The 2020 Mac Mini Unleashed: Putting Apple Silicon M1 To The Test
by Andrei Frumusanu on November 17, 2020 9:00 AM ESTRosetta2: x86-64 Translation Performance
The new Apple Silicon Macs being based on a new ISA means that the hardware isn’t capable of running existing x86-based software that has been developed over the past 15 years. At least, not without help.
Apple’s new Rosetta2 is a new ahead-of-time binary translation system which is able to translate old x86-64 software to AArch64, and then run that code on the new Apple Silicon CPUs.
So, what do you have to do to run Rosetta2 and x86 apps? The answer is pretty much nothing. As long as a given application has a x86-64 code-path with at most SSE4.2 instructions, Rosetta2 and the new macOS Big Sur will take care of everything in the background, without you noticing any difference to a native application beyond its performance.
Actually, Apple’s transparent handling of things are maybe a little too transparent, as currently there’s no way to even tell if an application on the App Store actually supports the new Apple Silicon or not. Hopefully this is something that we’ll see improved in future updates, serving also as an incentive for developers to port their applications to native code. Of course, it’s now possible for developers to target both x86-64 and AArch64 applications via “universal binaries”, essentially just glued together variants of the respective architecture binaries.
We didn’t have time to investigate what software runs well and what doesn’t, I’m sure other publications out there will do a much better job and variety of workloads out there, but I did want to post some more concrete numbers as to how the performance scales across different time of workloads by running SPEC both in native, and in x86-64 binary form through Rosetta2:
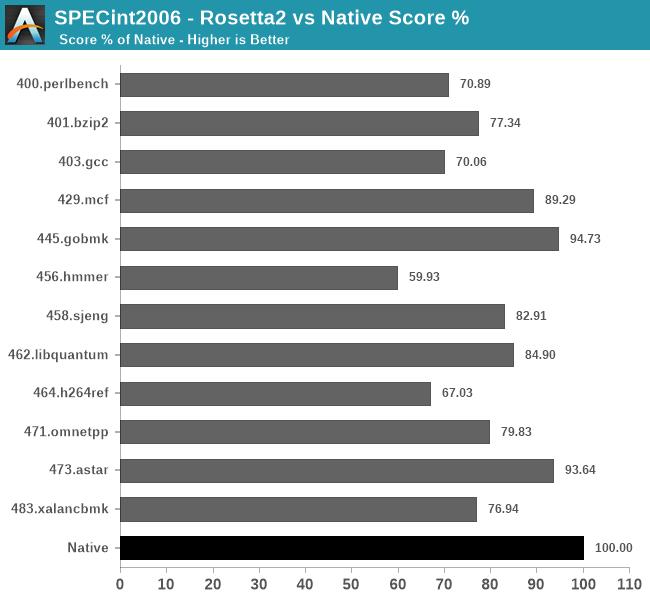
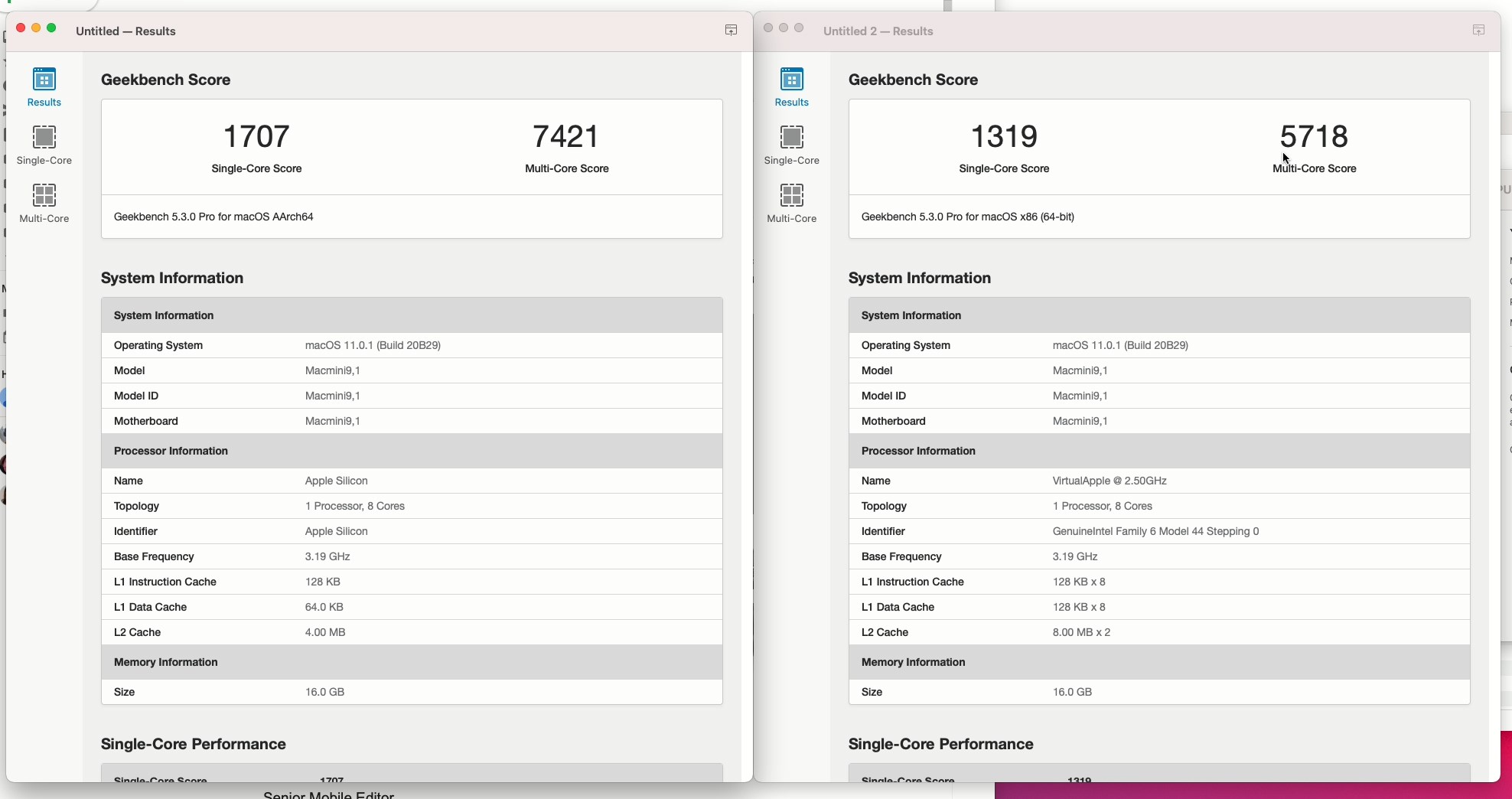
In SPECint2006, there’s a wide range of performance scaling depending on the workloads, some doing quite well, while other not so much.
The workloads that do best with Rosetta2 primarily look to be those which have a more important memory footprint and interact more with memory, scaling perf even above 90% compared to the native AArch64 binaries.
The workloads that do the worst are execution and compute heavy workloads, with the absolute worst scaling in the L1 resident 456.hmmer test, followed by 464.h264ref.
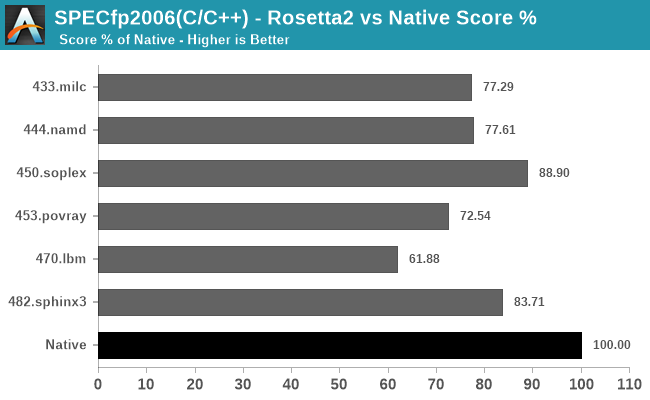
In the fp2006 workloads, things are doing relatively well except for 470.lbm which has a tight instruction loop.
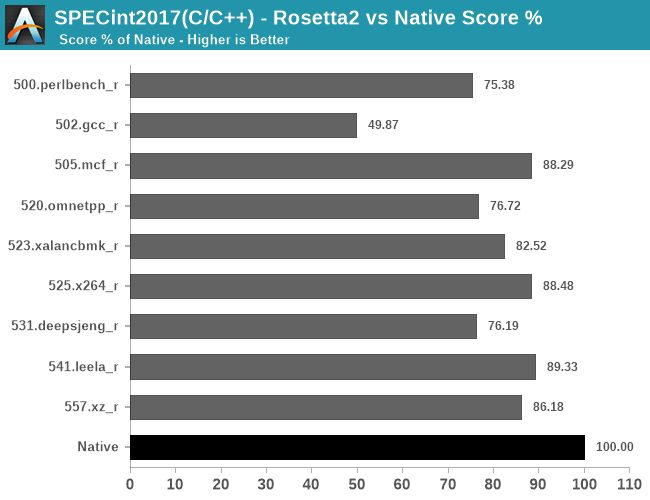
In the int2017 tests, what stands out is the horrible performance of 502.gcc_r which only showcases 49.87% performance of the native workload – probably due to high code complexity and just overall uncommon code patterns.
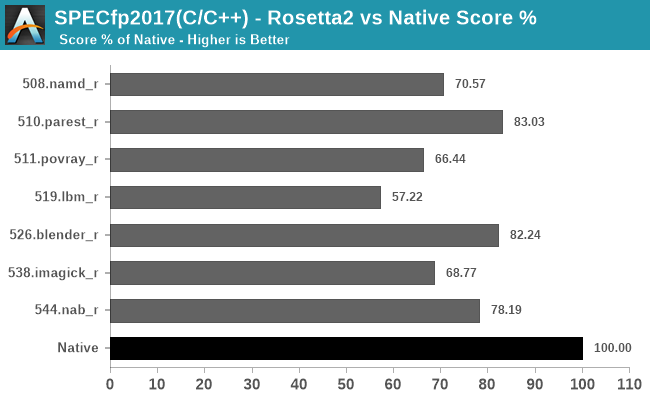
Finally, in fp2017, it looks like we’re again averaging in the 70-80% performance scale, depending on the workload’s code.
Generally, all of these results should be considered outstanding just given the feat that Apple is achieving here in terms of code translation technology. This is not a lacklustre emulator, but a full-fledged compatibility layer that when combined with the outstanding performance of the Apple M1, allows for very real and usable performance of the existing software application repertoire in Apple’s existing macOS ecosystem.








682 Comments
View All Comments
Spunjji - Monday, November 23, 2020 - link
@Kangal - I have a few disagreements with what you've written here.Firstly, I'm a little confused about why you see the Rosetta-based benchmarks as most relevant. I doubt that anyone buying an M1 device today will be getting rid of it before the majority of apps are converted across, so that performance is going to become increasingly *less* relevant as time passes.
Secondly, this quote: "In short, Apple played it safe and didn't really do their best. That means they purposely left performance on the table, it was artificial and it was deliberate." - I just don't see how you could draw that conclusion. They used their highest-performing cores in the largest chip yet produced on 5nm. It would be bizarre for them to begin such a grand experiment from the top-down - it would produce an odd situation where their most demanding users, who are most likely to be using applications that currently need translation, would be expected to transition to an incomplete ecosystem with performance that doesn't exceed existing systems.
To me, it makes perfect sense from both an engineering and a product perspective. They begin the transition with a relatively small (and thus high-yielding, despite the new process) chip as part of a platform for users who are relatively performance-insensitive, but who will still appreciate the immediate benefits of reduced heat and increased battery life.
I'm also a bit confused about your perspective on their GPU. AFAIK the most modern low-profile low-power GPU out there is Nvidia's 1650 - and in terms of performance-per-watt, this iGPU thrashes it, with absolute performance being not far behind. Perf/Watt appears to be Apple's primary concern (for a given degree of absolute performance), so I see it as a resounding (and surprising) success. It's down to AMD and Nvidia to respond now.
Kangal - Wednesday, November 25, 2020 - link
@SpunjjiThanks for the read, sorry it's quite long.
I mean, the Apple Silicon M1 as it is, it's very good for the new Macbook Air. I guess for the cheap/budget Mac Mini it is also decent. However, it's kind of out of place on the Pro. Perhaps they will launch more Macs in the next 6 months, something beefy for their larger MacBook Pro, and maybe something desktop-worthy in an iMac and Mac Pro. I completely agree with your points. Apple now has the best chipset in the world, their large cores are highly competitive, and their GPU tech is the most efficient. In fact, their medium-cores are the best, they're an Out-of-order processor which sucks slightly less power than a Cortex A53 (or slightly more than A55 ?), but they're slightly faster than a Cortex A73 (or slightly slower than A72 ?). Either way, that's stupidly impressive.
But as it stands, Apple has done the works but on the last yard, pulled its punches.... and I state that since they're saving money on the SoC by sourcing it themselves, and not paying those exorbitant Intel prices. So there's definitely (money and silicon) budget there to go more ambitious. I just wanted to see more competitive/better product segmentation, eg:
Apple M10, ~10W, 8 large cores, 8cu GPU... for 11in laptop, ultra thin, fanless
Apple M13, ~15W, 8 large cores, 16cu GPU... for 14in laptop, thin, active cooled
Apple M15, ~25W, 8 large cores, 32cu GPU... for 17in laptop, thick, active cooled
Apple M17, ~45W, 16 large cores, 32cu GPU... for 29in iMac, thick, AC power
Apple M19, ~95W, 16 large cores, 64cu GPU.... for Mac Pro, desktop, strong cooling
...and after 1.5 years, they can move unto the next refined architecture/node (ex Apple M20, M23, M25, M27, M29 etc etc).
Sherlock - Monday, November 30, 2020 - link
I believe the iPad Pros (if not all iPads) will move to the M1 chip and run the MacOS with the ability to run iPadOS/iOS Apps. With the detachable keyboards and Apple Pen support - they will become the ultimate Portable workstation. Knowing Apple's penchant for a limited product line - they may even drop the Apple Macbook Air.BushLin - Saturday, November 21, 2020 - link
"To be honest, a lot of comparisons of the Apple Silicon M1 are vague, misrepresentative or blatantly off..."<proceeds to list unattributed benchmark results with incorrect power labels>
Spunjji - Thursday, November 19, 2020 - link
@vlad24 - I'm aware of how process node can affect voltage requirements and power draw, and the various TDP differences.I wasn't arguing that TSMC 5nm wouldn't help AMD's power efficiency, I was arguing with the nonsensical statement that it's the *sole reason* for Apple's good showing in that area. lilmoe's salty opinions aren't supported by the facts.
You're correct that AMD at 5nm would probably regain an advantage over M1 in mobile devices, but that will be in a year's time, and Apple aren't standing still. It's likely we'll be seeing them leapfrog each other. In the meantime, it'll be interesting to see how competitive Cezanne ends up being with M1 and/or whatever Apple's next-largest chip will end up being.
vlad42 - Saturday, November 21, 2020 - link
But if shrinking Zen 3 to the same 5nm process would make its mobile variant more energy efficient, then that would imply that Zen 3 is a more efficient architecture. It just happens that the architecture is held back in this specific comparison by the manufacturing process.We do not know if AMD will bother to port Zen 3 to 5nm, they could skip straight to Zen 4. Who knows what process Apple will be using by the time AMD moves to 5nm. 3nm could still be too expensive for chips larger than those used for phones.
Granted if the energy efficiency of Zen 3 equals M1 when both are on 5nm, then the M1's efficiency cannot be solely due to 5nm unless that were also true for Zen 3.
mdriftmeyer - Saturday, November 21, 2020 - link
Zen 4 is scheduled to have samples Q1 2021 on 5nm advanced node TSMC. The fact you don't know this tells me you don't follow AMD.Spunjji - Monday, November 23, 2020 - link
@mdriftmeyer - You'd be wrong in both assuming that I don't know and that I don't "follow AMD". Samples in Q1 2021 does not equal released product in Q1 2021, does it? I'm talking about product availability, and you're moving the goalposts for reasons that aren't clear to me.magreen - Tuesday, November 24, 2020 - link
@Spunjji - Thanks for your insightful responses, as usual. Sometimes I'm tempted to just hit Ctrl-F to find your comments and ignore the rest.haghands - Tuesday, November 17, 2020 - link
Cope