The Ampere Altra Review: 2x 80 Cores Arm Server Performance Monster
by Andrei Frumusanu on December 18, 2020 6:00 AM EST- Posted in
- Servers
- Neoverse N1
- Ampere
- Altra
Compiling LLVM, NAMD Performance
As we’re trying to rebuild our server test suite piece by piece – and there’s still a lot of work go ahead to get a good representative “real world” set of workloads, one more highly desired benchmark amongst readers was a more realistic compilation suite. Chrome and LLVM codebases being the most requested, I landed on LLVM as it’s fairly easy to set up and straightforward.
git clone https://github.com/llvm/llvm-project.gitcd llvm-projectgit checkout release/11.xmkdir ./buildcd ..mkdir llvm-project-tmpfssudo mount -t tmpfs -o size=10G,mode=1777 tmpfs ./llvm-project-tmpfscp -r llvm-project/* llvm-project-tmpfscd ./llvm-project-tmpfs/buildcmake -G Ninja \ -DLLVM_ENABLE_PROJECTS="clang;libcxx;libcxxabi;lldb;compiler-rt;lld" \ -DCMAKE_BUILD_TYPE=Release ../llvmtime cmake --build .We’re using the LLVM 11.0.0 release as the build target version, and we’re compiling Clang, libc++abi, LLDB, Compiler-RT and LLD using GCC 10.2 (self-compiled). To avoid any concerns about I/O we’re building things on a ramdisk – on a 4KB page system 5GB should be sufficient but on the Altra’s 64KB system it used up to 9.5GB, including the source directory. We’re measuring the actual build time and don’t include the configuration phase as usually in the real world that doesn’t happen repeatedly.
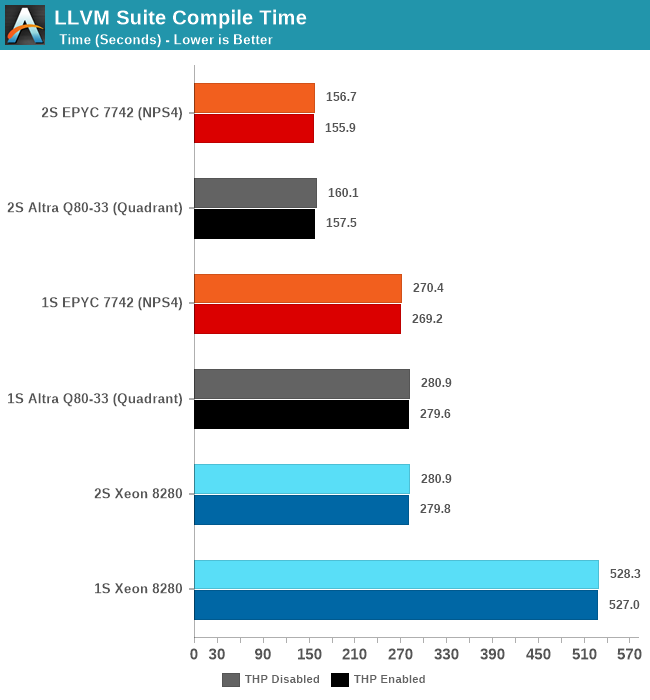
The Altra Q80-33 here performs admirably and pretty much matches the AMD EPYC 7742 both in 1S and 2S configurations. There isn’t exact perfect scaling between sockets because this being a actual build process, it also includes linking phases which are mostly single-threaded performance bound.
Generally, it’s interesting to see that the Altra here fares better than in the SPEC 502.gcc_r MT test – pointing out that real codebases might not be quite as demanding as the 502 reference source files, including a more diverse number of smaller files and objects that are being compiled concurrently.
NAMD
Another rather popular benchmark tool that we’ve actually seen being used by vendors such as AMD in their marketing materials when showcasing HPC performance for their server chips is NAMD. This actually quite an interesting adventure in terms of compiling the tool for AArch64 as essentially there little to no proper support for it. I’ve used the latest source drop, essentially the 2.15alpha / 3.0alpha tree, and compiled it from scratch on GCC 10.2 using the platform’s respective -march and -mtune targets.
For the Xeon 8280 – I did not use the AVX512 back-end for practical reasons: The code which introduces an AVX512 algorithm and was contributed by Intel engineers to NAMD has no portability to compilers other than ICC. Beyond this being a code-path that has no relation with the “normal” CPU algorithm – the reliance on ICC is something that definitely made me raise my eyebrows. It’s a whole other discussion topic on having a benchmark with real-world performance and the balance of having an actual fair and balanced apple to apples comparison. It’s something to revisit in the future as I invest more time into looking the code and see if I can port it to GCC or LLVM.
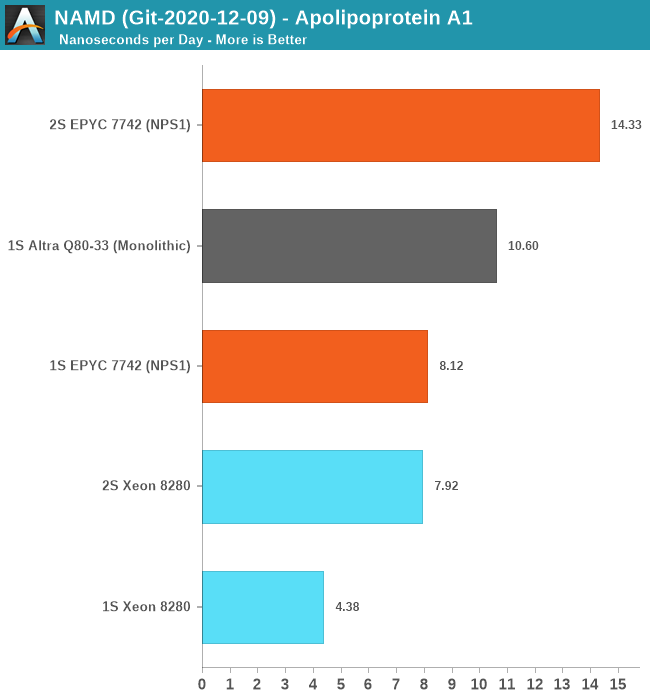
For the single-socket numbers – we’re using the multicore variant of the tool which has predictable scaling across a single NUMA node. Here, the Ampere Altra Q80-33 performed amazingly well and managed to outperform the AMD EPYC 7742 by 30% - signifying this is mostly a compute-bound workload that scales well with actual cores.
For the 2S figures, using the multicore binaries results in undeterministic performance – the Altra here regressed to 2ns/day and the EPYC system also crashed down to 4ns/day – oddly enough the Xeon system had absolutely no issue in running this properly as it had excellent performance scaling and actually outperforms the MPI version. The 2S EPYC scales well with the MPI version of the benchmark, as expected.
Unfortunately, I wasn’t able to compile an MPI version of NAMD for AArch64 as the codebase kept running into issues and it had no properly maintained build target for this. In general, I felt like I was amongst the first people to ever attempt this, even though there are some resources to attempt to help out on this.
I also tried running Blender on the Altra system but that ended up with so many headaches I had to abandon the idea – on CentOS there were only some really old build packages available in the repository. Building Blender from source on AArch64 with all of its dependencies ends up in a plethora of software packages which simply assume you’re running on x86 and rely on basic SSE intrinsics – easy enough to fix that in the makefiles, but then I hit some other compilation errors after which I lost my patience. Fedora Linux seemed to be the only distribution offering an up-to-date build package for Blender – but I stopped short of reinstalling the OS just to benchmark Blender.
So, while AArch64 has made great strides in the past few years – and the software situation might be quite good for server workloads, it’s not all rosy and we’re still have ways to go before it can be considered a first-class citizen in the software ecosystem. Hopefully Apple’s introduction of Apple Silicon Macs will accelerate the Arm software ecosystem.








148 Comments
View All Comments
SarahKerrigan - Friday, December 18, 2020 - link
Looks like the LLVM compile time graph has "Quadrant" twice when one of the graph labels should be "Monolithic."Andrei Frumusanu - Friday, December 18, 2020 - link
No, that's correct. Both 1S and 2S figures were run in quadrant modes.SarahKerrigan - Friday, December 18, 2020 - link
You're absolutely right - I'm apparently illiterate and ignored the socket count.cbm80 - Friday, December 18, 2020 - link
Says "KOREA"...so made by Samsung?jeremyshaw - Friday, December 18, 2020 - link
probably just packaging.danbob999 - Friday, December 18, 2020 - link
Does the price of the CPU matters at this point? It's not as if you are going to build your own system isn't it? Isn't buying the whole computer the only option? Do they sell motherboards as well?Spunjji - Monday, December 21, 2020 - link
People like to talk about how RAM costs rapidly sink the cost of the CPU *as a proportion of total cost*, which is true, but saving $2000 per socket still adds up when you're buying a fair few of them. Saving hundreds of thousands of dollars on a datacentre build-out (and with no significant performance downsides) is good financial sense, even if you're still spending millions overall.kepstin - Friday, December 18, 2020 - link
I really want to see what would happen if an M1-based design got scaled down to something suitable for a workstation.I think something like that is needed in order to solve problems like what you were running into with Blender - until we have decent high performance aarch64 workstations on developer's desks, x86-64 is gonna be ahead on software support.
jeremyshaw - Friday, December 18, 2020 - link
Yeah, I guess we all have to just wait for Apple.*technically* Nvidia did and does sell Jetson boards in that range (they even delivered the first consumer accessible PCIe 4.0 root, in the AGX Xavier), but Nvidia's insistence on locking everything down to an ancient kernel basically kills any hope of it being used outside of specific fields. Even something as simple as their teams keeping up with LTS releases would be somewhat viable, but nope. Even Raspberry Pi foundation is far ahead of them, now.
I think they are still trying to upgrade their bootloader to allow booting from NVMe cards? At least their AGX Xavier is finally picking up beta UEFI support (which should help somewhat).
I guess they would rather Apple eat their lunch. Oh, well.
mode_13h - Sunday, December 20, 2020 - link
Nvidia is selling those for robotics and stuff. Apple is not trying to eat that lunch.