The Ampere Altra Review: 2x 80 Cores Arm Server Performance Monster
by Andrei Frumusanu on December 18, 2020 6:00 AM EST- Posted in
- Servers
- Neoverse N1
- Ampere
- Altra
SPEC - Multi-Threaded Performance
While the single-threaded numbers were interesting, what we’re all looking after are the multi-core scores and what exactly 80 Neoverse-N1 cores can achieve within a single, and two sockets.
The performance measurements here were limited to quadrant and NPS4 configurations as that’s actually the default settings in which the Altra system came in, and what also AMD usually says customers want to deploy into production, achieving better performance by reducing cross-chip memory traffic.
The main comparison point here against the Q80-33 is AMD’s EPYC 7742 – 80 cores versus 64 cores with SMT, as well as similar TDPs. Intel’s Xeon 8280 with its 28 cores also comes into play but isn’t a credible competitor against the newer generation silicon designs on 7nm.
I’m keeping the detailed result sets limited to single-socket figures – we’ll check out the dual-socket numbers later on in the aggregate chart – essentially the 2S figures are simply 2x the performance.
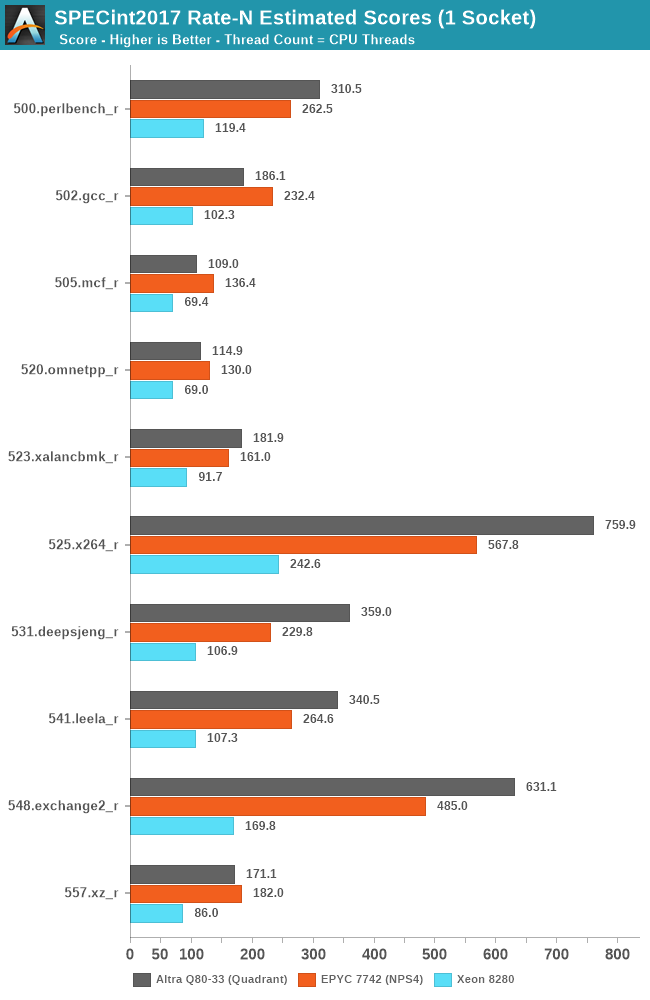
Starting off with SPECint2017, we’re seeing some absolutely smashing figures here on the part of the Altra Q80-33, with several workloads where the chip significantly outperforms the EPYC 7742, but also losing in some other workloads.
Starting off with the losing workloads, gcc, mcf, and omnetpp, these are all workloads with either high cache pressure or high memory requirements.
The Altra losing out in 502.gcc_r doesn’t come as much of a surprise as we also saw the Graviton2 suffering in this workload – the 1MB per core of L2 as well as 400KB per core of shared L3 really isn’t much and pales against the 4MB/core that’s available to the EPYC’s Zen2 cores. The Altra going from 2.5GHz to 3.3GHz and 64 cores to 80 cores only improves the score from 176.9 to 186.1 in comparison to the Graviton2. I’m not including the Graviton2 in the charts as it’s not quite the apples-to-apples comparisons due to compiler and run environments, but one can look up the scores in that review.
Where the Altra does shine however is in more core-local workloads that are more compute oriented and have less of a memory footprint, of which we see quite a few here, such as 525.x264.
What’s really interesting here is that even though the latter tests in the suite are extremely friendly to SMT scaling on the x86 systems, with 531, 541, 548 and 557 scaling up with SMT threads in MT performance by respectively 30, 43, 25 and 36%, AMD’s Rome CPU still manages to lose to the Altra system by considerable amounts – only being slightly favoured in 557.xz_r by a slight margin – so while SMT helps, it’s not enough to counteract the raw 25% core count advantage of the Altra system when comparing 80 vs 64 cores.
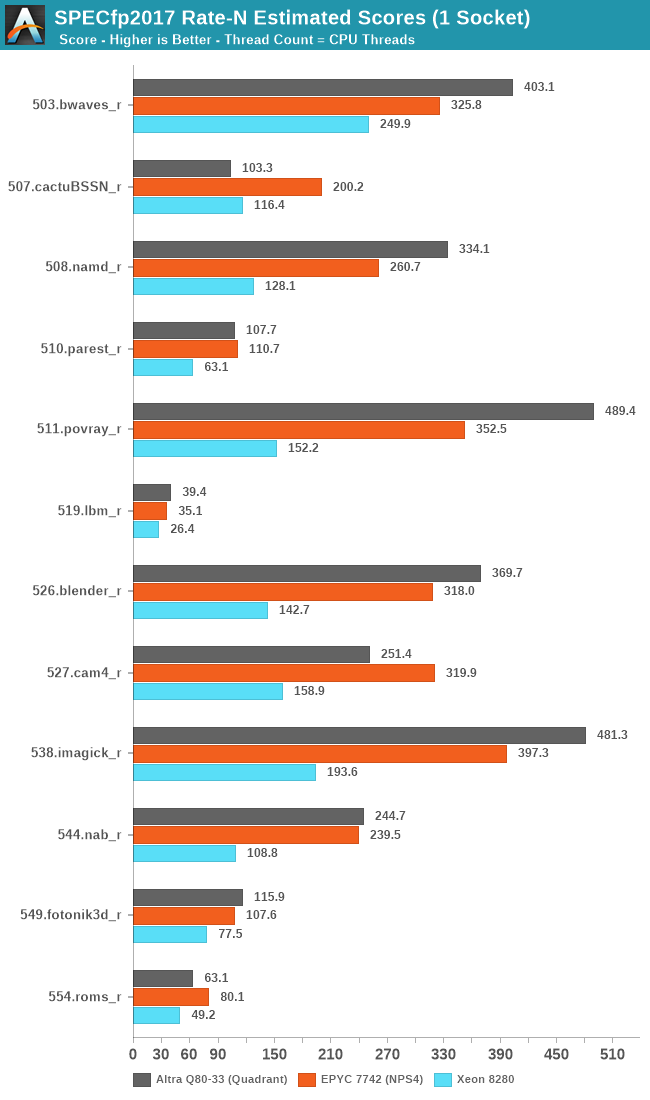
In SPECfp2017, things are also looking favourably for the Altra, although the differences aren’t as favourable except for 511.povray where the raw core count again comes into play.
The Altra again showcases really bad performance in 507.cactuBSSN_r, mirroring the lacklustre single-threaded scores and showing worse performance than a Graviton2 by considerable amounts.
The Arm design does well in 503.bwaves which is fairly high IPC as well as bandwidth hungry, however falls behind in other bandwidth hungry workloads such as 554.roms_r which has more sparse memory stores.
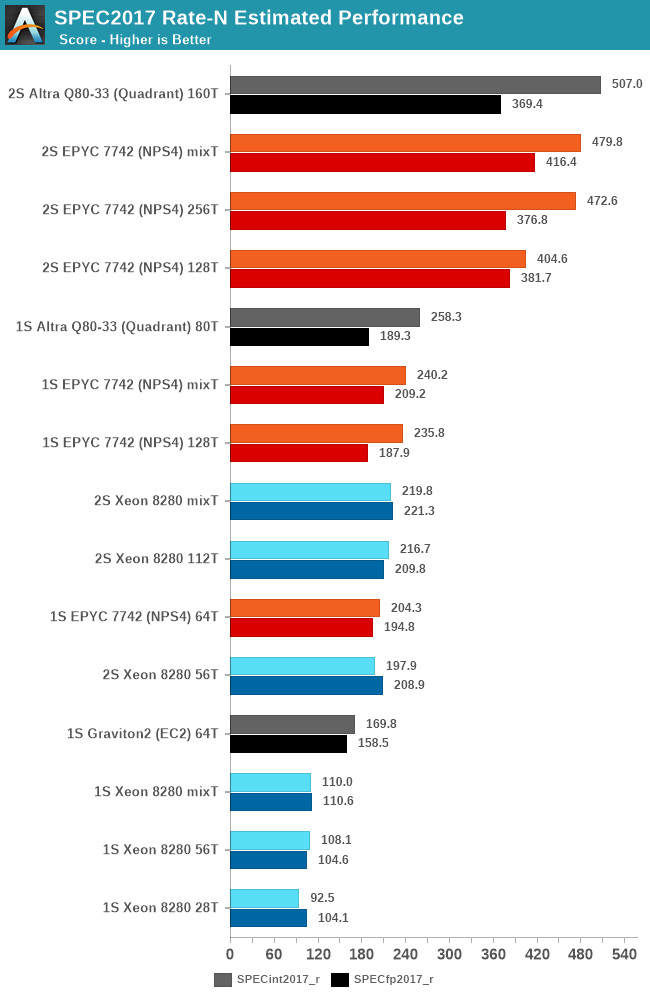
In the overall scores, both across single-socket and dual-socket systems, the new Altra Q80-33 performs outstandingly well, actually edging out the EPYC system by a small margin in SPECint, though it’s losing out in SPECfp and more cache-heavy workloads.
Beyond testing 1-socket and 2-socket scores, I’ve also taken the opportunity of this new round of testing across the various systems to test out 1 thread per core and 2 thread per core scores across the SMT systems.
While there are definitely workloads that scale well with SMT, overall, the technology has a smaller impact on the suite, averaging out at 15% for both EPYC and Xeon.
One thing we don’t usually do in the way we run SPEC is mixing together rate figures with different thread counts, however with such large core counts and threads it’s something I didn’t want to leave out for this piece. The “mixT” result set takes the best performing sub-score of either the 1T or 2T/core runs for a higher overall aggregate. Usually officially submitted SPEC scores do this by default in their _peak submissions while we usually run _base comparative scores. Even with this best-case methodology for the SMT systems, the Altra system still slightly edges out the performance of the EPYC 7742.
Intel’s Cascade Lake Xeon system here really isn’t of any consideration in the competitive landscape as a single-socket Altra system will outperform a dual-socket Xeon.
The Altra QuickSilver still has one weakness and that’s cache-heavy workloads – 32MB of L3 for 80 cores really isn’t near enough to keep up performance scaling across that many cores. In the end of the day however, it’s up to Ampere’s customers to give input what kind of workloads they use and if they stress the caches or not – given that both Amazon and Ampere chose the minimum cache configuration for their mesh implementations, maybe that’s not the case?
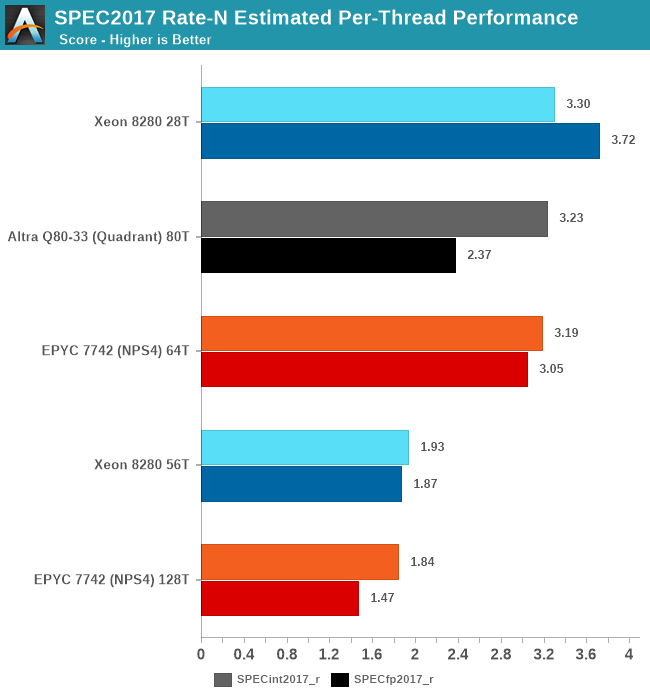
Finally, one last figure I wanted to showcase is the per-thread performance of the different designs. While scaling out multi-threaded performance across vast number of cores is a very important way to scale performance, it’s also important to not take a flock of chickens approach with too weak cores. Especially for customers Ampere is targeting, such as enterprise and cloud service providers, many times users will be running things on a subset of a given processor socket cores, so per-core and per-thread performance remains a very important metric.
Simply dividing the single-socket performance figures by the amount of threads run, we get to an average per-thread performance figure in the context of a fully loaded system, a figure that’s actually more realistic than the single-thread figures of the previous page where the rest of the CPU cores in the systems are doing nothing.
In this regard, Intel’s Xeon offering is still extremely competitive and actually takes the lead position here – although its low core count doesn’t favour it at all in the full throughput metrics of the socket, the per-thread performance is still the best amongst the current CPU offerings out there.
In SPECint, the Altra, EPYC and Xeon are all essentially tied in performance, whilst in SPECfp the Xeon takes the lead with the Altra falling notably behind – with the EPYC Rome chip falling in-between the two.
If per-thread performance is important to you, then obviously enough SMT isn’t an option as this vastly regresses performance in favour of a chance to get more aggregate performance across multiple threads. There’s many vendors or enterprise use-cases which for this reason just outright disable SMT.








148 Comments
View All Comments
Andrei Frumusanu - Sunday, January 3, 2021 - link
I actually did test those setups:2S Q64-33 setup: 433.7 SPECint2017 - 341.7 SPECfp2017
Pyxar - Wednesday, December 23, 2020 - link
This is cool and all but what could an arm processor server be used for? Aside from some linux compilations there isn't that much support for arm processors.This is looking a lot like the early days of computing where BeBox was powered by PowerPC cpu, a system looking to find a niche that doesn't exist (yet). It was cool for it's time but very little demand for it.
mode_13h - Wednesday, December 23, 2020 - link
Pretty much everything needed to run modern web services has been ported to ARM. I believe a number of high-profile sites are now using Amazon Graviton2, due to its pricing advantage.As for client computing, the Pi has emerged as a basic, usable desktop platform.
mode_13h - Thursday, December 24, 2020 - link
Also, a couple years ago, Nvidia announced support for their entire software stack on ARM host CPUs. So, I'd say it should also be a decent platform for machine learning, now.Bytales - Wednesday, December 23, 2020 - link
You should have tested some CPU mining bechmarks like Monero's randomX, Wownero's randomwow, Turtle's argon2id Chukwa v2, and DERO's AstroBWT. That would have been interesting as shieeet.Miguelxataka - Sunday, January 3, 2021 - link
7742 (15 months ago release) 225w 67.000 point passmark??? why?? 7702 200w 71.000 points passmark. With 7702 the comparision!!7702 (200w) Zen 2 vs Ampere (250w). 20% less power consumption + with Zen 3 20% extra power consumption =36%?
Where are the power efficiency of the RISC/ARM processors here?
Rance - Friday, July 16, 2021 - link
For the specjbb 2015 data, what was the baseline pagesize set to?4KB/64KB/?
Thanks!
sunwins - Tuesday, October 12, 2021 - link
I guess the speccpu2017 test result is wrong.Maybe there were some problems such as bios version or speccpu software configuration.Reference link:
https://www.spec.org/cpu2017/results/rfp2017.html
https://www.spec.org/cpu2017/results/rint2017.html
AMD 7742 speccpu2017 intrate official value:353 per socket
AMD 7742 speccpu2017 intfp official value:270 per socket
INTEL 8280 speccpu2017 intrate official value:172 per socket
INTEL 8280 speccpu2017 intfp official value:141 per socket
Ampere Q80-33 offcial speccpu2017 intrate value:300 per socket
if you hava any question or updation,please touch 799517515@qq.com。