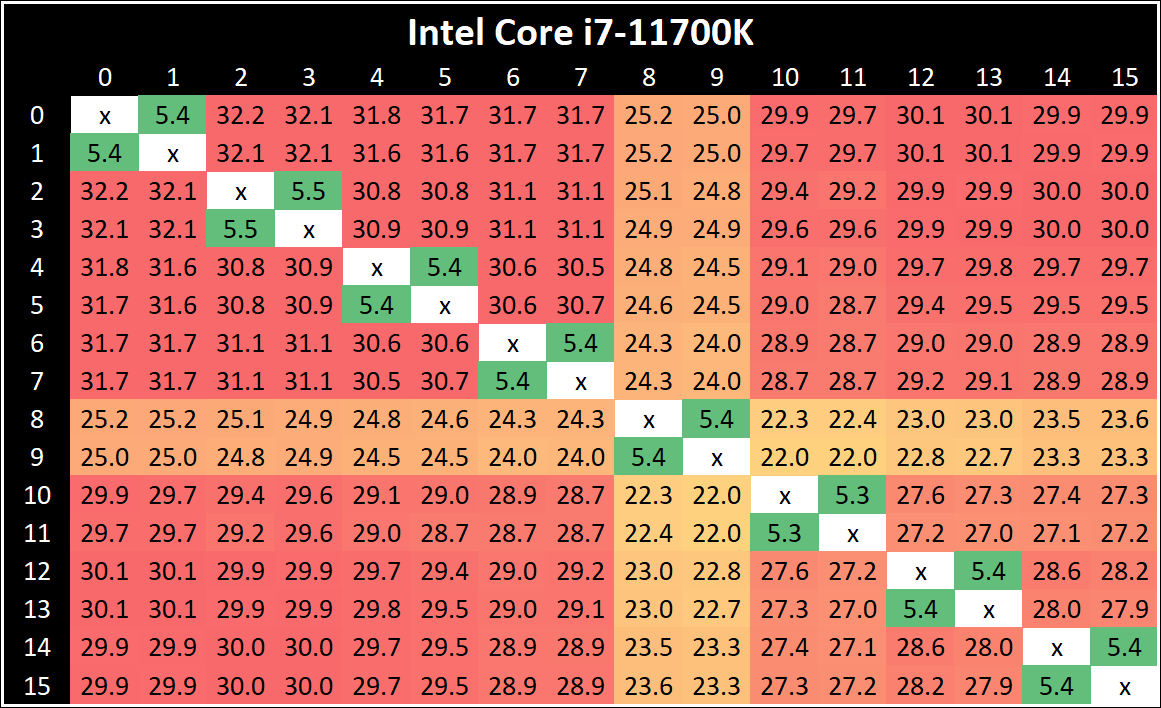

All three CPUs exhibit the same behaviour - one core seems to be given high priority, while the rest are not.
Frequency Ramping
Both AMD and Intel over the past few years have introduced features to their processors that speed up the time from when a CPU moves from idle into a high powered state. The effect of this means that users can get peak performance quicker, but the biggest knock-on effect for this is with battery life in mobile devices, especially if a system can turbo up quick and turbo down quick, ensuring that it stays in the lowest and most efficient power state for as long as possible.
Intel’s technology is called SpeedShift, although SpeedShift was not enabled until Skylake.
One of the issues though with this technology is that sometimes the adjustments in frequency can be so fast, software cannot detect them. If the frequency is changing on the order of microseconds, but your software is only probing frequency in milliseconds (or seconds), then quick changes will be missed. Not only that, as an observer probing the frequency, you could be affecting the actual turbo performance. When the CPU is changing frequency, it essentially has to pause all compute while it aligns the frequency rate of the whole core.
We wrote an extensive review analysis piece on this, called ‘Reaching for Turbo: Aligning Perception with AMD’s Frequency Metrics’, due to an issue where users were not observing the peak turbo speeds for AMD’s processors.
We got around the issue by making the frequency probing the workload causing the turbo. The software is able to detect frequency adjustments on a microsecond scale, so we can see how well a system can get to those boost frequencies. Our Frequency Ramp tool has already been in use in a number of reviews.
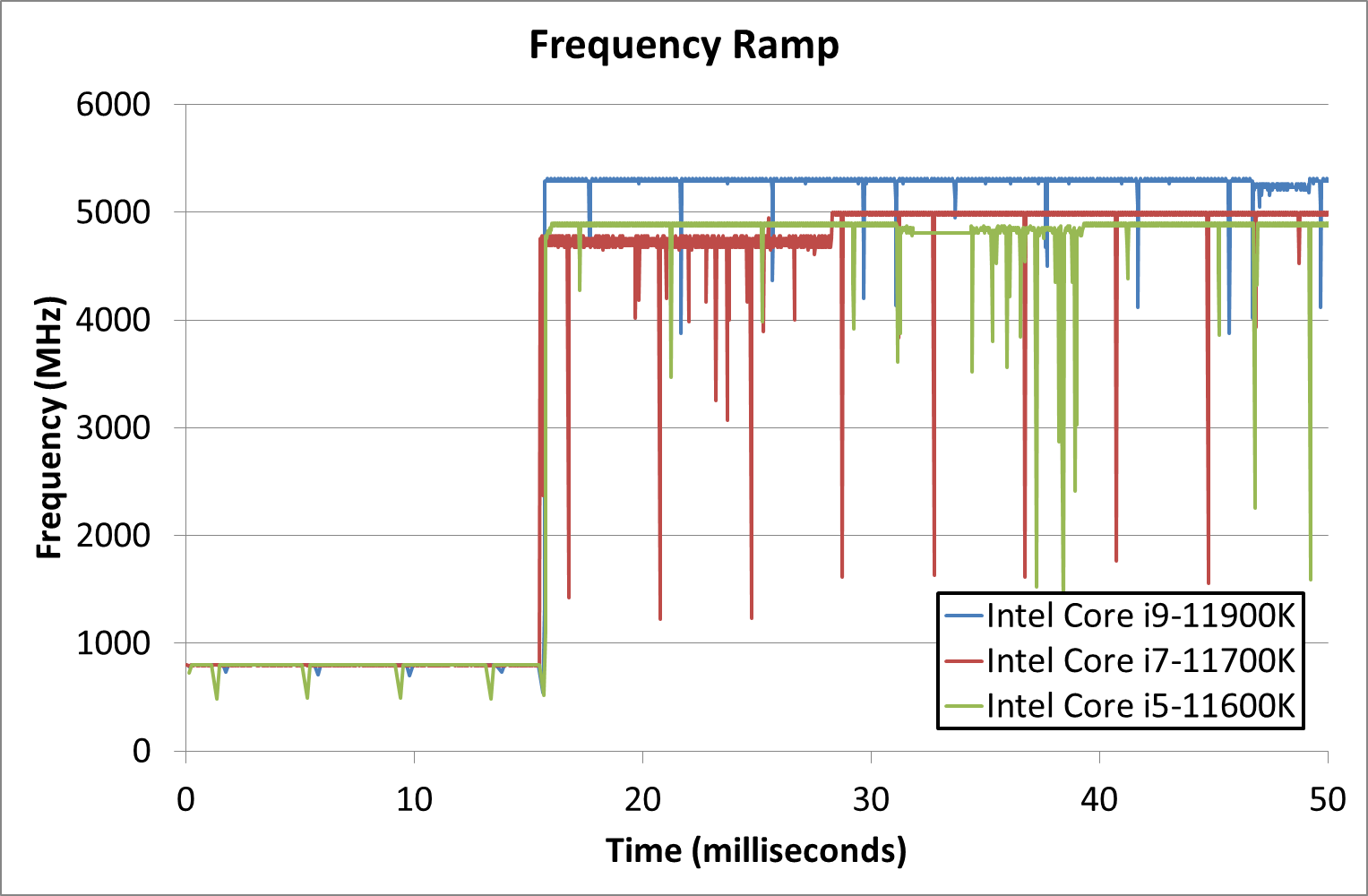
From an idle frequency of 800 MHz, It takes ~16 ms for Intel to boost to the top frequency for both the i9 and the i5. The i7 was most of the way there, but took an addition 10 ms or so.








279 Comments
View All Comments
SystemsBuilder - Tuesday, March 30, 2021 - link
Honestly, I think they just mislabeled the 11900k and 11700k in the first 3D Particle Movement v2.1 tests result OR it's thermal throttling because they are exactly the same but architecturally (11900k higher frequencies).But the whole topic of AVX512 is interesting. It looks like Intel did not release Cypress Cove AVX-512 architecture details like they did for Sunny Cove last year (and Skylake-X cores before). But if Cypress Cove is close enough to Sunny Cove (and tit should be), they have crippled the AVX-512 quite severely but to confirm that we need to see the official Intel slides on core design. I am specifically talking about that core port 5 is crippled in Sunny Cove (compared to what Skylake-X and Cascade lake-X have) and does not include a FMA, essentially cutting the throughput in half for FP32 and FP64 workloads. Port 5 do have a ALU so Integer workloads should be running at 100% compared to Skylake-X. I really like to see Cypress Cove AVX-512 back end architecture design at the port level from Intel to understand this better though.
GeoffreyA - Tuesday, March 30, 2021 - link
I believe they added an FMA to Port 5, and combining that one and the FMA from Port 0, create a single AVX512 "port," or rather the high- and low-order bits are dispatched to 5 and 0.https://www.anandtech.com/show/14514/examining-int...
https://en.wikichip.org/w/images/thumb/2/2d/sunny_...
GeoffreyA - Tuesday, March 30, 2021 - link
I'm not fully sure but think Cypress is just Willow, which in turn was just Sunny, with changes to cache. Truly, the Coves are getting cryptic, and intentionally so.SystemsBuilder - Tuesday, March 30, 2021 - link
The official intel slide posted on this page: https://www.anandtech.com/show/14514/examining-int... (specifically this slide: https://images.anandtech.com/doci/14514/BackEnd.jp... , shows what i'm talking about. The 2nd FMA is missing on port 5 but the ALU is there - 50% of FP compute power vs. Skylake-X architecture. The other slide on wikichip is contradicting official intel slide OR it only applies to server side with full Sunny Cove enabled (usually the consumer client side version is a cut down).In any case these slides are not Cypress Cove so the question remains what have they done to AVX-512 architecture port 0+1 and port 5.
GeoffreyA - Tuesday, March 30, 2021 - link
You're right. I didn't actually look at the Intel slide but was basing it more on the Wikichip diagram and Ian's text. Will be interesting if we can find that information on Cypress C.JayNor - Tuesday, March 30, 2021 - link
"My main interest is getting the fastest single-core AVX available..."Rumors within the last week say there will be Emerald Rapids HEDT chips next yr. Not sure about Ice Lake Server workstation chips. If either of these provide dual avx512 they might be worth the wait.
SystemsBuilder - Tuesday, March 30, 2021 - link
I'm thinking Sapphire Rapids, which is due to arrive in late 2021 (very best case or, more likely, 2022), is the one to hold out for. Build on the better performing 10nm Finfet, it will add PCIe 5.0, DDR5 and further improve on AVX 512 with BF16 and AMX Advanced Matrix Extensions https://fuse.wikichip.org/news/3600/the-x86-advanc...Now, if you read about this you realize what step up for (FP and int) compute that is. Massive!
scan80269 - Tuesday, March 30, 2021 - link
It looks like Rocket Lake is the first desktop class x86 processor to support hardware acceleration for AV1 video format decode, similar to Tiger Lake for mobile. Interesting how this power hungry processor family can deliver good energy efficiency when it comes to watching 4K HDR movies/videos. OTT platform providers need to offer more content encoded in AV1, though.Hifihedgehog - Tuesday, March 30, 2021 - link
Meh... This is a fixed-function IP block for a very specific task so it is going to be low power. At this point, for most people, HEVC support is what actually matters. HEVC already offers a 50% improvement in bitrate efficiency over H.264, and AV1 only claims the same thing. Royalties or not, because HEVC was first to the game, it became the industry standard for UHD/4K Blu-ray. Timing is everything and AV1 missed the boat on that by about five years. So with the industry locked into HEVC, AV1 is going to have an incredibly hard time getting uptake outside of online streaming, which is a whole other ball of wax. And even then, as a content creator, you can use HEVC royalty free anyway if you are livestreaming on YouTube.GeoffreyA - Tuesday, March 30, 2021 - link
While AV1's quality is excellent, surpassing that of HEVC, its encoding speed is impractical for most people,* and I'm doubtful whether it's going to get much better. If people (and pirates, yes) can't use it easily, its spread will be limited. The only advantage it has, which I can vouch for anecdotally, is superior quality to HEVC. But even this advantage will be short lived, once VVC enters the fray in the form of x266. I've got no idea how x266 will perform, but from testing the Fraunhofer encoder, saw that VVC and AV1 are in the same class, VVC being slightly ahead, sharper, and faster.* libaom, the reference encoder. Intel's SVT-AV1 is faster but has terrible quality.