The AMD Ryzen Threadripper 3960X and 3970X Review: 24 and 32 Cores on 7nm
by Dr. Ian Cutress, Andrei Frumusanu & Gavin Bonshor on November 25, 2019 9:05 AM ESTCPU Performance: Rendering Tests
Rendering is often a key target for processor workloads, lending itself to a professional environment. It comes in different formats as well, from 3D rendering through rasterization, such as games, or by ray tracing, and invokes the ability of the software to manage meshes, textures, collisions, aliasing, physics (in animations), and discarding unnecessary work. Most renderers offer CPU code paths, while a few use GPUs and select environments use FPGAs or dedicated ASICs. For big studios however, CPUs are still the hardware of choice.
All of our benchmark results can also be found in our benchmark engine, Bench.
Corona 1.3: Performance Render
An advanced performance based renderer for software such as 3ds Max and Cinema 4D, the Corona benchmark renders a generated scene as a standard under its 1.3 software version. Normally the GUI implementation of the benchmark shows the scene being built, and allows the user to upload the result as a ‘time to complete’.
We got in contact with the developer who gave us a command line version of the benchmark that does a direct output of results. Rather than reporting time, we report the average number of rays per second across six runs, as the performance scaling of a result per unit time is typically visually easier to understand.
The Corona benchmark website can be found at https://corona-renderer.com/benchmark
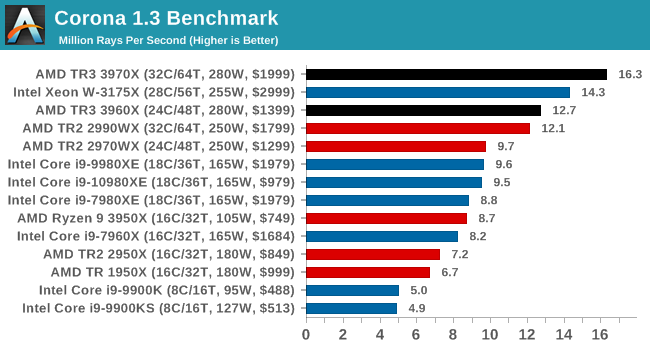
Being fully multithreaded, we see the order here follow core counts. That is except for the 32-core 2990WX sitting behind the 24-core 3960X, which goes to show how much extra performance is in the new TR generation.
Blender 2.79b: 3D Creation Suite
A high profile rendering tool, Blender is open-source allowing for massive amounts of configurability, and is used by a number of high-profile animation studios worldwide. The organization recently released a Blender benchmark package, a couple of weeks after we had narrowed our Blender test for our new suite, however their test can take over an hour. For our results, we run one of the sub-tests in that suite through the command line - a standard ‘bmw27’ scene in CPU only mode, and measure the time to complete the render.
Blender can be downloaded at https://www.blender.org/download/
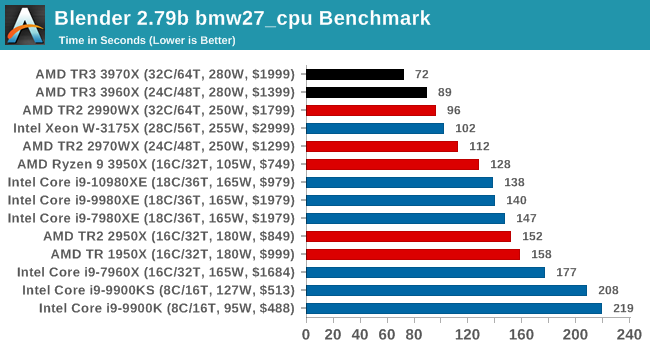
We have new Threadripper records, with the 3970X almost getting to a minute to compute. Intel's nearest takes almost as long, but does only cost half as much. Again, the 3960X puts the 2990WX in its place.
LuxMark v3.1: LuxRender via Different Code Paths
As stated at the top, there are many different ways to process rendering data: CPU, GPU, Accelerator, and others. On top of that, there are many frameworks and APIs in which to program, depending on how the software will be used. LuxMark, a benchmark developed using the LuxRender engine, offers several different scenes and APIs.
In our test, we run the simple ‘Ball’ scene. This scene starts with a rough render and slowly improves the quality over two minutes, giving a final result in what is essentially an average ‘kilorays per second’.
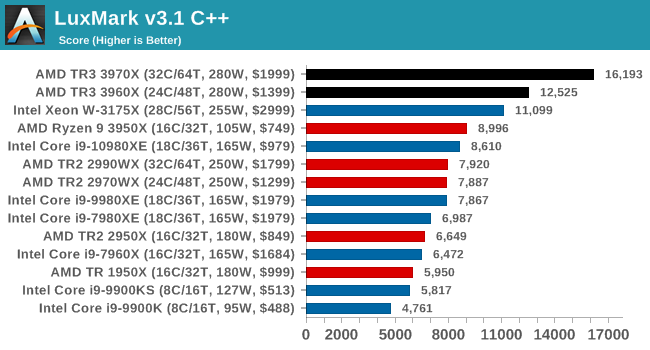
Our LuxMark test again pushes both TR3 processors out in the lead.
POV-Ray 3.7.1: Ray Tracing
The Persistence of Vision ray tracing engine is another well-known benchmarking tool, which was in a state of relative hibernation until AMD released its Zen processors, to which suddenly both Intel and AMD were submitting code to the main branch of the open source project. For our test, we use the built-in benchmark for all-cores, called from the command line.
POV-Ray can be downloaded from http://www.povray.org/
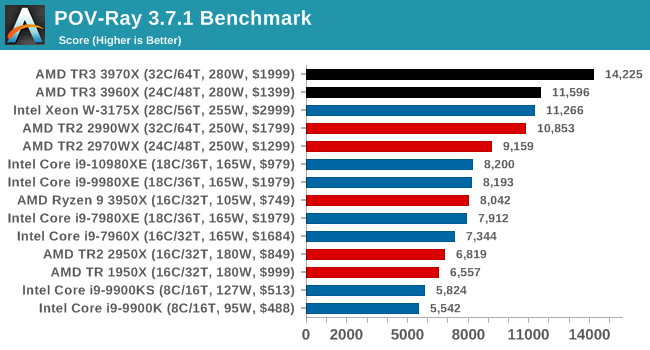
More rendering, more wins for AMD. More losses for the 2990WX, even though on these tests it still beats the 10980XE quite easily.








245 Comments
View All Comments
RSAUser - Tuesday, November 26, 2019 - link
I've only seen the Mozilla benchmarks on LTT, very strange that they're the only ones showing such a workload. I'd be very interested on how these chips handle e.g. large SQL Server DB's and requests, especially with those huge caches.The Mozilla benchmark had near 2x the performance for the 3970X vs the 10980X and serve the home has the ryzen chip at near 30 compiles an hour for the Linux Kernel vs around 16 for Intel.
I'd actually be really interested in the financial market for this TR due to the floating point performance increase. We'll probably be upgrading our servers next year based on current projections, so this has been a really nice development.
Dolda2000 - Monday, November 25, 2019 - link
Why is it that Intel gains so incredibly much more from AVX512 than AMD gains from AVX2?In the 3DPM2 test, the AMD CPUs gain roughly a factor of two in performance, which is exactly what I'd expect given that AVX2 is twice as wide as standard SSE. The Intel CPUs, on the other hand, gain almost a factor of 9, which is more than twice what I'd expect given that AVX512 as four times as wide as SSE.
What causes this? Does AVX512 have some other kind of tricks up its sleeves? Does opmasking benefit 3DPM2?
AnGe85 - Monday, November 25, 2019 - link
The Intel parts are derived from Xeon dies (LCC 10 cores, and HCC up to 18 cores). As such they have two AVX-512-FMA-Units.Zen/+ shows a +70 % increase in performance, Zen2 and the 9900K(S) about +90 % with AVX2 in 3DPM2.1 and the Xeon-based parts reach up to +700 %. Ian has obviously done a good job or at least used a good lib ;-)
Dolda2000 - Monday, November 25, 2019 - link
But Zen 1/2 also has two 256-bit FMAs per core. And Intel also has two SSE units per core as well, so I don't see how that would explain the ratios.yeeeeman - Monday, November 25, 2019 - link
Intel has 512bit unitsDolda2000 - Monday, November 25, 2019 - link
Exactly, which should make it 2× as fast, not 4.5×.abufrejoval - Tuesday, November 26, 2019 - link
The other element of magic is typically halved operand size=twice the data element throughput.Could be FP16 vs FP32 in that code, which means 32 vector elements per 512 bit register and then again of these registers there could be mulitples under SIMD per instruction and clock.
Xyler94 - Tuesday, November 26, 2019 - link
Servethehome also mentioned in their reviews of Epyc Rome Processors, the same basic Zen2 platform that the new TR CPUs are made on, that most programs aren't optimized for AMD's new AVX2 pipes, so the results are lower than they should be. I don't know if that's still the case, but it may be a reason why it's showing such a disparity between the two.Slash3 - Monday, November 25, 2019 - link
Wow.Just wow.
shaolin95 - Monday, November 25, 2019 - link
Why wont yuo enable IGPU for the 9900k on the Premiere test? It will change the performance dramatically.