The 2020 Mac Mini Unleashed: Putting Apple Silicon M1 To The Test
by Andrei Frumusanu on November 17, 2020 9:00 AM ESTRosetta2: x86-64 Translation Performance
The new Apple Silicon Macs being based on a new ISA means that the hardware isn’t capable of running existing x86-based software that has been developed over the past 15 years. At least, not without help.
Apple’s new Rosetta2 is a new ahead-of-time binary translation system which is able to translate old x86-64 software to AArch64, and then run that code on the new Apple Silicon CPUs.
So, what do you have to do to run Rosetta2 and x86 apps? The answer is pretty much nothing. As long as a given application has a x86-64 code-path with at most SSE4.2 instructions, Rosetta2 and the new macOS Big Sur will take care of everything in the background, without you noticing any difference to a native application beyond its performance.
Actually, Apple’s transparent handling of things are maybe a little too transparent, as currently there’s no way to even tell if an application on the App Store actually supports the new Apple Silicon or not. Hopefully this is something that we’ll see improved in future updates, serving also as an incentive for developers to port their applications to native code. Of course, it’s now possible for developers to target both x86-64 and AArch64 applications via “universal binaries”, essentially just glued together variants of the respective architecture binaries.
We didn’t have time to investigate what software runs well and what doesn’t, I’m sure other publications out there will do a much better job and variety of workloads out there, but I did want to post some more concrete numbers as to how the performance scales across different time of workloads by running SPEC both in native, and in x86-64 binary form through Rosetta2:
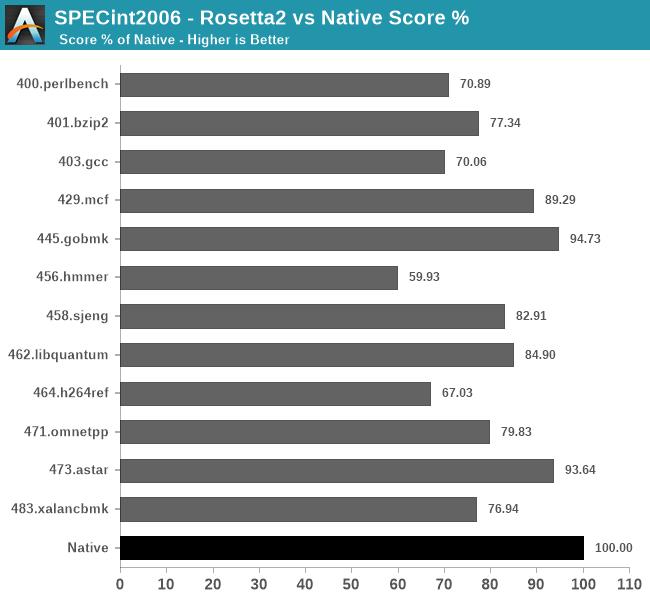
In SPECint2006, there’s a wide range of performance scaling depending on the workloads, some doing quite well, while other not so much.
The workloads that do best with Rosetta2 primarily look to be those which have a more important memory footprint and interact more with memory, scaling perf even above 90% compared to the native AArch64 binaries.
The workloads that do the worst are execution and compute heavy workloads, with the absolute worst scaling in the L1 resident 456.hmmer test, followed by 464.h264ref.
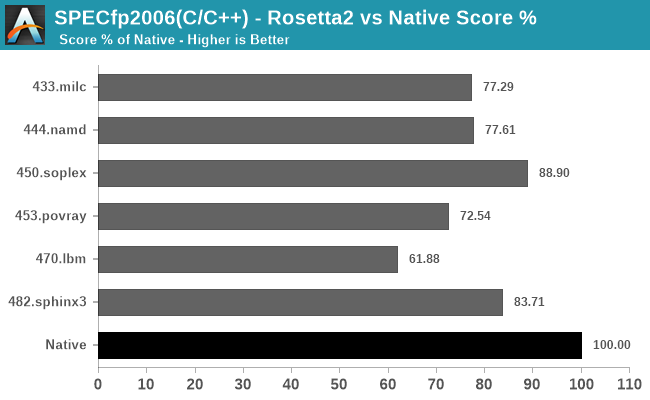
In the fp2006 workloads, things are doing relatively well except for 470.lbm which has a tight instruction loop.
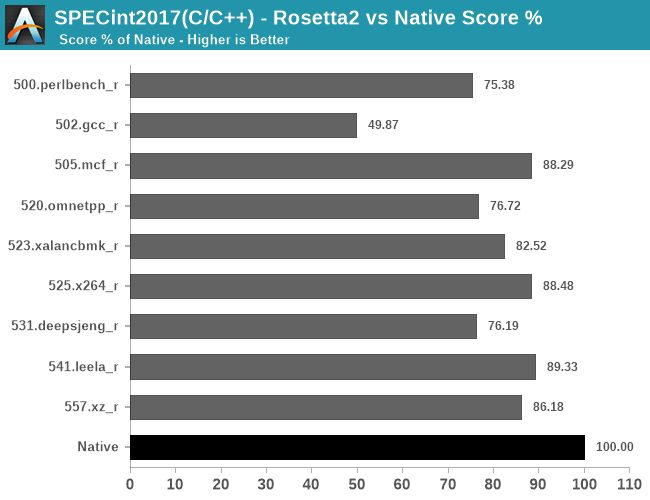
In the int2017 tests, what stands out is the horrible performance of 502.gcc_r which only showcases 49.87% performance of the native workload – probably due to high code complexity and just overall uncommon code patterns.
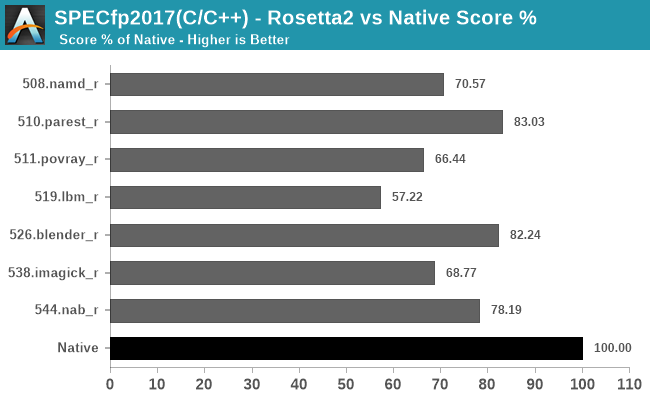
Finally, in fp2017, it looks like we’re again averaging in the 70-80% performance scale, depending on the workload’s code.
Generally, all of these results should be considered outstanding just given the feat that Apple is achieving here in terms of code translation technology. This is not a lacklustre emulator, but a full-fledged compatibility layer that when combined with the outstanding performance of the Apple M1, allows for very real and usable performance of the existing software application repertoire in Apple’s existing macOS ecosystem.








682 Comments
View All Comments
BushLin - Wednesday, November 18, 2020 - link
8-core mobile zen 2 chips have been available for nearly a year now. By the time you can buy that unannounced product you speculate about, it'll be competing against 5nm zen 4 and would still be a toss up in performance against 7nm zen 2.Spunjji - Thursday, November 19, 2020 - link
You're both wrong.Zen 4 is due out in at least a year's time, possibly 18 months. I'll eat my hat if Apple haven't released their higher-end chip with larger cores by then.
That said, there's no reason to assume its CPU performance will be significantly higher than AMD's mobile Zen 3 designs. GPU will be for sure, but you're locked to a platform without access to decent games so that will limit the appeal to a certain audience.
So it's not "game over" for Zen 3 - especially as they don't directly compete - but BushLin's completely wrong about how an 8-core variant of this would stack up to Zen 2 and 3.
BushLin - Thursday, November 19, 2020 - link
So a 15W 8-core zen 2 beats a 15W 4+4 core M1 in multithreaded, close to real world tests; but a mythical 25-30W 8+4 CPU using the same design which hasn't scaled well from the additional watts it uses over the A14 chip is going to definitely, defiantly and majestically beat all comers, including zen 3? We'll see but random guy on the internet is probably just pulling stuff out of their ass.Spunjji - Monday, November 23, 2020 - link
@BushLin - Please check what I said again: "there's no reason to assume [M1's] CPU performance will be significantly higher than AMD's mobile Zen 3 designs". So no, I don't think it's going to "definitely, defiantly and majestically beat all comers, including zen 3" and you're kind of an ass for straw-manning me like that. Please don't.You keep making false comparisons with TDP too. Zen 2 is 15W at base clocks, but most of the tests seen so far take place largely within its turbo window of ~30W. Zen 3 Cezanne on 7nm will be in the same ballpark. A theoretical (not "mythical") 8+4 design should provide very similar performance in a very similar TDP, with the performance edge likely going to AMD. That indicates than Zen 4 on 5nm should likely be a superior option for both perf/watt and absolute performance, but we just don't know that yet as, in your terms, Zen 4 is still "mythical".
But sure, equally-random guy on the internet. We'll see when we see.
BushLin - Monday, November 23, 2020 - link
Both the M1 and 4800U are drawing more that 15W depending on workload, both settling around 22-24W after initial boost.mdriftmeyer - Friday, November 20, 2020 - link
Zen 4 is out Nov 2021, announced Oct 2021. It's already known. Zen 4 is nearly complete in design back in September. What's coming with Zen 4 is the technologies of Xilinx --Neural Engine: Check, Machine Learning Accelerators: check, DSPs for focused A/D Convert Encode/Decode: Check.People the single biggest news of SV this year isn't ARM+Nvidia or Apple M1 series. It's Xilinx merging to become part of AMD.
The IP, 13k engineers and portfolio of best in breed products by Xilinx [run by former AMD] is massive.
And Apple nor Intel nor Nvidia saw this coming.
Zen 4 APU will be a 5w or less CPU, with specialized add-ons, a massive Infinity Fabric interconnect, RAM not constrained like Apple, 8, 12, 16 CPU cores in dual chiplets and RDNA 3.0 CU GPU.
Fall 2021 will be Zen 4 CPU, APU/RDNA 3.0 and RDNA 3.0 discrete GPUs with CDNA 2.0 M series Compute Processors expanding their footprint into HPC.
You'll see the Zen 4/CDNA 2.0 solutions on El Capitan Fall 2021/Spring 2022. Clearly, to win that $600 million contract AMD showed their plans 12 months ago.
From March 04, 2020 Press Release
AMD technology within El Capitan includes:
Next generation AMD EPYC processors, codenamed “Genoa” featuring the “Zen 4” processor core. These processors will support next generation memory and I/O sub systems for AI and HPC workloads,
Next generation Radeon Instinct GPUs based on a new compute-optimized architecture for workloads including HPC and AI. These GPUs will use the next- generation high bandwidth memory and are designed for optimum deep learning performance,
The 3rd Gen AMD Infinity Architecture, which will provide a high-bandwidth, low latency connection between the four Radeon Instinct GPUs and one AMD EPYC CPU included in each node of El Capitan. As well, the 3rd Gen AMD Infinity Architecture includes unified memory across the CPU and GPU, easing programmer access to accelerated computing,
An enhanced version of the open source ROCm heterogenous programming environment, being developed to tap into the combined performance of AMD CPUs and GPUs, unlocking maximum performance.
“This unprecedented computing capability, powered by advanced CPU and GPU technology from AMD, will sustain America’s position on the global stage in high performance computing and provide an observable example of the commitment of the country to maintaining an unparalleled nuclear deterrent,” said LLNL Lab Director Bill Goldstein. “Today’s news provides a prime example of how government and industry can work together for the benefit of the entire nation.”
Note the emphasis on Genoa Zen 4 processor core, not Genoa Zen 4 CPUs.
Spunjji - Monday, November 23, 2020 - link
@mrdriftmeyer - do you have a source for the 2021 claim? The last roadmap I'm aware of had a Zen 3 refresh on desktop in 2021 (likely on AM5) followed by Zen 4 some time in 2022.Seeing as the rest of your post appears to consist mostly of wild speculation and unsupportable assertions (e.g. the Zen 4 design is already locked in, it's NOT going to contain Xilinx IP) I'm not going to hold my breath.
tempestglen - Tuesday, November 17, 2020 - link
BTW, M1 is a SoC, so please add GPU and RAM power of Zen3 during comparison.RedGreenBlue - Tuesday, November 17, 2020 - link
Benchmarks are benchmarks. I love AMD but in the power envelope the M1 is better. Also consider that this chip maxes out at 3.2Ghz not 4+. It’s just simply that x86-64 is a hinderance to AMD and Intel. That’s the real reason Apple had to switch and knew it with Steve Jobs in 2011. Intel is supposedly working on an x86 replacement. Haven’t heard anything new about it in years. But if they’re still working on it, it was expected in 2020-2022.RedGreenBlue - Tuesday, November 17, 2020 - link
This will also vastly improve their slim profit margins on macs too. Intel was charging such ridiculous prices for mediocre chips it was unbelievable. This is the best business model.